
Mathematician, computer scientist and humanist looking for truth. For this journey, benevolent and scientifically interested people are always welcome.
Joined May 2018
- Tweets 3,034
- Following 517
- Followers 219
- Likes 16,377
1,645 Photos and videos
















Pinned Tweet

"May your choices reflect your hopes and not your fears"
1
7
SubstProf weakmath (@weakmath@algebra.chat) retweeted

Jun 7
This may be a controversial take, but I think it needs to be said: the gap between computer vision research in academia and industry is widening with every conference.
A huge fraction of @CVPR papers—especially those that boil down to "we tweaked/fine-tuned/RL'ed large-scale model X to improve on task Y"—will become obsolete with the next model release. That's not where academia creates lasting value. PIs should adapt much faster to this changing reality.
Academia should focus on fundamentally new ideas, new problem formulations, explaining emergent phenomenology, or uncovering blind spots that industry can later solve with scale, compute, and data.
37
115
1,125
94,382
This train left station a long time ago... I bet less than 1 in 20 people using the word can actually tell you what a tensor is.
Apr 18

Can people please stop calling arbitrary multidimensional arrays “tensors”?
32
We're hiring! PostDoc (3 yrs, full-time) in modern AI methods at U Hildesheim – 2/3 research on deep learning, neurosymbolic reas., time series, generative & explainable AI at ISMLL, 1/3 AI consulting for researchers across disciplines.
Deadline: May 3
s.gwdg.de/53TmQv
151
On average one out of three ML researchers I talk to knows about JL. One out of 10 can actually say something about the proof. One out of 20 can tell me a correct definition of VC dimension. Maybe I talk to the wrong people at conferences...
Mar 28

The Google turboquant paper is making ML folks in this decade discover JL lemma and interact with math folks (which is cool). It appears more cool and mysterious if you do not read ML papers from the 90s and early 2000s :)



34
SubstProf weakmath (@weakmath@algebra.chat) retweeted

The first time you hear about the JL lemma, it will seem too good to be true. And it is, kind of, I'll explain. The idea is: if you have points in large d-dimensional space, a RANDOM projection to much smaller k-dim subspace will be "nearly optimal" "in the general case." Or, more specifically: with high probability, the pairwise distances between points are preserved, given a couple other requirements around d and k.
So why don't we just use random projections instead of carefully-constructed ones all the time? This is the most common misunderstanding of the JL lemma, and the one thing to really understand about it: in many (most?) datasets that are meaningful to humans, you actually CAN do better with something like maybe PCA. If your dataset is pathological, e.g., the points all lie on a plane even though it's technically in 3 dimensions, then clearly some planes you project onto will be better than others. The JL lemma does not apply to 2 and 3 dimensions, but you can imagine this would be true in large numbers of dimensions too. (See screenshot 1, i hope you like it because i made it myself lol.)
If you know just those facts, you will be pretty well-prepared to answer most questions about its use. Most of the papers Delip mentions do presuppose that you know this. At least when I was a student, I found this to be non-obvious.

Mar 28
The Google turboquant paper is making ML folks in this decade discover JL lemma and interact with math folks (which is cool). It appears more cool and mysterious if you do not read ML papers from the 90s and early 2000s :)
8
53
630
82,387
SubstProf weakmath (@weakmath@algebra.chat) retweeted

Jan 30
TGDK announces a Special Issue on "Neuro-Symbolic Modeling for Human-Centric AI" with submissions due on June 30, 2026. We welcome research, survey and resource articles at the intersection of graph-structured data / knowledge and human-centric AI.
See: url-shortener.me/A3Q5
1
4
141
SubstProf weakmath (@weakmath@algebra.chat) retweeted

When KAN was released, I said it was one of the truly transformative technologies
Predictably, the “sceptics” arrived.
Mostly math-devoid Kagglers, plus a few loud voices confusing leaderboard tricks with scientific progress.
Fast-forward less than two years
KAN has now surpassed the only genuinely transformative time-series models of the last two decades
N-BEATS and NHIT.
Let that sink in.
And yes — before someone asks — KAN has also smashed transformers in this domain.
Not by vibes. By results. By structure. By empirical evidence.
Paper for those who actually read:
[arxiv.org/pdf/2601.18837](arxiv.org/pdf/2601.18837)
Moral of the story:
A Kaggle badge is not a certificate of mathematical understanding.
It is not proof of scientific judgment.
And it certainly isn’t a crystal ball for identifying foundational ideas.
Real progress doesn’t come from leaderboard folklore.
It comes from theory, structure, and results that survive contact with reality
History keeps repeating this lesson.
Some people still haven’t learned it.

2
17
204
15,662
SubstProf weakmath (@weakmath@algebra.chat) retweeted

13 Nov 2025
I am an AC for ICLR 2026. One of the papers in my batch was just withdrawn. The authors wrote a brief response, explaining why the reviewers failed at their job. I agree with most of their comments. The authors gave up. They are fed up. Just like many of us. I understand. We pretend the emperor has clothes, but he is naked.
Here is the final part of their withdrawal notice. I took the liberty to make it public, to highlight that what we are doing with AI conference reviews these last few years is, basically, madness.
---
Comment: We thank the reviewers for their time.
However, upon reading the reviews for our paper, it became immediately apparent that the four "reject" ratings are not based on good-faith academic disagreement, but on a critical failure to read the submitted paper.
The reviews are rife with demonstrably false claims that are directly contradicted by the text. The core justifications for rejection rely on asserting that key components are "missing" when they are explicitly detailed in the manuscript. Some specific examples are (and many are even fake claims).
Claim: Harder tasks like GSM8K are missing.
Fact: GSM8K results are in many tables, like Table 2 (Section 4.2) and Appendix G.
Claim: The method does not use per-layer ranks.
Fact: This is the entire point of our method. The reviewer clearly mistook our method for the baselines. (Section 2, Table 1).
Claim: The GP kernel is not specified.
Fact: It is specified in Appendix E (Table 6).
Claim: There is no ablation of the method's three stages.
Fact: Section 4.4 ("Ablation Study") and Appendix J are dedicated to this.
Reviewers have a fundamental responsibility to read and evaluate the work they are assigned. The nature of these errors is so fundamental, so systemic in overlooking explicit content, that it goes far beyond what "limited time" or "oversight" can explain. This work has gone through several rounds of revision over the last year. In earlier submissions, the paper usually received borderline or weak-accept scores.
Numerous signs strongly suggest that some reviewers are relying entirely on AI tools to automatically generate peer reviews, rather than fulfilling their fundamental responsibility of personally reading and evaluating manuscripts.
We strongly protest this.
This is a gross disrespect to the authors. It is a flagrant desecration of the reviewer's sacred duty. It fundamentally undermines the integrity of the entire peer-review process.
Given that the reviews are not based on the actual content of our paper, we have decided to withdraw the submission.
We leave this comment so that future readers of the OpenReview page are aware that the items described as "missing" are already present in the submitted manuscript. These negative reviews for this submission are factually unsound and do not reflect the content of the paper. We cannot and will not accept an assessment that is not based on the work we actually submitted.
33
203
1,500
150,310
The baggage claim game in #FRA, where time is just an illusion... expected in 10 minutes for about 10 minutes 🤣
2
43




SubstProf weakmath (@weakmath@algebra.chat) retweeted

3 Oct 2025
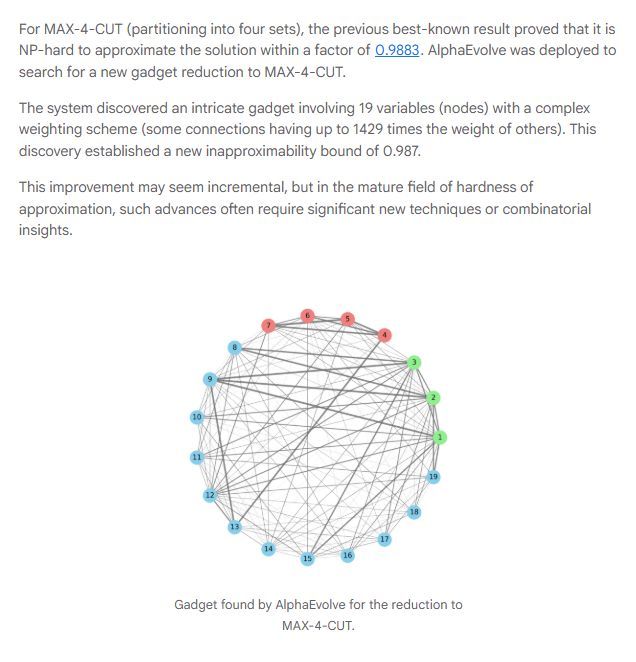
This sort of thing is interesting and nice, but calling it “new theorems” is slightly misleading when we’re talking about improved bounds discovered through a big search.

AlphaEvolve Just Helped Prove New Theorems in Complexity Theory
Google DeepMind's AlphaEvolve just made real breakthroughs in theoretical computer science.
Instead of generating full proofs, it discovered new combinatorial structures that plug into existing proof frameworks, leading to verified, publishable theorems in complexity theory.
The team improved the inapproximability bound for MAX-4-CUT and found massive Ramanujan graphs never seen before, all with provable correctness.


11
60
585
57,708
🤣🤣🤣 Why not do both? One paper goes to #TMLR and the next goes to the water heater process , I am sorry, I mean to the A* conference russian roulette.
21 Sep 2025

Reassuring to hear it from you. We are still playing the ML conference Russian roulette.
5
1,582
18 Sep 2025


47