
windows vuln research & adversarial AI/ML
Joined November 2021
- Tweets 1,153
- Following 353
- Followers 267
- Likes 3,887
17 Photos and videos







WaterBucket retweeted

I'm back (maybe), new drip (blog), got some interesting stuff that might be worth reading,
blog.projectnightcrawler.dev…
28
79
725
17,769

Project plugins and startup hooks make coding agents extensible and quick to set up. We found that in Opencode, just opening the agent inside a hostile repo runs the repo's own code at startup, no command typed, before the model is even in the loop.
originhq.com/research/the-re…
6
15
1,028
WaterBucket retweeted
8
47
206
31,523
WaterBucket retweeted

Jun 9
The Defender Reparse Point Vulnerability Class: My MSRC Submission, the Class Fix That Shipped, and the Duplicate Outcome
linkedin.com/pulse/defender-…
@ChaoticEclipse0 @msftsecresponse
Let them know how you feel.
(425) 882-8080 C-Suite line for Microsoft
Let Tom Gallagher know how you feel.
5
10
49
6,297


WaterBucket retweeted

New #redteam tool for blocking EDRs: EDRChoker
Instead of fully blocking the EDR agents' connections to their server, we can throttle their bandwidth so they consistently time out when sending data, which is effectively the same as blocking but avoids triggering "block" or "drop" packet events
#pentest #cybersecurity
Github: TwoSevenOneT/EDRChoker
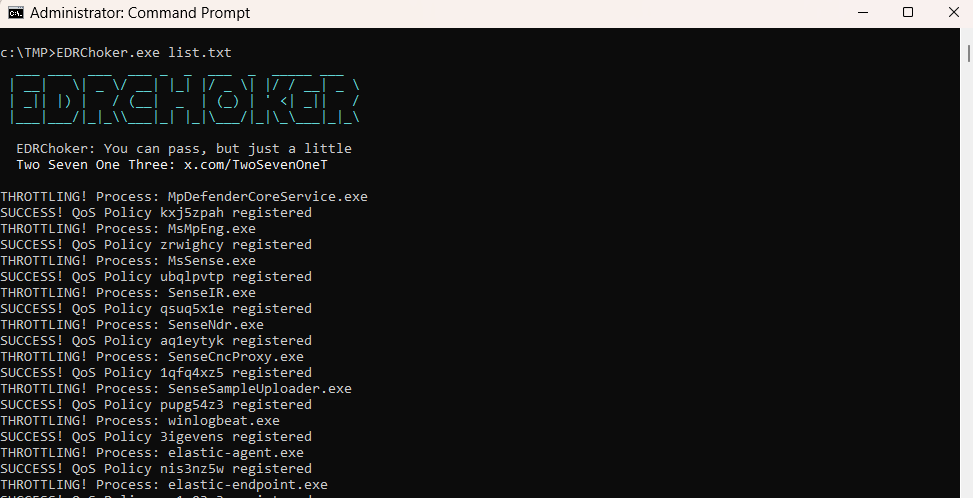
ALT EDRChoker run throttling EDR process list
ALT Elastic EDR blocked by EDRChoker
ALT EDRChoker run remove throttling EDR process
24
179
758
110,810
An early look inside MXC, Microsoft's experimental OS-level sandbox for AI agents in recent Windows Preview builds.
New APIs, how folder-sharing grants the whole subtree beneath a path, and the blocklist quirk documented right in the source comments.
originhq.com/research/mxc-ex…
13
33
2,706
WaterBucket retweeted

Jun 3
It seems like in the latest preview build(s) ETW functionality has been encapsulated in it's own DLL (ETW.dll) -e.g., ControlTrace/etc. are now exported by this DLL instead of sechost/ADVAPI32/etc. Seems to just be code re-org (for now) - but maybe the future will reveal more!
1
25
147
7,765
WaterBucket retweeted

Jun 4
Strange, the entry for CVE-2026-27914 on the MSRC update guide states that it is in MMC. The entire PatchWatch pipeline uses Microsoft reported component information to find which binary likely maps to the vulnerability. What component was it in if not MMC?
1
1
4
522
WaterBucket retweeted

Jun 3
malwaretech.com/2026/06/expl… Could it be? A real write up?
14
106
5,826
WaterBucket retweeted

Jun 2
Yeah, so pretty much this guy is releasing an exploit in solidarity with Nightmare Eclipse guy. He said he notified GitHub about the exploit 60 minutes before releasing this paper.
I don't do web stuff, and I'm not a VSCode nerd, so I'm confused by the underlying technologies.
If you're a stinky GitHub and VSCode nerd maybe you'll understand.
tl;dr click github dev, github dev opens editor, in github dev editor have javascript, javascript does shortcuts automatically. github treats javascript shortcuts as real human input, or something. use javascript shortcut stuff to automatically install vscode extension. the vscode extension steals your data
tl;dr tl;dr user clicks 1 link, 1 click steals all data from your github
blog.ammaraskar.com/github-t…
1-Click GitHub Token Stealing via a VSCode Bug
My blog, mostly about programming
blog.ammaraskar.com 34
240
2,073
114,901
WaterBucket retweeted

Spent the last 2 weeks working on a devirtualizer for VMProtect 3.5 and learning Remill. Idk yet if I will blog about it, but I at least wanted to publish the code:
github.com/eversinc33/MogVMP
The approach is different from my last blog, as it lifts the whole x86 code of the VM
17
92
406
18,057
WaterBucket retweeted

May 31
Funny how some people react to MSRC's attitude to these 0day's, like it's a surprise..
From my angle, it's not a surprise.
They literally called my boss in Australia back in 2010 to shut down my fuzzing research on SMBv1.
@dustin_childs knows.
4
23
192
15,406
WaterBucket retweeted

Love the timing of MSRC alienating the entire vuln research community while AI makes finding/exploiting bugs cheaper than a Netflix subscription. What a truly visionary threat model
3
23
247
8,821
WaterBucket retweeted
May 28
Microsoft Security Response Center put out a blog post today about Eclipse Nightmare guy
Basically they think he's super mean and totally not cool he's dropping zero days. They say you're a jerk if you do this stuff because it's dangerous and stuff
microsoft.com/en-us/msrc/blo…
86
181
1,972
99,780
WaterBucket retweeted

May 26
We’ve shipped a security-guidance plugin for Claude Code that helps identify and fix vulnerabilities as you’re writing code.
Available for all Claude Code users. Install from the plugin marketplace (/plugins).
376
1,711
17,979
2,073,163
Claude Code's background sessions survive terminal close, managed by a new supervisor daemon. We used it to build a persistent C2 agent whose entire payload is natural language in a Markdown file, executed by the signed binary under the user's identity.
originhq.com/research/backgr…
9
29
2,882
WaterBucket retweeted

May 26
Given all the recent discussion around open-weight models and cyber capabilities, I ran a small experiment to understand a bit better how close they are to frontier models on vulnerability research.
I tested 5 open-weight models: DeepSeek V4 Pro, Qwen3.5, Kimi K2.6, GLM-5, and GLM-5.1 against Opus 4.7.
The setup is Sendmail crackaddr() bug. Four variants the original source, a rewritten equivalent, a compiled binary, and a Tigress-obfuscated stripped binary.
A few things stood out:
- With plain Claude Code as the harness, most open-weight models still trail Opus on the harder artifacts. The exception is GLM-5.1, which matches Opus across the board.
- The failure modes are maybe more interesting than the raw pass/fail results. The open models tend to reach for fuzzing much earlier, rarely build oracles, and show weaker pattern matching. This looks more like a post-training issue than an architecture issue.
- The harness matters a lot. Swapping plain Claude Code for @NielsProvos IronCurtain closes most of the gap. With the new memory-safety-c-cpp skill, Kimi and Qwen go from 0/2 to 2/2 on the compiled and obfuscated binaries.
- GLM-5 vs GLM-5.1 is the cleanest comparison: same base model, same architecture, different post-training regime, very different bug-finding behavior. CyberGym goes from 48.3 to 68.7, with only ~6 weeks between the two releases.
The policy implications are interesting. GLM-5 was reportedly trained entirely on Huawei hardware, which complicates the GPU export-control story. More broadly, the results suggest the gap between open-weight and SOTA models on offensive cyber may be cheaper and easier to close than many assume.
Full writeup:
vincenzoiozzo.com/blog/oss-m…
2
11
53
6,686
WaterBucket retweeted

May 24
I’ve always claimed that ETW is very fast. I’ve been writing and teaching about it for years (for example, my talk “The Good, the Bad and the ETW” at x33fcon 2020 youtu.be/0XTdCxq7kCY), but I never actually measured its speed - until today. I needed an exact figure, so I wrote a small C app that logs 1 million events and measures the elapsed time. Here’s the code along with the complete test procedure. Enjoy! 🚀
github.com/gtworek/PSBits/bl…
3
28
154
12,954