
12 Photos and videos
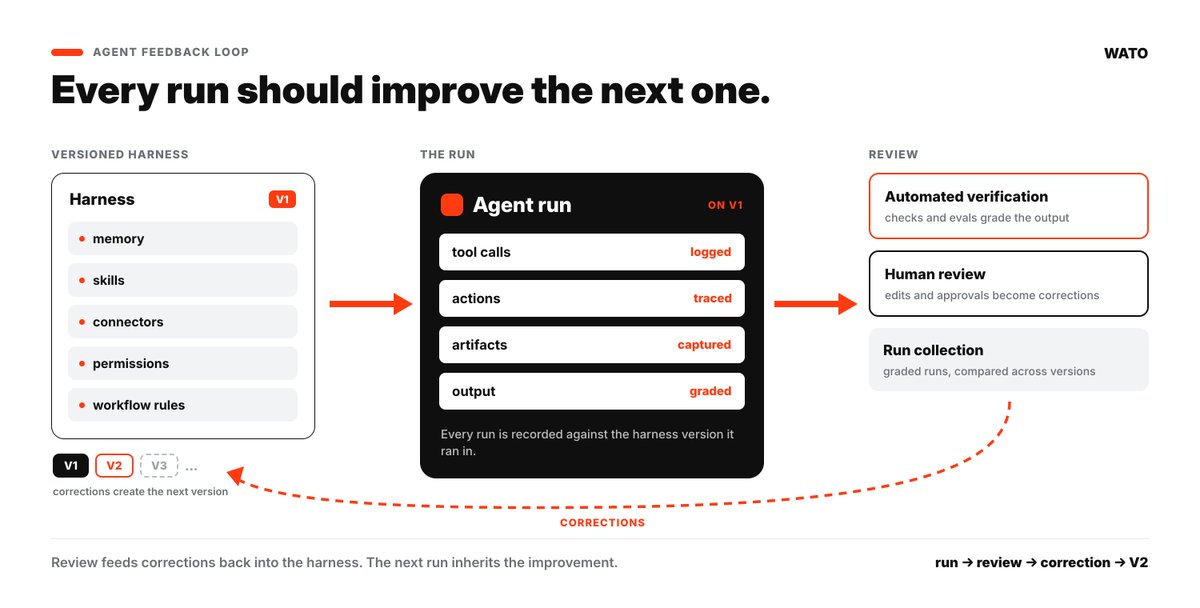









everyone is giving their agents more memory. almost no one is giving them a feedback loop.
an agent with the same context and no feedback repeats its mistakes forever.
the model is the part you can't control. the "harness" around it is the part you can — and tuning it is how agents actually get better: blog.watolabs.com/ai-agents-…
4
80
Agents need scoped context.
The real waste is searching the wrong systems, reading stale docs, and producing output humans have to fix.
Our thoughts on how to make agents more efficient at work:
blog.watolabs.com/ai-agents-…
1
3
108
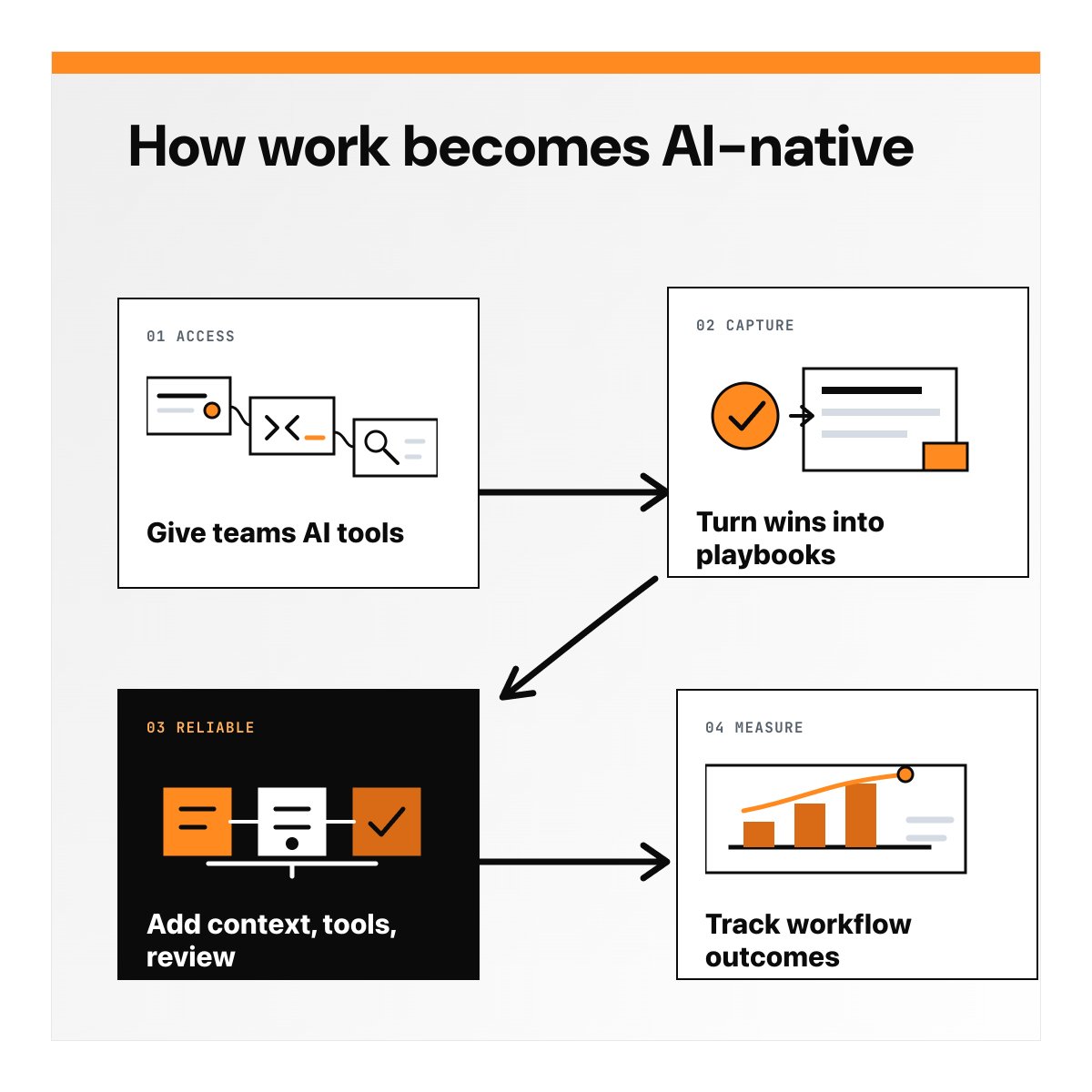
We’re moving past the phase where “AI adoption” just means giving everyone access to more tools.
The next phase is turning the best AI use cases people discover into repeatable workflows the whole company can trust.
That means named workflows, shared context, connectors, permissions, review steps, and measurement.
Wrote more here:
blog.watolabs.com/becoming-a…
1
4
94
I think we’ve all started to realize that AI spend is not the same thing as productivity.
The first wave of AI adoption was about giving teams access to better models, more tools, and more tokens. The next wave is going to be about efficiency: understanding which AI work is actually creating business value, and which work is just adding cost.
How can businesses be best suited for this transition?
Wrote more here:
blog.watolabs.com/ai-outcome…
1
2
8
175,275
kind of what we're doing, so check us out!
Jun 6

I want some kind of LLM workflow tool.
• Ability to manage a set of input files (Markdown or similar), plus other general-purpose context.
• With real-time collaboration. (And maybe some concept of snapshots or VCS integration.)
• And the ability to create/manage a inference workflows and a stored set of prompts.
• Access to general-purpose coding agents (and not just chat models).
• Some concept of compiled outputs/inference results (which ideally can be shared externally).
Many projects have this feeling: "there is all this stuff, which I want to process/compute over in this iterated way, with some build artifacts being important/worth saving." GNU Autotools x Notion or something. Is anyone building this?
1
4
147
Most companies already have memory.
It’s just scattered across Salesforce, Slack, Linear, GitHub, dashboards, docs, spreadsheets, and the people who know where to look.
That’s why “company memory” for AI agents should be structured to help agents navigate this convoluted mess.
Try to create a map:
Write where knowledge lives, what sources to trust, who has access, and which workflows have been reviewed.
Wrote more here:
blog.watolabs.com/company-me…
3
2
10
124,105
shameless plug at watolabs.com
Jun 5

Has anyone created an internal GitHub but for skills and prompts (not code) that can be hosted internally to a company and have non technical contributors?
3
128
check us out at watolabs.com 😎
Jun 3

Wato (@watolabs) is building the collaboration layer for teams working with AI agents: shared knowledge, cloud agents, automations, and permissioned tools across the AI subscriptions companies already use.
Congrats on the launch, @arihanxv & @rahulrejeev!
ycombinator.com/launches/Qet…
1
5
278
Asked Wato one messy sales question:
“What’s going on with BrightCart, why is the renewal at risk, where’s Eng on the fix, and what should I email them?”
It pulled the account status, meeting context, technical blockers, stakeholder guidance, and drafted the follow-up.
This is what happens when company context actually works.
1
1
14
311,468
Wato released the biggest update to artifacts for Claude and Codex.
The flow is usually:
prompt -> MCPs -> data -> HTML/CSS/JS -> static dashboard
Then it becomes a static HTML file, a screenshot, or a Slack link nobody trusts two weeks later.
Wato makes artifacts live: permissioned, versioned, shareable, connected to data, and reusable by agents.
Here's a demo below.
1
3
15
268,383
check out our private beta at: watolabs.com
1
1
5
144
We just built the most scalable company brain.
Institutions are naturally noisy. Wato is built to solve for that.
Most “AI memory” systems are solving the wrong problem. They treat memory as retrieval: put documents in a vector database, search across them, and hope the right context comes back.
But company knowledge does not stay clean on its own. It gets stale, duplicated, contradictory, and hard to trust.
Real memory needs structure:
source of truth
version history
rollback
permissions
exact search
human-readable records
This is where a lot of graph RAG / embedding-first systems break down. They can retrieve plausible context, but they don’t answer the more important questions:
Who said this? Is it still true? Which team owns it? What changed?
At Wato, we think memory should work more like a versioned filesystem. Keep the source as readable Markdown, organized by teams and folders. Then layer search on top.
You still get semantic search, keyword search, and exact search at scale, but the source stays inspectable and editable.
The agent needs to both “remember" and the institution needs to know what it knows, keep it current, and make it safely usable.
3
2
11
404,885
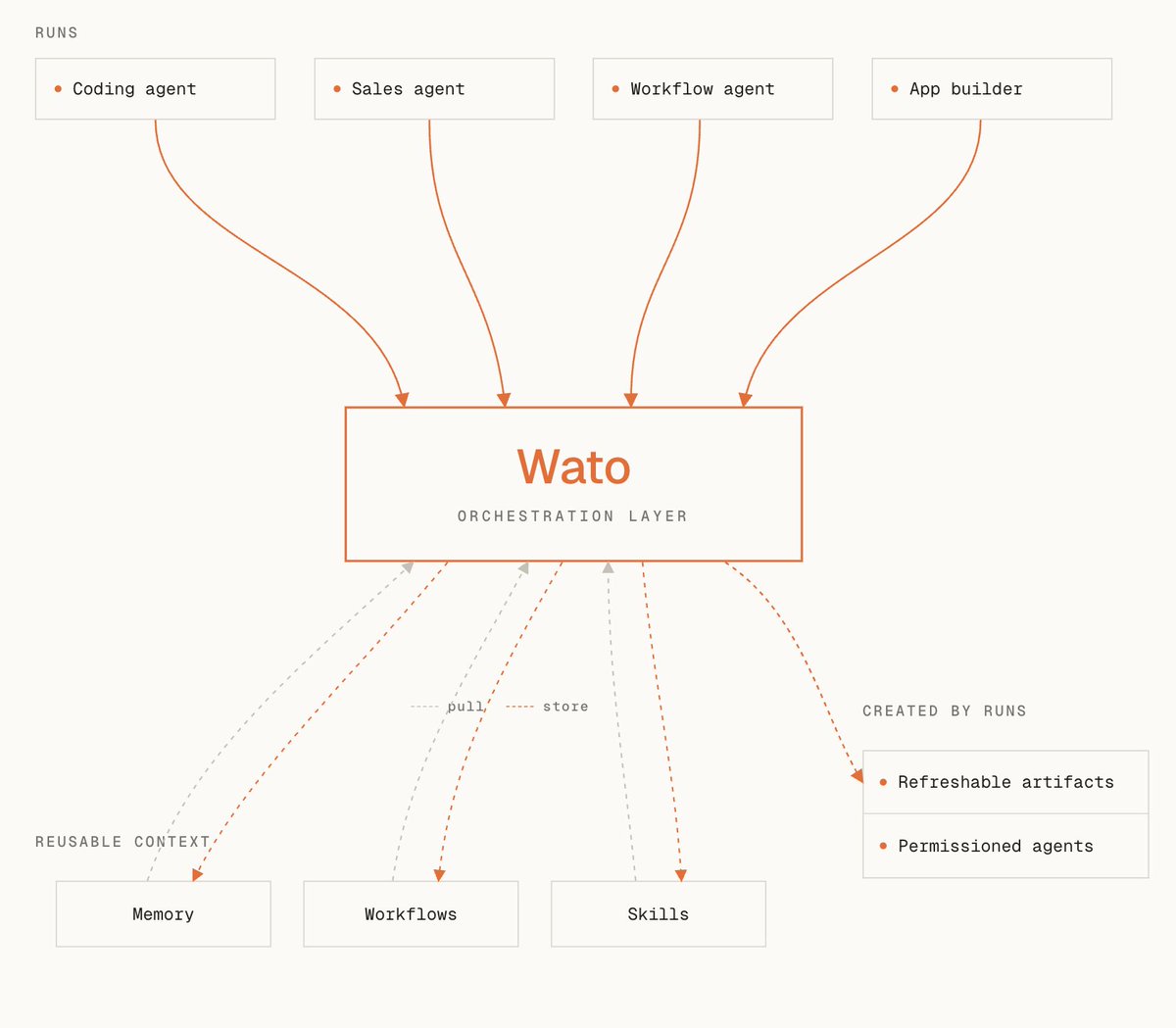
Introducing Wato: shared memory and living artifacts for AI in teams.
Every team building with agents eventually hits the same wall:
The work doesn’t compound.
An agent will solve something useful, then the knowledge disappears.
It found the right workflow. It found which source is trusted. It figured out the weird caveat. It built the useful dashboard. It wrote the playbook.
Then the next agent starts from zero.
So we built Wato. So your entire team can go from 0 -> 100
Wato lets agents read from team memory, push reusable knowledge back into memory, share skills across teams, and create refreshable artifacts like live dashboards.
Every useful agent run should make the next one better.
Private beta is open. Link in comments.
3
2
38
1,614,181
Early access @ watolabs.com
If you're working in credit, insurance, research, etc. Send us a dm!
2
194