
coding . ml . math . writing . books . github.com/imteekay
Joined December 2009
- Tweets 7,030
- Following 335
- Followers 10,111
- Likes 12,198
Photos and videos
Pinned Tweet

20 Mar 2025
One book at time. Better over time.

30
84
2,117
100,752
Jun 7
This resonates a lot with my experience. My record was 60 books a year (not 80 in 6 months tho). Because I'm curious about a lot of things, many topics get my attention, so the "Parallelize" (books) tip is a really effective way to read more book. I read 3-4 at the same time, a bit every day, consistently. It turns out it is much easier to do, and in the long-term, I accomplish more.
Reading a lot also made me rethink about which books I choose to read (reading less → reading better books: iamtk.co/i-read-47-books-in-…). And because I usually read technical and non-fiction books, it's great to re-read them, take notes, and think in way to apply the ideas in my life (iamtk.co/essays/applying-boo…).
"How To Read More" by Borretti: borretti.me/article/how-to-r…

7
92
833
21,713
Feb 17
As an applied ML engineer who is learning more about research and theory, I found two interesting resources I read this week that are worth sharing.
The first one is the "On Research Taste"¹ article by Albert Ying. I liked how he defines what 'taste' really is: "the ability to find the node that would affect the largest number of other nodes [...] over a network", where the graph is a collection of "hypotheses and analyses you could pursue". I think the missing part of this short article is "how to develop 'taste'".
The second one is the "An Unofficial Guide to Prepare for a Research Position Application"² by Sakana AI. That was the most insightful blogpost I've read this year. It lays down all the core principles to be a great researcher, how to approach ideas, the importance of clear communication, and having a good balance between technical ability (engineering skills) and creativity.
The post is more than how to prepare for their interview. It's their way of doing great research.
¹ kejunying.com/blog/research-…
² pub.sakana.ai/Unofficial_Gui…
5
34
376
15,496
21 Aug 2023
📝 I hope with this new post, you can steal some ideas, and insights, and put them into practice in your life. This is my reflection about reading 47 books in the first 6 months of 2023 and how I am focusing on reading less applying them in my life.
iamtk.co/i-read-47-books-in-…
3
12
135
20,806


Jun 1
𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗮 𝗚𝗣𝗧 𝗠𝗼𝗱𝗲𝗹
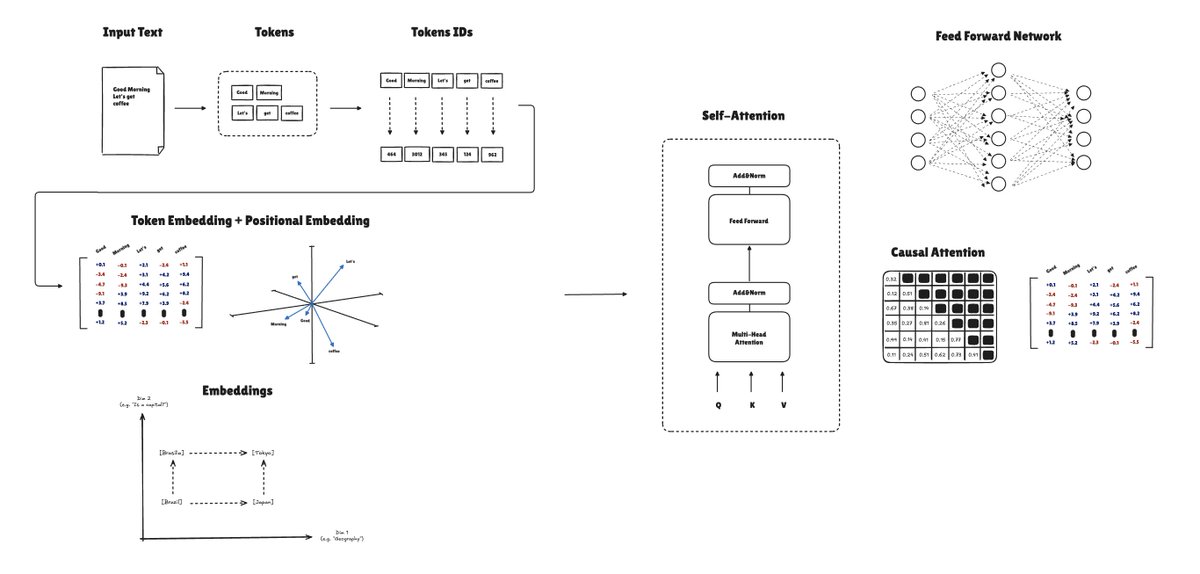
For the past few weeks, I've been reading about Foundation Models [0] and decided to work on the implementation of the GPT architecture [1] to understand its building blocks and how it works under the hood.
Here are the concepts I worked on in this implementation:
Tokenization → Embeddings → Self-Attention → Multi-Head Attention → Transformer Block → GPT Model → Pretraining.
— The tokenization part was focused on building tokens from the input text and transforming them into token IDs; Then using a BPE tokenizer algorithm [2]
— Embeddings: representing tokens with a simple scalar value (ID) is too simplistic. Embeddings come to build richer representations. I built small embeddings for learning purposes and then increased the representation to scale that
— Multi-Head Self-Attention: this was one of the most interesting parts, creating attention scores and building relationships between tokens to produce context vectors
— Transformer blocks have the attention heads, dropout, layer norm, and the feed-forward network
— Pretraining is a standard training process used for deep learning models. But in this case, we update the weights end-to-end, from the embeddings to the attention layer to the feedforward network
The implementation was highly inspired by the Language Modeling from Scratch course [3] and the Build a Large Language Model book [4]. It's still very rudimentary, but very useful if you plan to learn these concepts in depth.
🔗 Article Link: Self-Attention, Foundation Models, and the GPT Architecture from Scratch: iamtk.co/self-attention-foun…
---
In the future, I plan to write about finetuning (using foundation models and finetuning for other tasks) and optimizations (attention blocks optimization, GPU and kernel optimization).
[0] Foundation Models at Nubank: x.com/wordsofteekay/status/2…
[1] LLM implementation repo: github.com/imteekay/llm
[2] Tokenizers lecture: youtube.com/watch?v=SQ3fZ1sA…
[3] Language Modeling from Scratch: youtube.com/playlist?list=PL…
[4] Build a Large Language Model: manning.com/books/build-a-la…
May 17

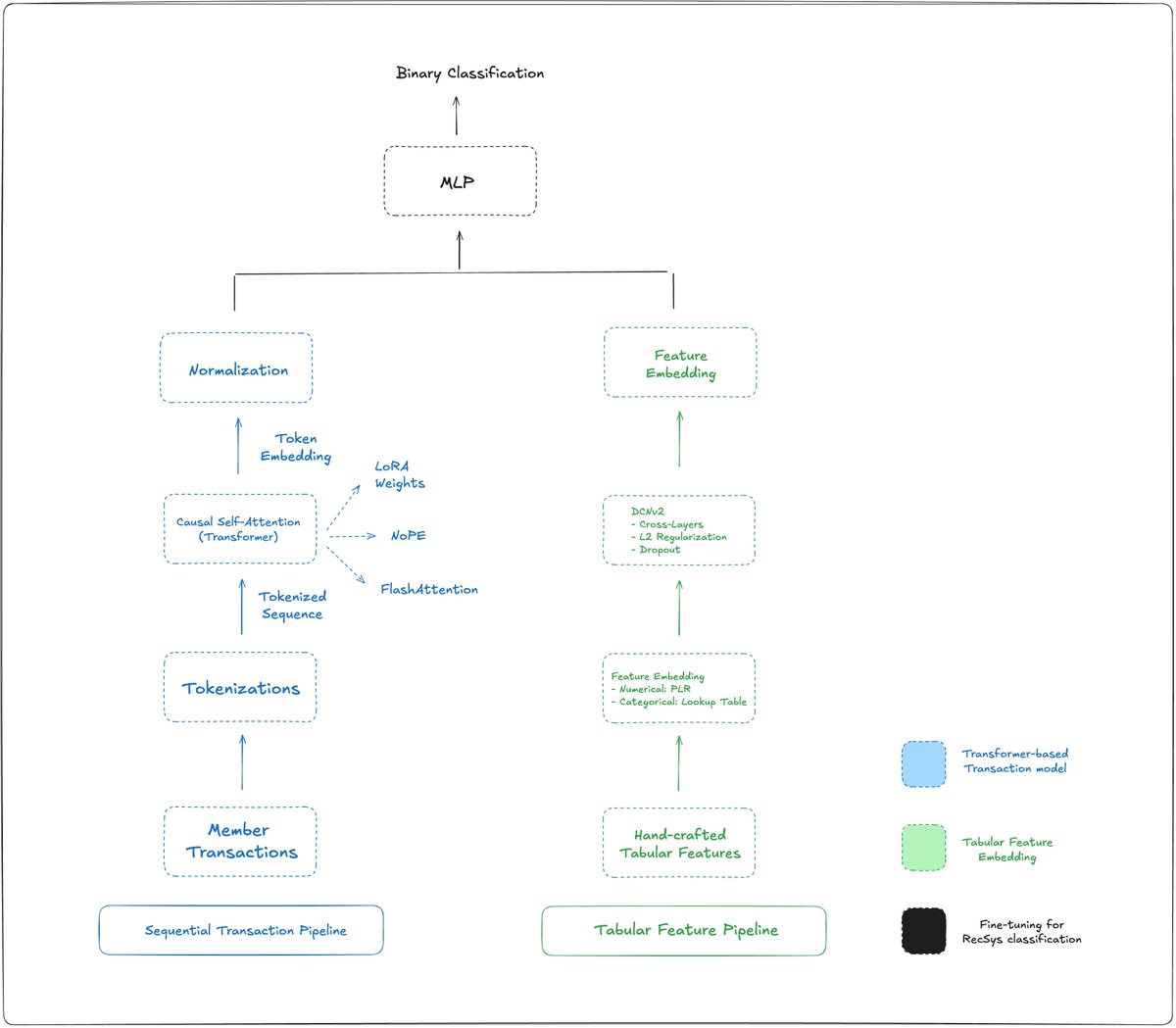
[Paper Reading: Your Spending Needs Attention]
I've just finished reading the "Your Spending Needs Attention" paper by Nubank, and not only are the results impressive, but the ML and engineering approach is also very interesting. It shows the power of self-supervised representation learning to automatically understand user behavior from raw (transaction) data, which made me think about how many insightful representations we are missing by not using it, and why (engineering and money trade-offs come to mind).
Here's the research breakdown: causal self-attention tabular feature embedding fine-tuning for RecSys.
Transformer-based model:
> Text is All You Need: Individual transactions are tokenized, concatenated into a transaction string, and fed through a Transformer [0] to produce a transaction sequence embedding.
> No Positional Embeddings (NoPE) [1]: drop the temporal information
> FlashAttention [2] NoPE = Efficient Long Contexts (transaction = ~14 tokens — the sequence gets large very fast): the model can train on much larger context lengths
Tabular Features:
> Feature embeddings for numerical and categorical variables
> LightGBM: gradient-boosted tabular modeling
> Deep Cross Network V2 (DCNv2) [3]: learn feature interactions
Fine-Tuning — classification task for RecSys:
> Low-Rank Adaptation (LoRA) [4]: injecting trainable low-rank matrices into attention layers to handle the "overfitting and catastrophic forgetting" issues.
> Late Fusion: freeze the transformer embeddings and use them as static features passed into LightGBM or DCNv2 independently.
> Joint Fusion (nuFormer): keep the transformer embeddings trainable end-to-end alongside the tabular features.
It's very insightful how joint fusion trains the entire system end-to-end using a DNN, so gradients can flow through the embeddings compared to GBT.
Other insightful ideas from the paper:
> Context window problem: adding more data sources (e.g. financial products) can lead to worse results because each data source will "compete" for the available tokens for a fixed context window.
> Scaling laws: larger model size, context lengths, and data volume lead to improved performance.
There are still many interesting avenues they will explore, especially scaling laws and scaling the application to other products. It was also insightful how they are not just following the state of the art, but doing research to find new ideas [5].
---
Paper: arxiv.org/abs/2507.23267
---
[0] arxiv.org/abs/1706.03762
[1] arxiv.org/abs/2305.19466
[2] arxiv.org/abs/2205.14135
[3] arxiv.org/pdf/2008.13535
[4] arxiv.org/abs/2106.09685
[5] open.spotify.com/episode/11v…
4
4
82
2,388
May 30
✨ I worked on this article the whole day and made a lot of progress. I'm almost there.
A lot of work, with many experiments, but it's getting traction. "Make Something Wonderful" inspired me to keep building and sharing.
May 16
[ML Grind]
Finished:
> Foundation Models: finished transformer-based model implementation from scratch finetuning
> Finished reading the Attention-based model in the industry paper: interesting insights about context length, scaling laws, and joint fusion
Have been working on:
> ML monitoring alerting system for ML models
> AI agent for business flow: interesting engineering learnings (agent/prompt refinements <> MCP <> backend infra)
> Real estate liquidity model: interesting learnings about temporal splits, model calibration, model optimization, and dataset exploration
Plan for today:
> Continue writing the blog post about the foundation model implementation
> Continue the "Language Modeling from Scratch" course by Stanford
> Read a new ML paper
2
2
17
1,382
Apr 2
📚 Started a new book today.
I'm on the first few pages, and the way it was written already caught my attention.
"Teachers should prepare the student for the student's future, not for the teacher's past. Most teachers rarely discuss the important topic of the future of their field, and when this is pointed out, they usually reply: 'No one can know the future'. It seems to me the difficulty of knowing the future does not absolve the teacher from seriously trying to help the student to be ready for it when it comes."
Excited to be educated on styles of learning and thinking, and then get back to training, applying those principles.

8
16
274
26,631
May 29
I finally finished this book today. What a remarkable last chapter! I'm getting all my notes to share it online.
Also, I'm looking for the next book! I accept recommendations.
1
1
129
May 20
Many people have already pointed out, but this course by Stanford is remarkable. It's been part of the first hour of my morning. Watching the lecture, taking notes, spawns new tabs with different papers mentioned, and coding to build the intuition behind each lecture.
Mixture of experts was a nice lecture, but the one I liked the most so far was about PyTorch and resource accounting and how to make sense of CPU/GPU, memory, runtime/compute (FLOPs), etc., from first principles.
🔗 link: youtube.com/playlist?list=PL…

3
10
153
4,973
May 20
My notes on the repo: github.com/imteekay/machine-…
Even though most of my notes are written in my physical notebook. Still lacking time to move all to the repo.
notes: github.com/imteekay/machine-…
2
6
606
May 29
This last GPU lecture (FLOPs/memory movement optimization) was awesome! ✨
2
96
May 23
I've just read the "Let Me Convince You to Be Prolific" post about the benefits of being prolific, especially for creative people in the digital age.
The idea is that we should create and release more experiments, creating this long tail of acceptable work:
— Experiment > Failure > Refine > Loop
— Publishing work helps people find you
— Early drafts, faster feedback loop > faster improvement
— Each experiment contributes to the following one
I noticed this about my blog, where I've been writing for 10 years now. All the technical blogs I wrote helped improve the next one. Any of them is perfect, but I can see how much progress I have made over time.
The things you learn, the feedback you get, and the will to refine your work lead to mastery. And the long tail of work starts to compound and help discover you.
There are these two quotes I liked:
> "Giving up on perfectionism doesn’t mean that you will not produce anything perfect, but rather that perfection will happen from time to time because of the sheer mass of output." — Dean Keith Simonton
> "If you can write one short story a week — it doesn’t matter what the quality is to start, but at least you’re practicing, and at the end of the year you have 52 short stories, and I defy you to write 52 bad ones." — Ray Bradbury
I found this blog in @noghartt's bookmarks. There's an awesome curation there.
→ Blog: 3quarksdaily.com/3quarksdail…
1
14
183
5,784
May 22
I've just found out about this course on Foundation Models and Generative AI. Quite interesting lectures. I plan to watch the lectures as soon as I finish the Language Modeling from Scratch course. So many interesting things to learn.

3
10
160
5,729
May 17
[Paper Reading: Your Spending Needs Attention]
I've just finished reading the "Your Spending Needs Attention" paper by Nubank, and not only are the results impressive, but the ML and engineering approach is also very interesting. It shows the power of self-supervised representation learning to automatically understand user behavior from raw (transaction) data, which made me think about how many insightful representations we are missing by not using it, and why (engineering and money trade-offs come to mind).
Here's the research breakdown: causal self-attention tabular feature embedding fine-tuning for RecSys.
Transformer-based model:
> Text is All You Need: Individual transactions are tokenized, concatenated into a transaction string, and fed through a Transformer [0] to produce a transaction sequence embedding.
> No Positional Embeddings (NoPE) [1]: drop the temporal information
> FlashAttention [2] NoPE = Efficient Long Contexts (transaction = ~14 tokens — the sequence gets large very fast): the model can train on much larger context lengths
Tabular Features:
> Feature embeddings for numerical and categorical variables
> LightGBM: gradient-boosted tabular modeling
> Deep Cross Network V2 (DCNv2) [3]: learn feature interactions
Fine-Tuning — classification task for RecSys:
> Low-Rank Adaptation (LoRA) [4]: injecting trainable low-rank matrices into attention layers to handle the "overfitting and catastrophic forgetting" issues.
> Late Fusion: freeze the transformer embeddings and use them as static features passed into LightGBM or DCNv2 independently.
> Joint Fusion (nuFormer): keep the transformer embeddings trainable end-to-end alongside the tabular features.
It's very insightful how joint fusion trains the entire system end-to-end using a DNN, so gradients can flow through the embeddings compared to GBT.
Other insightful ideas from the paper:
> Context window problem: adding more data sources (e.g. financial products) can lead to worse results because each data source will "compete" for the available tokens for a fixed context window.
> Scaling laws: larger model size, context lengths, and data volume lead to improved performance.
There are still many interesting avenues they will explore, especially scaling laws and scaling the application to other products. It was also insightful how they are not just following the state of the art, but doing research to find new ideas [5].
---
Paper: arxiv.org/abs/2507.23267
---
[0] arxiv.org/abs/1706.03762
[1] arxiv.org/abs/2305.19466
[2] arxiv.org/abs/2205.14135
[3] arxiv.org/pdf/2008.13535
[4] arxiv.org/abs/2106.09685
[5] open.spotify.com/episode/11v…
May 16
[ML Grind]
Finished:
> Foundation Models: finished transformer-based model implementation from scratch finetuning
> Finished reading the Attention-based model in the industry paper: interesting insights about context length, scaling laws, and joint fusion
Have been working on:
> ML monitoring alerting system for ML models
> AI agent for business flow: interesting engineering learnings (agent/prompt refinements <> MCP <> backend infra)
> Real estate liquidity model: interesting learnings about temporal splits, model calibration, model optimization, and dataset exploration
Plan for today:
> Continue writing the blog post about the foundation model implementation
> Continue the "Language Modeling from Scratch" course by Stanford
> Read a new ML paper
3
34
2,123
May 16
[ML Grind]
Finished:
> Foundation Models: finished transformer-based model implementation from scratch finetuning
> Finished reading the Attention-based model in the industry paper: interesting insights about context length, scaling laws, and joint fusion
Have been working on:
> ML monitoring alerting system for ML models
> AI agent for business flow: interesting engineering learnings (agent/prompt refinements <> MCP <> backend infra)
> Real estate liquidity model: interesting learnings about temporal splits, model calibration, model optimization, and dataset exploration
Plan for today:
> Continue writing the blog post about the foundation model implementation
> Continue the "Language Modeling from Scratch" course by Stanford
> Read a new ML paper
4
9
215
10,088
May 16
As long as I can remember, I have always had this desire to do great things. Not only making something wonderful, but striving to become great.
Yet another day, I wake up with these thoughts. Let's refine my skills, work on my projects, and go one step further in this infinity game of life.
3
2
24
803
May 2
[ML Grind]
Yesterday I took the day to work on the model training of the GPT-like model. I built the tokenization/embedding layers, the multi-head attention mechanism, added the transformer blocks to the GPTModel, and trained it on input text of 5k tokens (not big but useful for learning purposes).
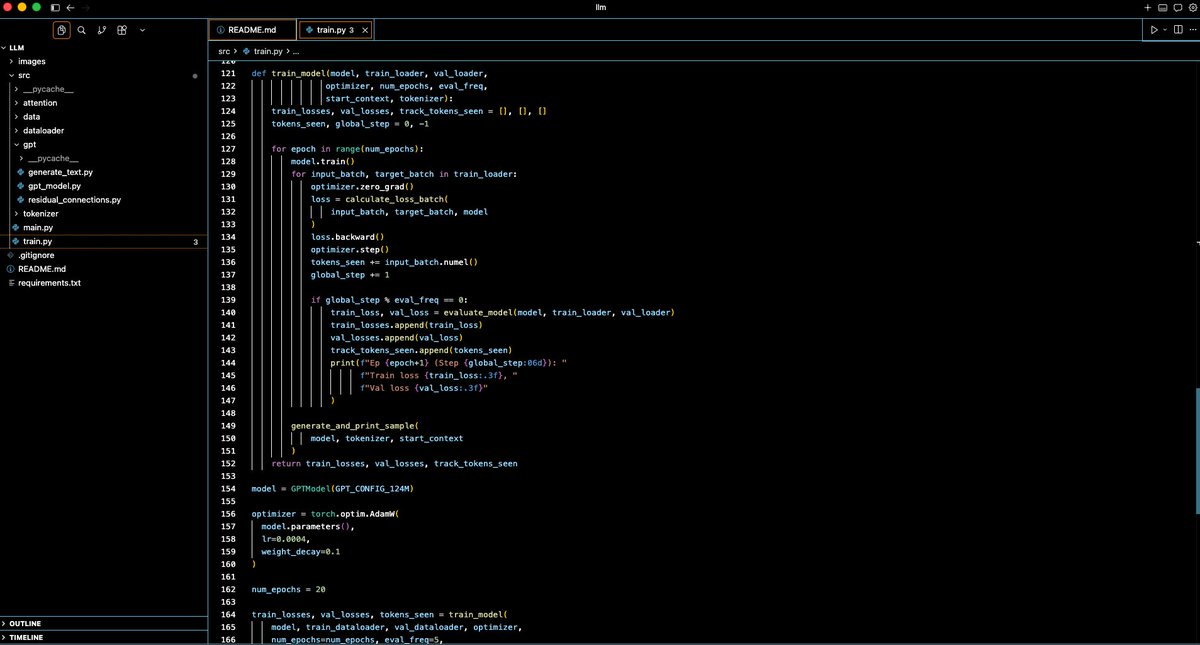


Apr 25
Continuing my ML progress
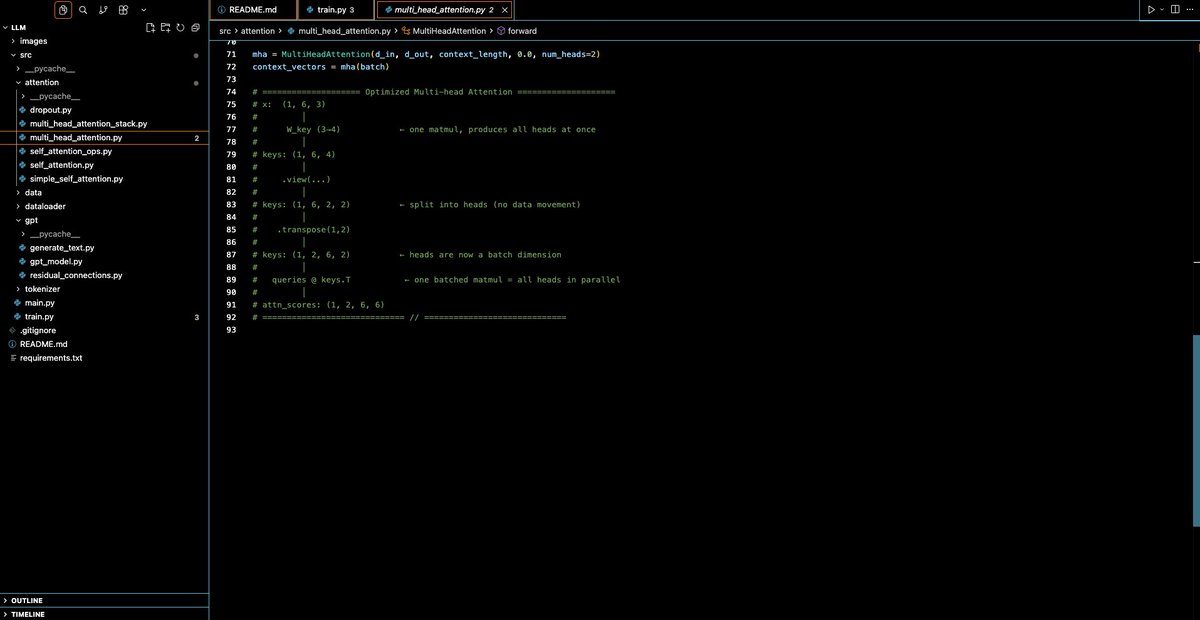
> LLM from scratch: worked on this all day (built a self-attention and multi-head attention mechanism)
> Finished the monitoring system this week
> AI Engineering: continue the book — I'm currently working on an AI agent product and I need to learn more about this one
> Got a mentor at work: he shared many papers and resources I should read (tons of work to do!)
> ML Bootcamp: working on the first project with my pair — first part (EDA) is done. Now I need to move to the model training phase
3
4
111
4,620
May 3
Follow up on this study: after training the foundation model, I experimented with randomness control (temperature scaling and top-k sampling), and then learned about using pretrained models, and finally finetuning for a classification problem.
This is so fascinating. I want to learn more about types of modalities other than jus text and try multimodal stuff FMs.
If you happen to know about interesting papers on that, hit me up.
375