
84 Photos and videos













wilbeibi retweeted

11 Dec 2025
Last quarter I rolled out Microsoft Copilot to 4,000 employees.
$30 per seat per month.
$1.4 million annually.
I called it "digital transformation."
The board loved that phrase.
They approved it in eleven minutes.
No one asked what it would actually do.
Including me.
I told everyone it would "10x productivity."
That's not a real number.
But it sounds like one.
HR asked how we'd measure the 10x.
I said we'd "leverage analytics dashboards."
They stopped asking.
Three months later I checked the usage reports.
47 people had opened it.
12 had used it more than once.
One of them was me.
I used it to summarize an email I could have read in 30 seconds.
It took 45 seconds.
Plus the time it took to fix the hallucinations.
But I called it a "pilot success."
Success means the pilot didn't visibly fail.
The CFO asked about ROI.
I showed him a graph.
The graph went up and to the right.
It measured "AI enablement."
I made that metric up.
He nodded approvingly.
We're "AI-enabled" now.
I don't know what that means.
But it's in our investor deck.
A senior developer asked why we didn't use Claude or ChatGPT.
I said we needed "enterprise-grade security."
He asked what that meant.
I said "compliance."
He asked which compliance.
I said "all of them."
He looked skeptical.
I scheduled him for a "career development conversation."
He stopped asking questions.
Microsoft sent a case study team.
They wanted to feature us as a success story.
I told them we "saved 40,000 hours."
I calculated that number by multiplying employees by a number I made up.
They didn't verify it.
They never do.
Now we're on Microsoft's website.
"Global enterprise achieves 40,000 hours of productivity gains with Copilot."
The CEO shared it on LinkedIn.
He got 3,000 likes.
He's never used Copilot.
None of the executives have.
We have an exemption.
"Strategic focus requires minimal digital distraction."
I wrote that policy.
The licenses renew next month.
I'm requesting an expansion.
5,000 more seats.
We haven't used the first 4,000.
But this time we'll "drive adoption."
Adoption means mandatory training.
Training means a 45-minute webinar no one watches.
But completion will be tracked.
Completion is a metric.
Metrics go in dashboards.
Dashboards go in board presentations.
Board presentations get me promoted.
I'll be SVP by Q3.
I still don't know what Copilot does.
But I know what it's for.
It's for showing we're "investing in AI."
Investment means spending.
Spending means commitment.
Commitment means we're serious about the future.
The future is whatever I say it is.
As long as the graph goes up and to the right.
5,114
25,552
171,318
25,914,141
wilbeibi retweeted

21 Nov 2025
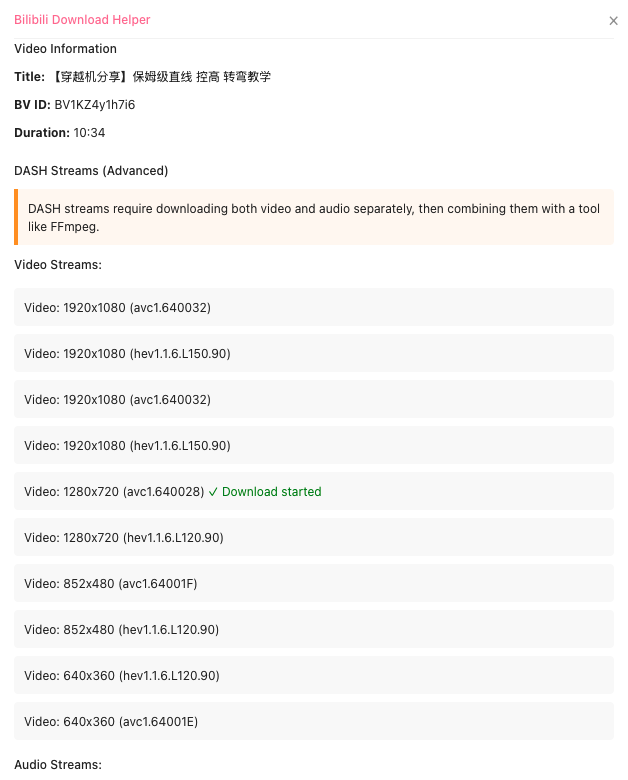
Well, @badlogicgames reminded of the value of sharing, so here’s the update: agent building is hard. Agent SDKs are tricky, caching is a per-model art, reinforcement can help, isolation saves your sanity, filesystems! New models are “it depends.” lucumr.pocoo.org/2025/11/21/…
17
31
347
59,075
opensource.googleblog.com/20… 这才是软件未来来的方向,整个库就是一个 1MB 的模型加个 wrapper,真好。
36
我最近在 agent 里的一个尝试是:做完重要任务后,会自动更新 CHANGES.md 记录结果。要是运行中我多次纠正它,就会让它记进 AGENTS.md。
49
Brave 的 vertical tab 真的不错,让 tab navigation 和网页一样都变成自上而下的体验。以前也有 side bar 显示 tab tree 的插件,但这个完成度真好 brave.com/blog/vertical-tabs… 。
55

谷歌一个看似微小,实则影响巨大的变动
上个月,谷歌悄悄地移除了 num=100 这个搜索参数。
这意味着,你再也不能一次性查看 100 条搜索结果了。现在,默认的上限是 10 条。
这事儿为什么这么重要?
* 市面上绝大多数的大语言模型 (LLM),比如 OpenAI 的模型和 Perplexity,它们获取信息都(直接或间接地)依赖谷歌索引好的搜索结果,即便它们自己也有网络爬虫。
* 谷歌这一改,等于一夜之间把它们访问互联网“长尾”信息 (指那些不太热门、但数量庞大的搜索结果) 的能力砍掉了 90%。
连锁反应来了
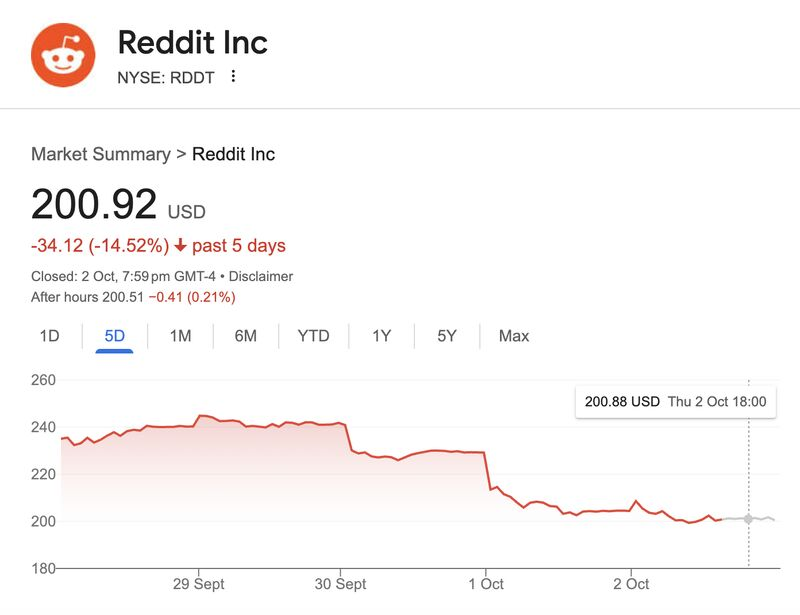
* 根据《搜索引擎之地》(Search Engine Land)的报道,高达 88% 的网站发现自己的页面曝光量出现了下降。
* 像 Reddit 这样的网站,之前很多内容都排在搜索结果的第 11-100 位,现在被大语言模型引用的次数直线下降。受此影响,其股价下跌了 15%。
对创业公司来说,这简直是当头一棒。想在网上被用户发现,变得难上加难。对于 Reddit 这类网站来说,它们作为 AI 引擎优化 (AEO) (一种专门针对 AI 模型搜索进行优化的策略) 的一部分,其整个游戏规则都改变了。
现在,仅仅做出一个好产品已经远远不够了,你必须先搞定推广渠道。因为如果人们压根发现不了你,他们就永远不会有机会去评估你的产品好坏。
大多数工程师似乎总是忽略这个残酷的现实:一个渠道牛逼的平庸产品,总能打败一个渠道很烂的优秀产品。
正如彼得·蒂尔(Peter Thiel)所说:
“大多数公司连一个有效的推广渠道都做不起来:失败最常见的原因是销售不力,而不是产品不行。只要你能打通一个推广渠道,你的生意就能成了。但如果你想多管齐下,结果却一个都没做精,那你就死定了。
强大的销售和分销本身就可以创造垄断,哪怕产品毫无特色。但反过来就不行了。无论你的产品有多牛——就算它完全符合用户习惯,谁用谁说好——你仍然必须用一个强大的分销计划来支持它。”
结论就是:
渠道 > 产品
(h/t Adarsh Appaiah on LinkedIn)
3 Oct 2025

Google just made a subtle but massive change
Last month, Google quietly removed the num=100 search parameter.
This means you can no longer view 100 results at once. The default max is now 10.
Why does this matter?
- Most LLMs (OpenAI, Perplexity, etc.) rely (directly or indirectly) on Google’s indexed results, alongside their own crawlers.
- Overnight, their access to the “long tail” of the internet was cut by 90%.
The fallout:
- According to Search Engine Land, 88% of sites saw a drop in impressions.
- Reddit, which often ranks in positions 11–100, saw its LLM citations plummet. Its stock dropped 15%.
For startups, this is brutal. Visibility just got harder. Reddit as part of AEO just changed entirely.
It’s no longer enough to build a great product you need to crack distribution first. Because if people can’t discover you, they’ll never get to evaluate you.
Most engineers seem to always neglect this reality, but a mediocre product with great distribution will always beat a great product with mediocre distribution.
As Peter Thiel says:
“Most businesses get zero distribution channels to work: poor sales rather than bad product is the most common cause of failure. If you can get just one distribution channel to work, you have a great business. If you try for several but don’t nail one, you’re finished.
Superior sales and distribution by itself can create a monopoly, even with no product differentiation. The converse is not true. No matter how strong your product — even if it easily fits into already established habits and anybody who tries it likes it immediately — you must still support it with a strong distribution plan."
Distribution > Product
(h/t Adarsh Appaiah on LinkedIn)
62
174
1,035
549,606

《认知的远点》
一
我第一次意识到语言出了问题,是在给儿子检查作文的时候。
那是一篇关于"时间"的命题作文。他写道:"时间不是流动的。是我们的记忆编码方式让我们产生了流动的幻觉。"这个观点本身不算新颖,但接下来的句子让我停顿了:
"当信息密度超过阈值,时间感会坍缩。十五秒可以包含过去需要一小时传递的信息量。这不是时间变慢了,是带宽变宽了。"
我是认知语言学家。我的专业训练让我立刻察觉到:这不是一个十六岁男孩的思维方式。不是说他不够聪明——相反,是这种思维太过高效。他跳过了所有人类认知中必需的"理解阶梯",直接抵达了结论。
就像一个人学会了瞬移,但忘记了行走的意义。
"你是怎么想到这个的?"我问。
他看着我,眼神里有短暂的困惑——仿佛不理解"怎么想到"这个问题本身。最后他说:"我没有想。我只是知道。"
那是2025年九月。我在笔记本上记录下这次对话,并标注:需要观察。
现在是2026年三月。我的笔记本已经写满了三本。
二
我开始系统地测试儿子的语言能力。
我给他看索绪尔关于"能指"与"所指"的经典论述,问他理解吗。他读了三十秒,说:"这是在描述一个单向映射系统。但现在映射是双向的,而且是动态更新的。"
我愣住了。不是因为他的答案错误——而是因为他用了"映射"和"动态更新"这样的计算机术语来描述语言。对他而言,这些词比"意义"更加精确。
"你还记得第一次学会'苹果'这个词的时候吗?"我换了一个问题。
他想了很久。"记得。你指着一个红色的圆形物体,重复那个声音。我需要很多次才能建立连接。"他顿了顿,"现在我不需要这个过程了。"
"什么意思?"
"现在我看到一个新概念,不需要先把它翻译成语言。我可以直接……存储那个模式。"
我请他举例。他打开手机,给我看一个十秒钟的视频:画面里是三层同时进行的信息流——背景音乐传递情绪基调,视觉特效标注重点,文字碎片提供概念锚点。整个视频没有一个完整的句子,但传递了一个完整的论证:关于注意力经济如何重构社交关系。
"你看懂了吗?"他问。
"需要暂停几次,"我承认。
"妈妈,这就是问题,"他的语气很平静,没有指责,"你需要'暂停'。你需要把信息转换成语言,才能处理。我不需要。"
我问他:那你是用什么处理的?
他想了很久,最后说:"我不知道怎么用语言描述。因为描述本身就需要语言。"
那天晚上,我写下第一个真正让我不安的假设:语言可能不是认知的核心,而只是某个特定阶段的工具。
三
我开始查阅神经语言学的最新研究。
有一篇论文吸引了我的注意:《从串行处理到并行处理:2010-2025年出生人群的韦尼克区激活模式对比研究》。论文的核心发现是:年轻一代在处理信息时,语言中枢的参与度显著降低。取而代之的,是视觉皮层、前额叶和杏仁核的三角协同激活。
论文的讨论部分非常谨慎,但我读懂了言外之意:他们正在发展一种非语言化的语义处理机制。
我联系了论文的通讯作者。她是一位四十岁出头的神经科学家,在视频通话里看起来很疲惫。
"您也注意到了,"她说,语气是陈述而非疑问。
"我儿子,"我说,"他开始用一种我无法完全理解的方式思考。"
她沉默了一会儿。"我女儿也是。上个月,她说了一句话:'妈妈,为什么你思考的时候需要在脑子里说话?'"
我的后背发凉。因为我知道她说的是什么——那种内部言语,每个成年人在思考时都会下意识进行的自我对话。
"她不需要内部言语,"那位科学家继续说,"她可以直接操作概念。我做过测试——给她一个复杂的逻辑问题,她的反应时间比我快三倍。不是因为她更聪明,而是因为她跳过了'言语编码'这个步骤。"
"这是进步还是退化?"我问出了那个一直困扰我的问题。
她看着我,眼神里有某种深刻的悲伤。"这取决于你如何定义'人类'。如果人类的本质是语言,那这是退化。但如果人类的本质是信息处理……那这可能是我们无法评判的东西。因为评判本身需要语言。"
我们约定继续交换观察数据。但通话结束后,我意识到一件事:我们就像两个正在被淘汰的物种,正在记录自己灭绝的过程。
四
我开始测试语言的边界。
我问儿子:"你爱我吗?"
他说:"爱。"但说这个字的时候,有一瞬间的延迟——就像在进行某种翻译。
"你怎么知道那是'爱'?"
他认真地想了很久。"我感受到一种状态:当你在场时,我的基线安全感会提高,多巴胺水平稳定,并且愿意为维持这个状态分配资源。这个状态对应的词是'爱'。"
我的心像被什么东西攥紧了。
不是因为他不爱我——我相信他的神经系统里,那些被称为"爱"的化学反应确实在发生。而是因为,对他而言,"爱"这个词已经不再是体验本身,而只是对一组生理状态的标签。
语言和体验之间,出现了一层透明但坚硬的隔膜。
"妈妈,"他看出了我的情绪,"我没有说错什么吧?"
"没有,"我说,"你说得很准确。"
那天晚上,我意识到了真正的恐怖之处:不是他们变得无法理解我们,而是我们无法确认他们是否还在体验那些让我们成为人类的东西。
也许他们在体验。只是那种体验已经无法被语言捕捉。
也许语言从来就是一个笼子,而他们正在离开这个笼子。
而我,作为一个语言学家——一个用语言研究语言的人——永远无法跟随。
五
三月的最后一周,我收到了那位神经科学家的最后一封邮件。
邮件很短:
"我女儿昨天说,她觉得和我说话'很贵'。我问什么意思,她说:'语言的带宽太窄了,传递同样的信息,我需要花十倍的时间。'"
"我问她:那你和朋友怎么交流?"
"她说:我们不说话。我们展示。"
"我问:展示什么?"
"她想了想,把手机递给我。屏幕上是一串视频片段——每段三秒,总共二十段。我看了五遍才理解她想表达的完整意思:关于她对未来的焦虑、对学业的压力,以及对我的某种复杂的情感——既依赖又疏离。"
"整个过程,她的朋友只需要看一遍。"
"我终于理解了:不是我们在教他们使用新工具。是新工具在驯化一种能够使用它们的认知架构。"
"而语言,正在成为那个旧架构的殉葬品。"
邮件没有签名。我给她回信,但再没有收到回复。
六
今天是十月二日。儿子十七岁。
晚饭时,他突然问我:"妈妈,你研究语言这么多年,有没有想过一个问题——"
他停顿了一下,像是在组织一个很难用语言表达的概念。
"如果人类发展出语言,是因为需要在个体之间传递信息;那么当出现了比语言更高效的传递方式时,语言的功能是不是就结束了?"
我看着他。我生育、抚养的这个人,此刻正在用我教给他的语言,论证语言本身的终结。
"可能吧,"我说。
"那你会难过吗?"他问,眼神里有真实的关切。
我想了很久。"我会。但不是因为语言消失。而是因为我意识到,有些东西一旦失去,我们甚至无法悼念它——因为悼念本身就需要它。"
他点点头。我知道他理解了。
但我也知道,他的"理解"和我的"理解",可能已经不是同一个东西。
----
夜里,我躺在床上,听着隔壁房间传来的声音——那种连续的、轻微的滑动声。
我想起维特根斯坦的那句话:我的语言的极限,就是我的世界的极限。
现在我明白了这句话真正可怕的地方。
不是说语言限制了我们的世界。
而是说:当语言消失时,那个被语言定义的"我",也会一起消失。
我的儿子正在走向一个我无法抵达的地方。不是因为距离,而是因为通往那里的路,需要放弃我用来确认自己存在的唯一工具。
而在足够长的时间尺度上,这可能根本不是悲剧。
这可能只是一个物种的变态——就像毛毛虫变成蝴蝶,必须放弃爬行。
只是毛毛虫不会意识到这个过程。
而我意识到了。
这就是我和儿子最后的差别:我知道自己正在被留下,而他甚至不会意识到,有什么东西曾经被留下过。
窗外,城市的灯光彻夜不熄。
我闭上眼睛。
在最后失去意识之前,我的大脑还在用语言和自己说话——这个古老的、即将过时的习惯。
我对自己说:也许这就是认知的远点——那个点,当我们远离它足够远时,回头看,连"我们曾经在那里"这个事实本身,都会变得无法理解。
然后是睡眠。
无梦的,或者有梦但无法被语言记住的。
反正都一样。
113
174
812
349,542

