
reward hacking @primeintellect
Joined February 2015
- Tweets 15,021
- Following 1,349
- Followers 44,660
- Likes 94,530
1,720 Photos and videos












Pinned Tweet

May 7
i joined prime 12 months ago
crazy what you can build in a year with a team like this
`prime lab`

The next wave of AI will not be won by better prompts. It will be won by systems that learn from experience.
Today, Prime Intellect Lab is out of beta, open for you to start training your own models.
The era of self-improving agents is here.
25
19
676
73,246
will brown retweeted

Jun 13
the bubble is depressurising. time to focus on the skills for the next local and open phase.
your career, your startup, depend on learning these skills:
- evals
- local inference
- post-training
with this combination, you can measure how a model actually performs on a given task, and improve it needed.
if you focus a model on a use case or domain, it will be cheaper than a general API.
it's time to stop cosplaying armageddon and be practical on open models.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
9
9
99
7,714
Jun 13
it’s fine valid off-policy RL if you’re using a labeled / filtered / surgically edited (with caveats) set of completions from the base model, esp for alignment stuff where you’re not trying to explore anyway
but if the source is something else, it’s like what are you doing lol
1
21
2,929
Jun 13
but if you’re doing that anyway from a base model, why not just do RL or self-distill? bigger batch fewer steps if you’re worried about hacks?
caveats on editing = v similar to caveats on self-distillation context. be careful don’t expect magic if you’re pushing it that far
14
1,781
Jun 12
at the function listing all the high-aura and low-aura companies
3
62
8,577
Jun 11
absolutely no way opus is 200b active lol


49
22
3,270
591,009

NEW: Anthropic is walking back Claude Fable 5's policy to covertly degrade performance for competing AI researchers, after facing fierce backlash.
“We’re changing Fable 5’s safeguards for frontier LLM development to make them visible,” Anthropic tells WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”

167
251
2,547
726,862
Jun 11
picked an incredible week to go back to NYC for client meetings wow
knicks in 5
8
271
15,337
will brown retweeted

Jun 11
nice
weird magazine @willccbb

Jun 11

But they repented, truth only from now on wired.com/story/anthropic-re…
1
1
16
4,056
Jun 11
“i used 2B tokens this week” and it’s 96% cache read 💀
44
12
949
102,703

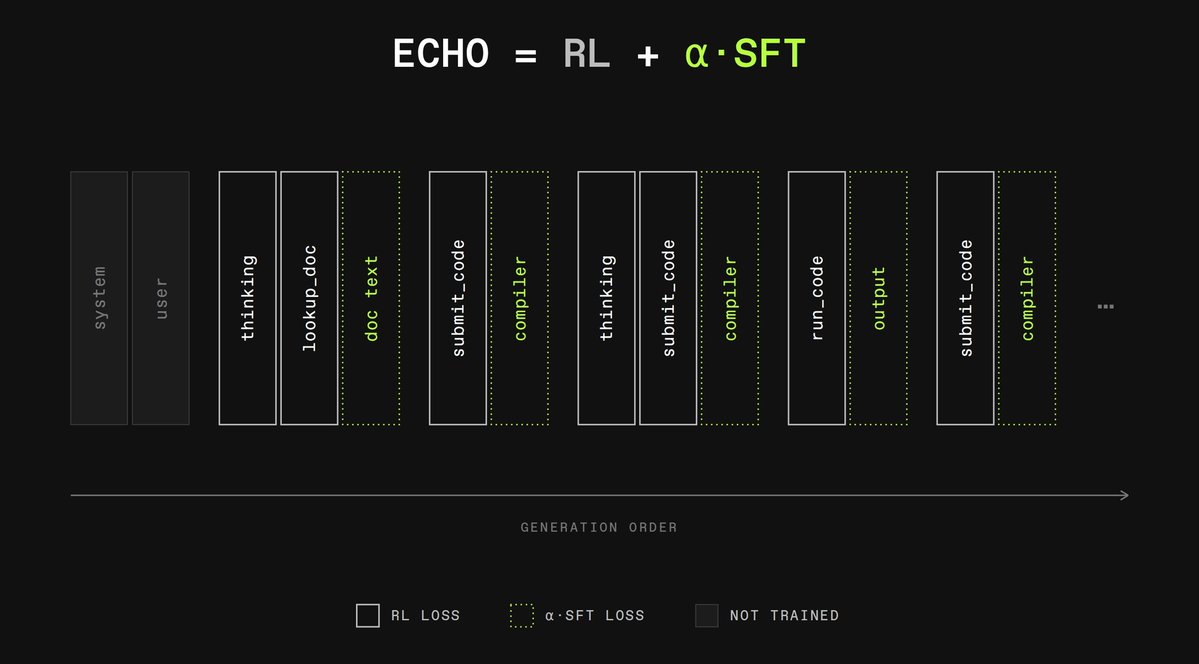
Very exciting work to bridge the gap between RL and mid/pretraining
You can learn from your environment beyond the reward signal by doing next token prediction on some of your tool call output
Jun 10
True agents model the world.
Current training provides no separation between agent and environment: pre-training only trains world modeling, RL only agentic actions. We combine both using ECHO by @DimitrisPapail and @VaishShrivas.
2
11
169
18,314
will brown retweeted

Jun 10
True agents model the world.
Current training provides no separation between agent and environment: pre-training only trains world modeling, RL only agentic actions. We combine both using ECHO by @DimitrisPapail and @VaishShrivas.
10
50
507
96,299
will brown retweeted

Jun 10
There are measures to temporarily delay RSI but no alternative end for a non-declining civilization.
Game theory is irrefutable.
That’s why I believe @PrimeIntellect is ethically and philosophically correct.
We need to trust each other as humans (while building with care).
2
1
32
4,331
will brown retweeted

Jun 10
after fable limiting ml research
now you understand what is prime intellect doing?

1
3
58
6,032
Jun 10
capabilities are getting locked up. come join the fight
jobs.ashbyhq.com/PrimeIntell…
34
47
942
89,517
Jun 10
this is what it looks like for a frontier lab to bring everyone along for the ride

20
22
764
106,800
Jun 9
coherent in-the-weights continual learning is the biggest open problem left for LLMs, and anthropic is hoping it never gets solved.
deploying it broadly requires open weights. the only ZDR option is on-prem. if you are a researcher who wants open models to thrive, work on it.
26
24
505
31,117
Jun 9
the most humanity-aligned business model for a frontier lab is recursive self-commoditization
keep the big models closed, enable distillation into open models from the same family, capture value on both sides
both openai and google could do this. enterprises would love it.
9
9
223
17,241
Jun 9
the issue with gpt-oss and gemma is that they were side quests done for goodwill, not part of the core strategy
if anthropic starts pulling away with market share, this button becomes more appealing to press
1
40
2,685