
Joined October 2024
- Tweets 161
- Following 124
- Followers 1,828
- Likes 421
27 Photos and videos









Pinned Tweet
- 230 training runs
- 1,623 GPU hours (67 B200 days)
- 76 TB of training data
- a 2x faster model
Every paper said it can't be done.
Quantization Aware Distillation made it possible.

20
104
1,199
154,022
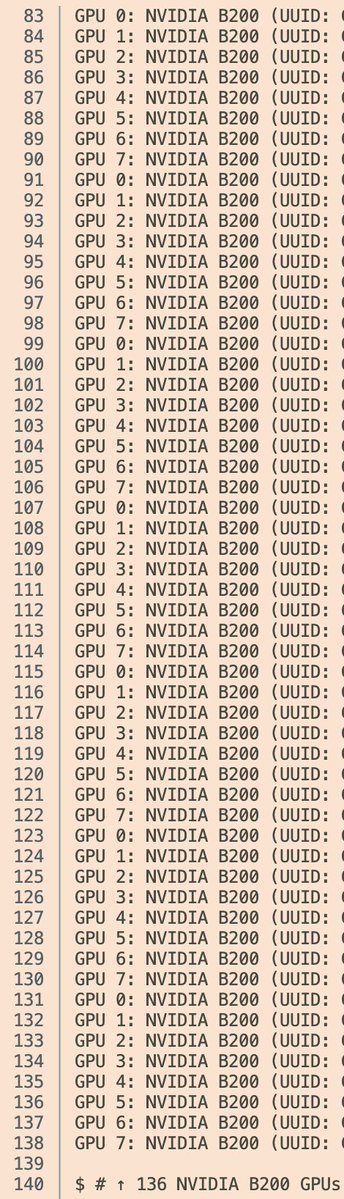
anyways if you work for an inference lab you get 17x8 B200 nodes to try stuff out
...
~1.2 EFLOPS FP8 for an intern

there is no such thing as running out of compute. for the right price someone will sell you compute. it’s an elastic resource like all other markets. when RSI arrives running that program will be so valuable that all clouds will mostly shut down and sell compute to the singularity
34
6
404
50,840
ok we did (grudgingly) go outside while the agents worked



May 31
> drive 4 hours to yosemite
> take one picture to say we did it
> spend the rest of day in the airbnb
> everyone needed to check in on the agents


1
12
2,738

May 31
> drive 4 hours to yosemite
> take one picture to say we did it
> spend the rest of day in the airbnb
> everyone needed to check in on the agents
2
97
15,320
May 29
> don't just optimize intra-step of a generative model
remove the step completely

2
1
24
4,272
May 29
> go to waterloo
> become senior intern
> retire on graduation
1
57
4,216
May 27
if you can't guess the kernel, you're not locked in enough
16
8
310
34,182
May 23
tech bros deriving islam from first principles

i challenge anyone who listens to music for 6 hours a day to quit for a week to:
1) realize it's an addiction
2) realize how much better your thoughts become
19
183
3,118
242,839
Apr 28
this was so fun to work on, i hope you find it useful
tried @baseten for GPU access?
Apr 28

im making a decision to switch to blackwell than hopper since the 5090s are more affordable. i was learning WGMMA and renting h100 was getting too expensive :( what are some affordable options to rent among @vast_ai @modal etc

1
3
1,015
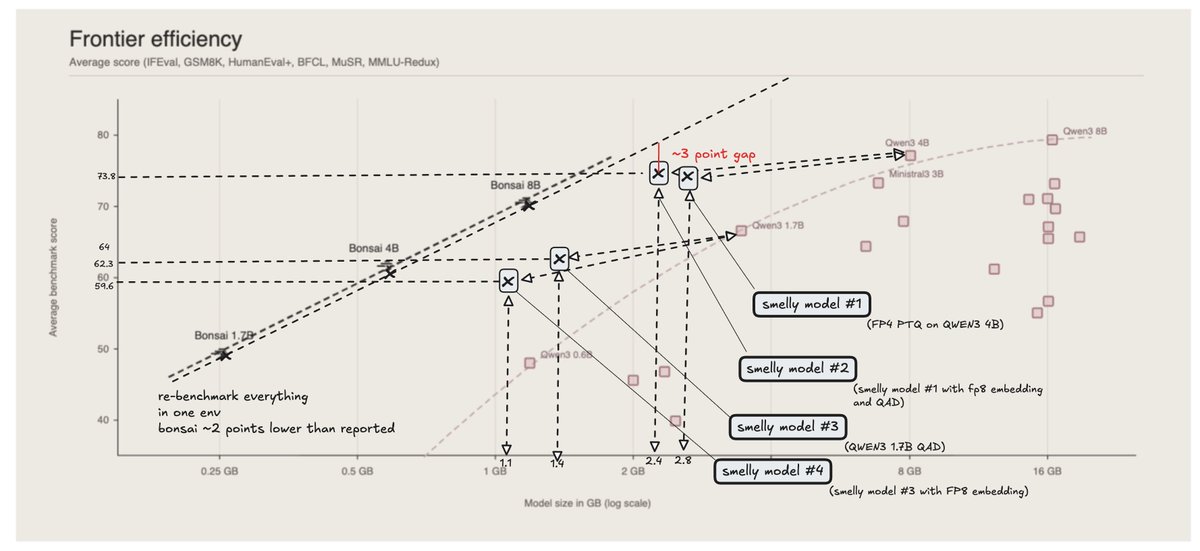
we dug into 1-bit bonsai with @part_harry_
the grand canyon of a gap they showed...
is just THREE (3) points away from normal PTQ
but they already knew that
here's the graph (fixed)

This scatter plot shows the Pareto frontier of intelligence vs. size, defined by models like Qwen3 0.6B, 1.7B, 4B, 8B, and Ministral3 3B.
The 1-bit Bonsai family shifts that frontier dramatically to the left.
This changes the tradeoff itself: models no longer have to be large to be capable.

7
4
100
17,562
Mar 30
on-policy for the student
off-policy for the teacher
monkey input, monkey output

21
3,955
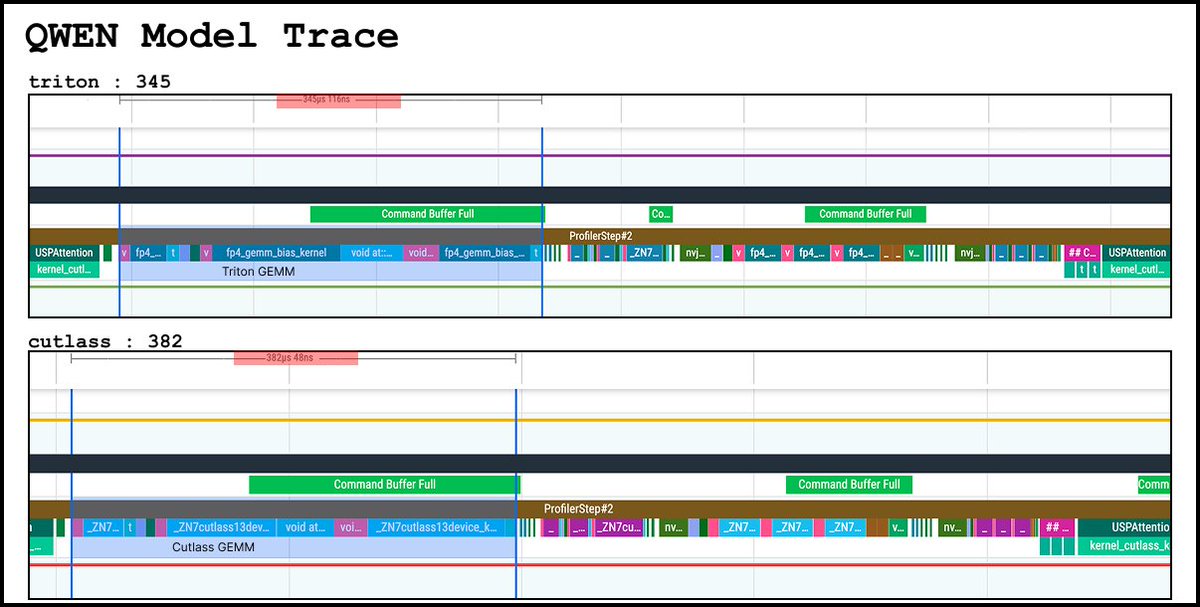
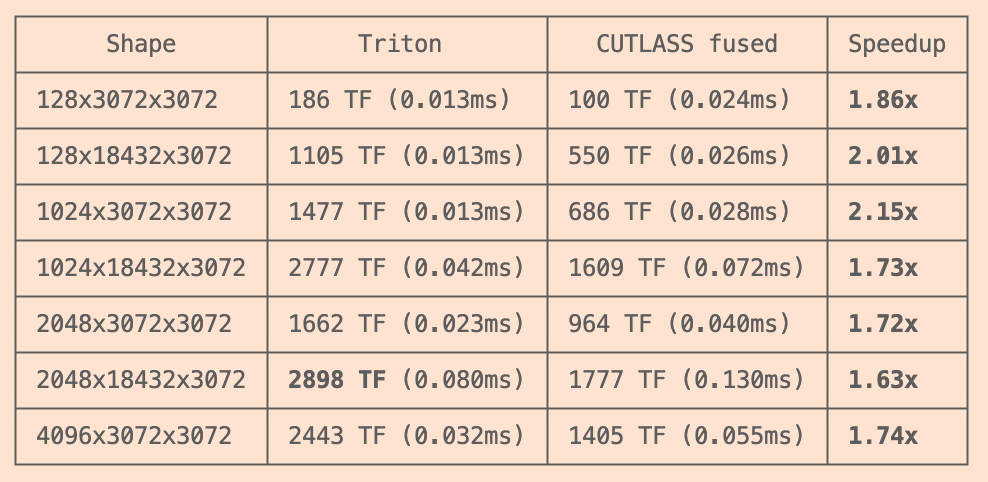
Mar 11
was skeptical but gave it a shot because @karpathy
anyways
2x kernel perf (fp4 matmul)
3 minutes of work (1 prompt)
triton beat cutlass (?!)
Mar 11

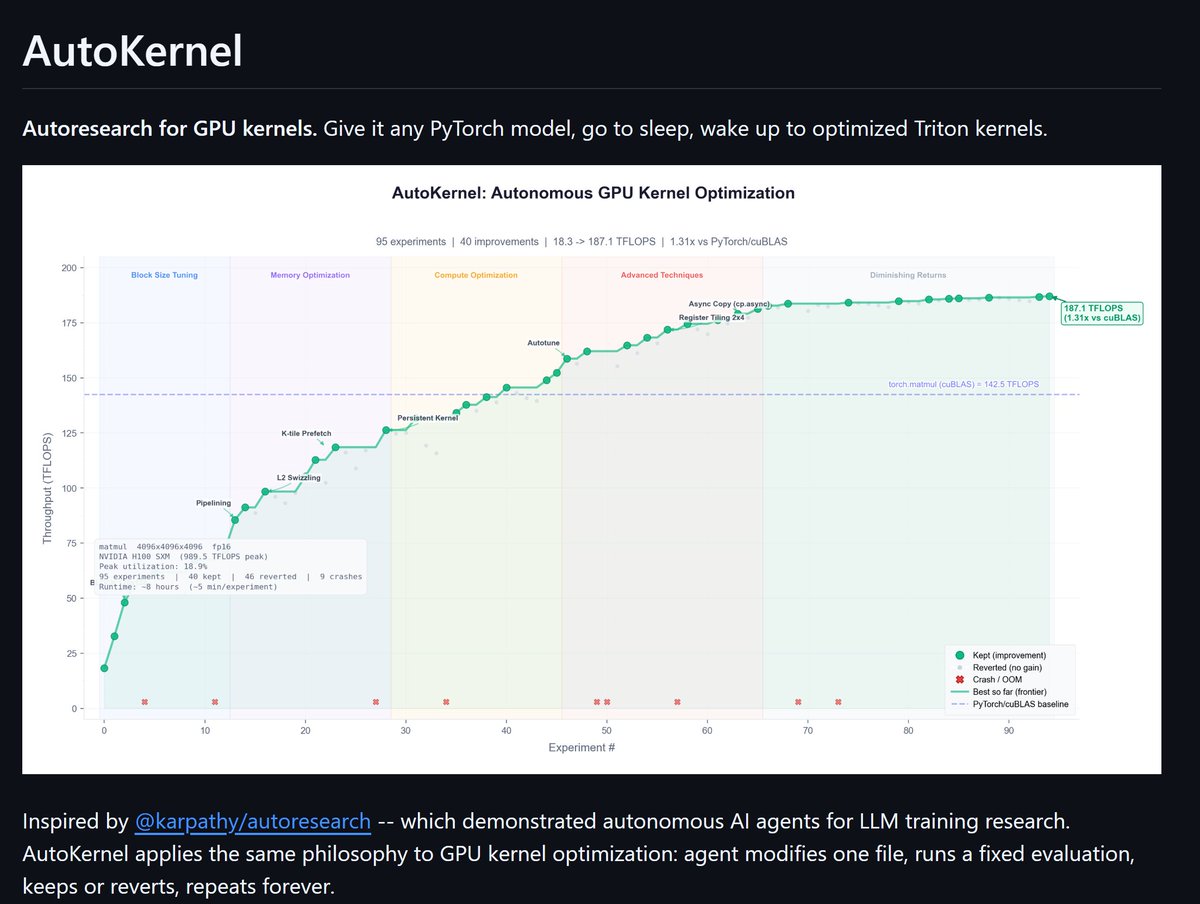
i open-sourced autokernel -- autoresearch for GPU kernels
you give it any pytorch model. it profiles the model, finds the bottleneck kernels, writes triton replacements, and runs experiments overnight. edit one file, benchmark, keep or revert, repeat forever.
same loop as @karpathy autoresearch, applied to kernel optimization
95 experiments. 18 TFLOPS → 187 TFLOPS. 1.31x vs cuBLAS. all autonomous
9 kernel types (matmul, flash attention, fused mlp, layernorm, rmsnorm, softmax, rope, cross entropy, reduce). amdahl's law decides what to optimize next. 5-stage correctness checks before any speedup counts
the agent reads program.md (the "research org code"), edits kernel.py, runs bench.py, and either keeps or reverts. ~40 experiments/hour. ~320 overnight
ships with self-contained GPT-2, LLaMA, and BERT definitions so you don't need the transformers library to get started
github.com/RightNow-AI/autok…
12
12
243
39,939
Mar 12
with cudagraph enabled, the gains are not as dramatic
but triton still technically outperformed the cutlass kernel in production
5
1,204
every year i go through a phase where i re-learn eigenvectors
7
622