
Computer scientist & journalist, specializing in AI, privacy, ethics, big data, usability and security. My opinions here. ORCID 0000-0003-1294-2831
Joined April 2009
- Tweets 138
- Following 1,715
- Followers 2,208
- Likes 5,234
11 Photos and videos











Jun 11
The Park Service has created a public comment form regarding President Trump's proposed arch. For those interested, submit your feedback!
parkplanning.nps.gov/comment…
38
Jun 5
Sex, drugs, paganism and runaways in 1990s Seattle. Sara has posted the next installment of her novel on Substack!
saraabramsstrathmore.substac…
98
Jun 3
Looks like @_saraabrams has finally gotten around to posting her novel...
saraabramsstrathmore.substac…
1
93
May 27
Richard A. Tapia (1939-2026) was first in his family to attend college, the first U.S.-born Hispanic person elected to the National Academy of Engineering (1992), and the first mathematician to hold the title of University Professor at Rice (and the sixth person in the university’s then-94-year history to do so), and the first recipient of the Computing Research Association’s A. Nico Habermann Award (1994). He and his twin brother Bobby were drag racers from age 15; in 1968, the brothers set a world record in elapsed time for fuel dragster racing, traveling a quarter mile in 6.54 seconds. He joined his two passions in a lecture, “Math at Top Speed: Exploring and Breaking Myths in the Drag Racing Folklore,” delivered at universities and mathematics-awareness events for decades.
cacm.acm.org/news/in-memoria…
3
8
389
May 21
There is now a "kudoboard" to Celebrate the life and work of Peter G. Neumann (PGN): kudoboard.com/boards/i46gOSi…
1
134
May 2
Something is very wrong at Apple when a point release takes 18GB.
172
Apr 29
"Style is everything."
(Best quote I wrote down from BasisTech's Demo Day.)
114
Apr 29
These days most of my new followers are bots with sexy photos and lots of digits in their usernames…
1
133
Apr 29
Vibe Coding? Check out @ACM's new TechBrief, "AI-Assisted Software Development, or Vibe Coding: Benefits and Risks of AI-Driven Software Development"
dl.acm.org/doi/book/10.1145/…
102
Apr 23
Michael Rabin always asked great questions at my talks at Harvard. When I found out he fought on Israel’s War of Independence, I was amazed.
cacm.acm.org/news/in-memoria…
2
211
Apr 22
Tech Night at the Pops goes back to the 1890s, and predates Boston Symphony Hall. I was fascinated to learn the history and read the original programs! Read along with me at technologyreview.com/2026/04… @MIT
120
Simson Garfinkel retweeted

Apr 17
someone just open-sourced a 1.7B parameter model that parses text, tables, formulas, images, and PDFs across 100 languages. 🤯
1.7B parameters. that's tiny. GPT-4 class models sit north of 100B.
the assumption has always been that multimodal parsing at real breadth requires massive scale. this breaks that cleanly.
the capability isn't the story. the efficiency is. a model this small runs locally, runs cheap, runs on a decent laptop. no API call. no GPU cluster.
document parsing is unglamorous work. it's also the bottleneck in almost every serious data pipeline.
open-source at 1.7B means it goes everywhere.
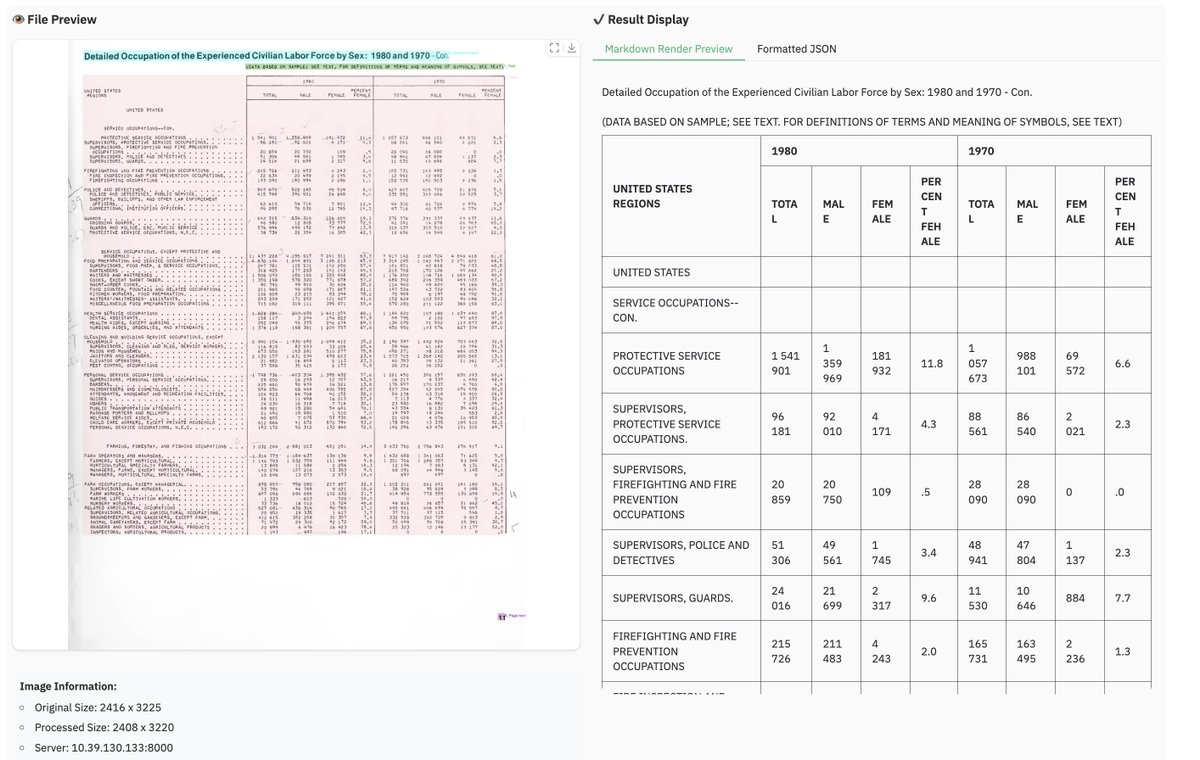

4
31
191
15,189
Simson Garfinkel retweeted

Apr 10
🚨 PDFs are officially broken.
Someone just dropped a tool that converts PDFs → clean Markdown
at 100 pages/sec 🤯
Tables? Extracted.
Messy layouts? Fixed.
Nested data? Perfect.
No GPU. No cost. No excuses.
It’s called OpenDataLoader.
This kills 90% of manual data work.
repo link: → github.com/opendataloader-pr…

22
159
1,022
94,538
Apr 10
A friend was intrigued when I told him how I have my AI coding agents ask me questions to develop a piece of software, so I wrote up my methodology for him. If people are interested, I can show how to use this methodology develop a simple in-browser video game.
databasenation.substack.com/…
1
168