
On the Job Market📍Santa Clara | interpretability, alignment, compositionality of diffusion models | EX - @AdobeFirefly, @SonyAI_global
Joined August 2021
- Tweets 70
- Following 401
- Followers 144
- Likes 368
12 Photos and videos









Pinned Tweet

Jun 4
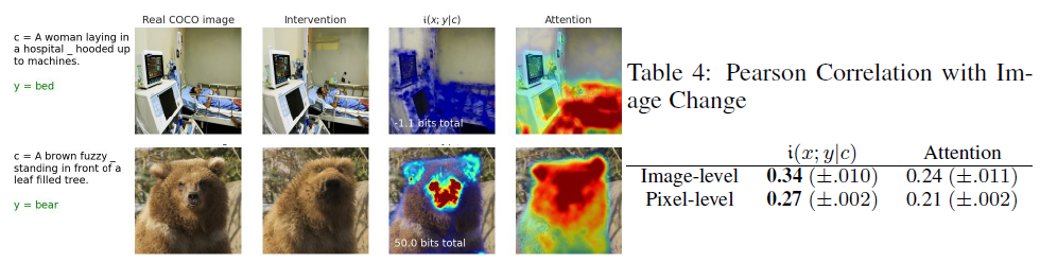
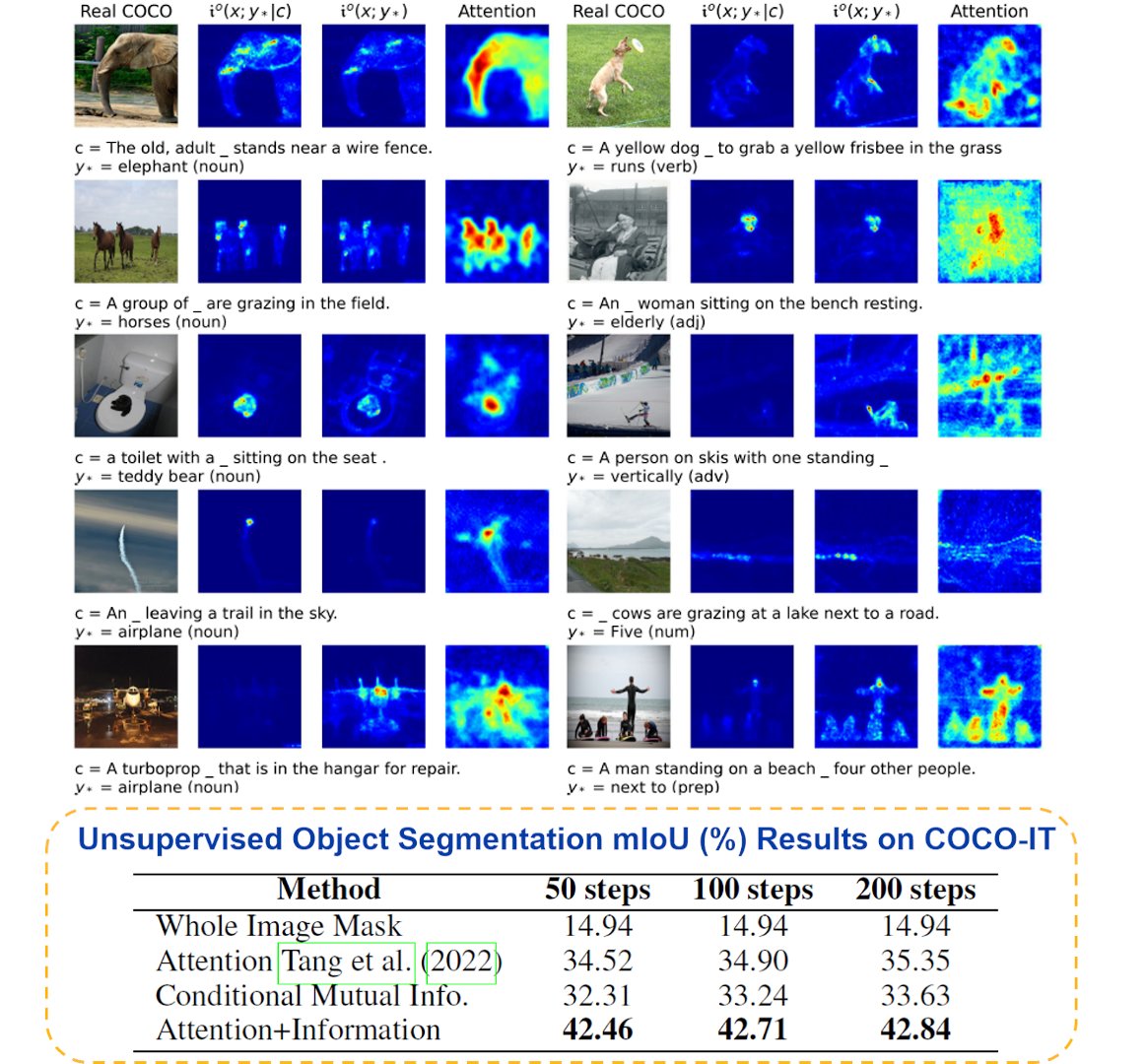
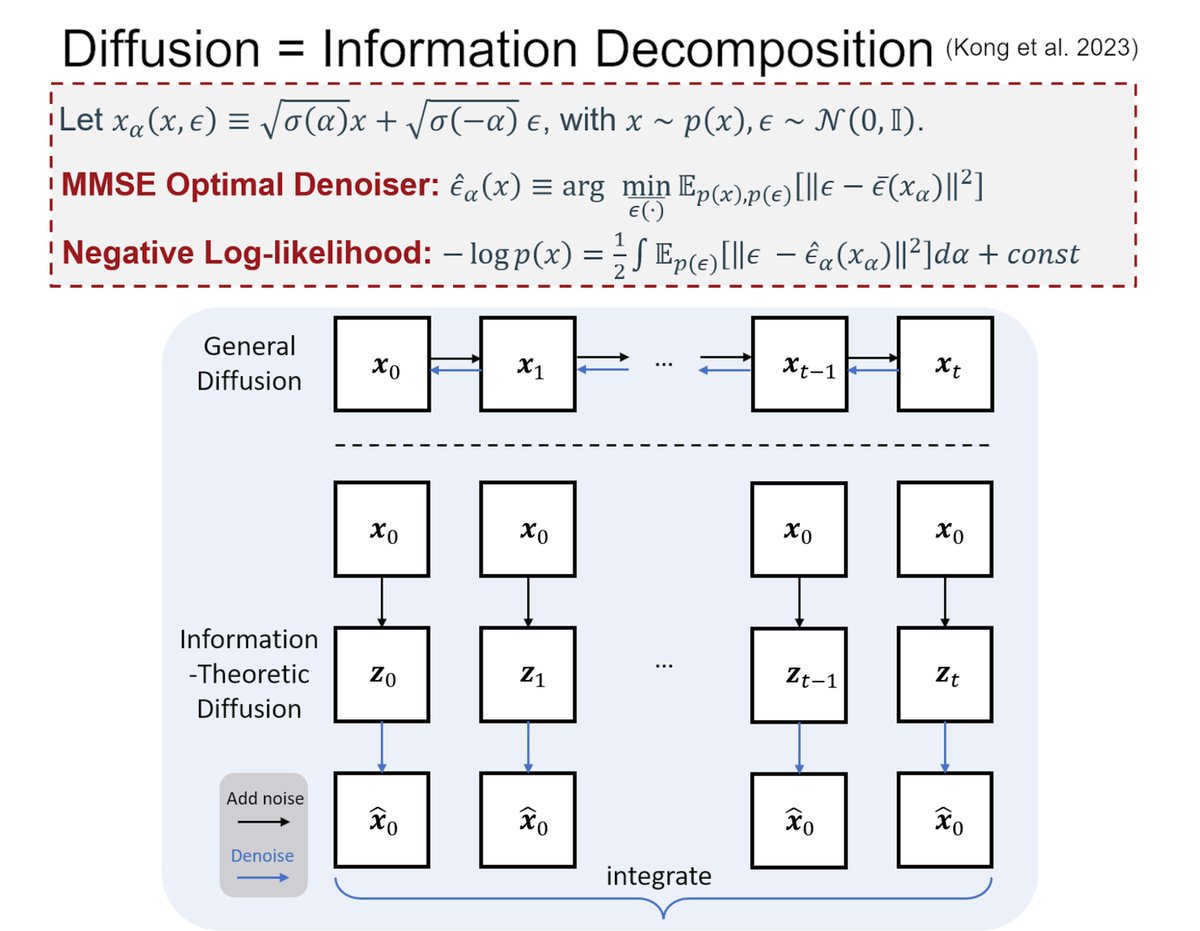
Most diffusion research today asks: How can we sample faster?
But I think another question is equally important: Are we training diffusion models in the right way?
famous-bubbler-dcc.notion.si…
1
1
5
214
Jun 4
Most diffusion research today asks: How can we sample faster?
But I think another question is equally important: Are we training diffusion models in the right way?
famous-bubbler-dcc.notion.si…
1
1
5
214
Jun 4
This may matter even more for recurrent diffusion and interactive generative models, where small errors can accumulate over long-term rollouts.
1
1
81
Jun 4
This is my first time turning some of my research thoughts into a blog post, so it may contain errors or unclear arguments. Any suggestions, comments, or feedback would be greatly appreciated🙌
60

Today we're releasing ZAYA1-74B-Preview, a major milestone in scaling pretraining on @AMD.
ZAYA1-74B-Preview is a 4B active / 74B total MoE.
This preview model is a strong pre-RL base checkpoint. The final post-trained reasoning model is coming soon. 🧵

24
87
799
1,203,704
Xianghao Kong retweeted

Mar 5
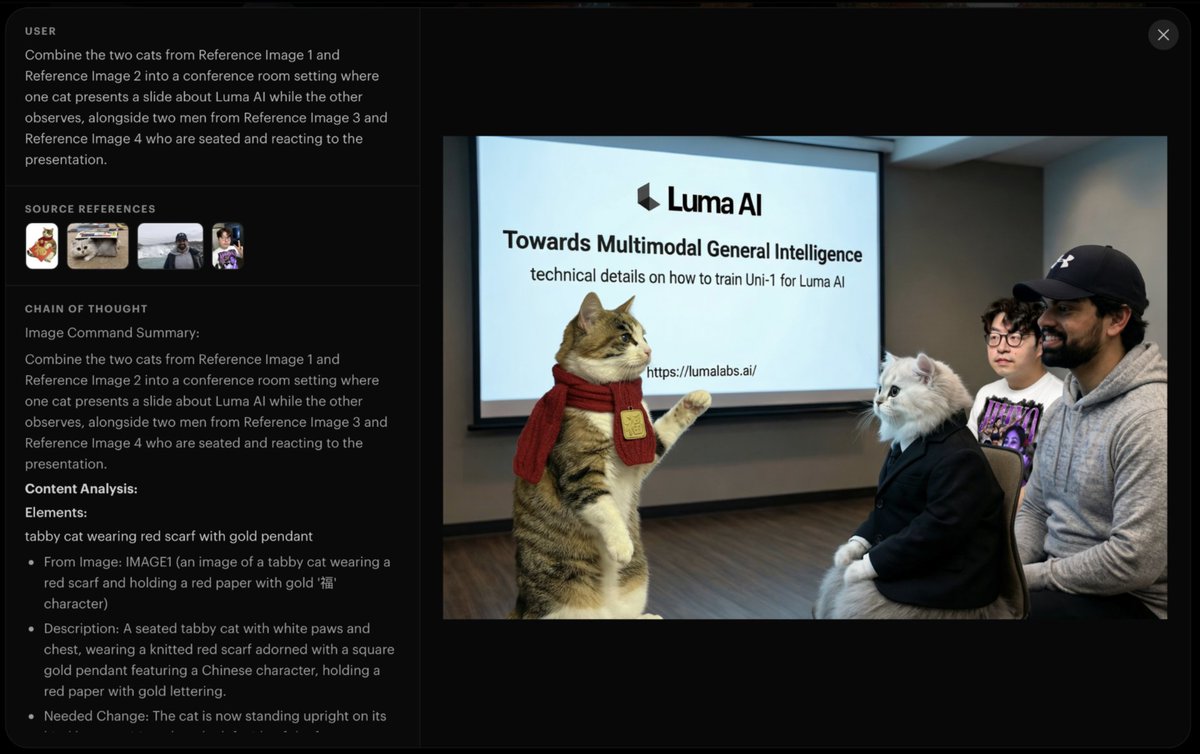
Really excited to see Uni-1 out in the world 🔥Our first unified model.
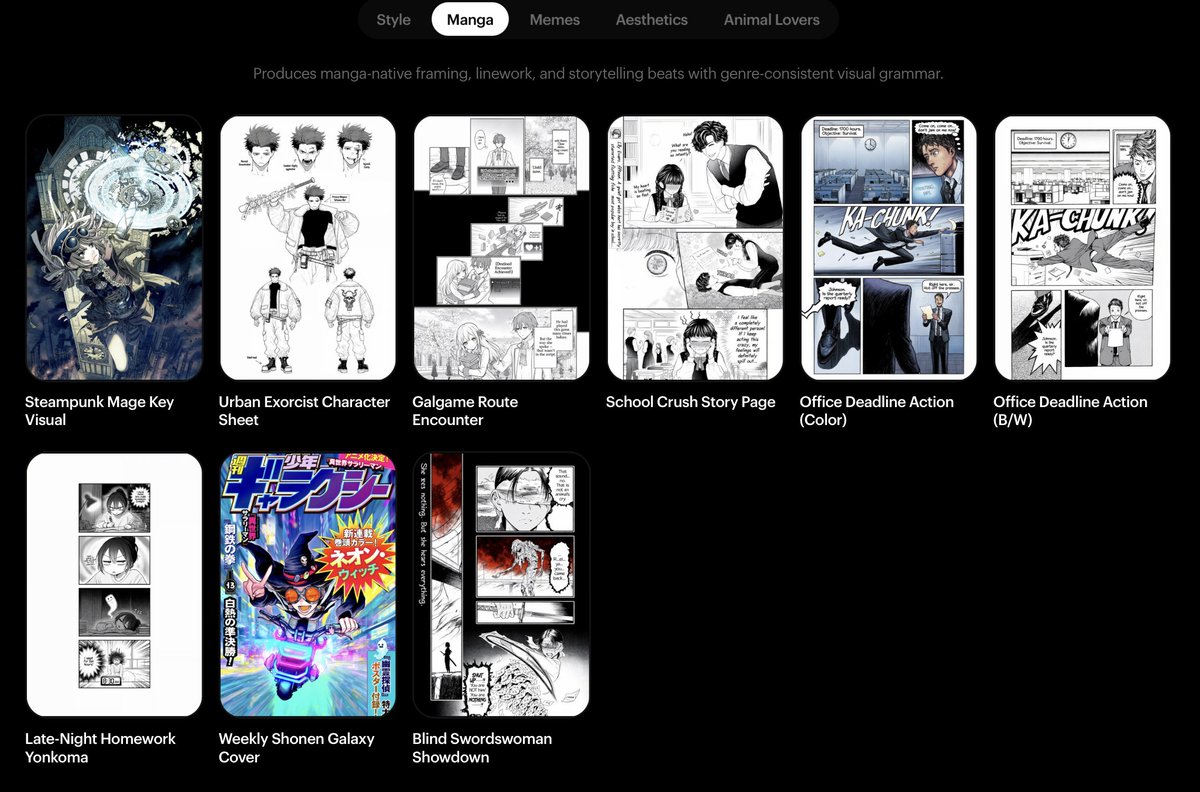
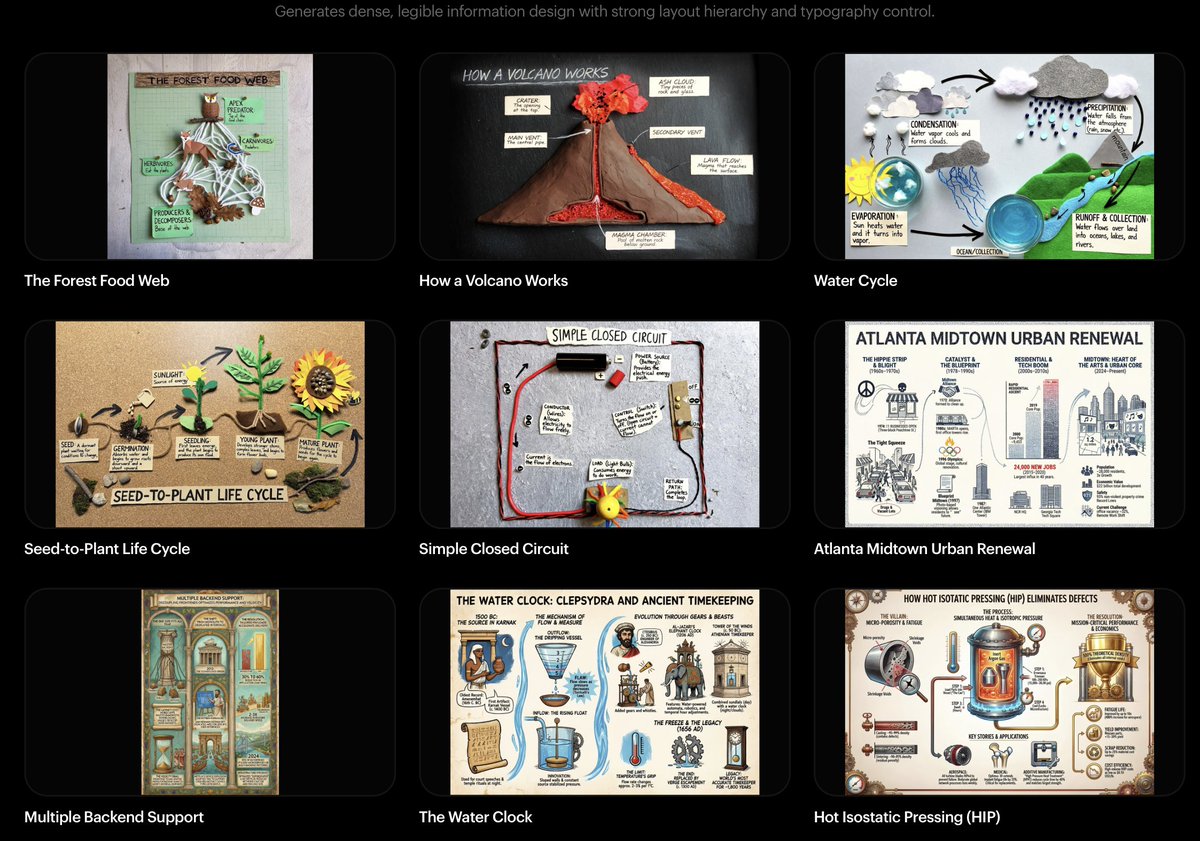
The range of things this model can do is wild: image-to-~100 styles, manga generation, multi-ref with strong identity preservation, temporal storytelling, sketch-to-image, spatial reasoning, multilingual infographics, layering… the capability range is honestly unreal. this is just the start 🫡 check out the blog to learn more lumalabs.ai/uni-1
Proud of the team and what we’re building at @LumaLabsAI 🚀

Mar 5

Introducing Uni-1, Luma’s first unified understanding and generation model, our next step on the path towards unified general intelligence.
lumalabs.ai/uni-1

ALT Combine the black and white curly-haired dog with pink bandana, the Boston Terrier in plaid harness, and the black-and-white cat into a single scene where they are dressed in academic regalia, standing before a whiteboard filled with scientific diagrams and text, with the Luma AI logo placed in the top-left corner.
2
8
61
7,070
7 Dec 2025
🤯💥

3
351
2 Dec 2025
I’m currently in transit to San Diego for NeurIPS. If you’re also killing time, feel free to check out a 2-minute-30-second horror sci-fi short film Michael and I recently created. We’d love any comments or likes:
devpost.com/software/dreamca…
Looking forward to catching up at the venue! 🎥
230
27 Nov 2025
Why must robots be human-shaped? Bringing impossible creatures into the real world can create just as beautiful an emotional bond ❤️
24 Nov 2025

It's official! From 29 March 2026 you'll be able to discover World of Frozen and lots of other experiences at Disney Adventure World! 🤩
269
23 Aug 2025
I feel the debate shouldn’t only be about whether DiT is effective, but also about how information preservation is the key to accelerating diffusion training. Our MicroDiT (arxiv.org/abs/2407.15811) paper showed this: by letting masked token info mix into unmasked ones, we can cut down a lot of tokens with only minor performance loss.
Interestingly, two months ago, when I caught up with @StefanABaumann at #CVPR, we discussed how TREAD and MicroDiT are conceptually similar from info perspective. Maybe it’s time to look at diffusion through an information-theoretic lens: from post-training (for the better alignment) to latent space curation, I believe this could lead to some really exciting discoveries!

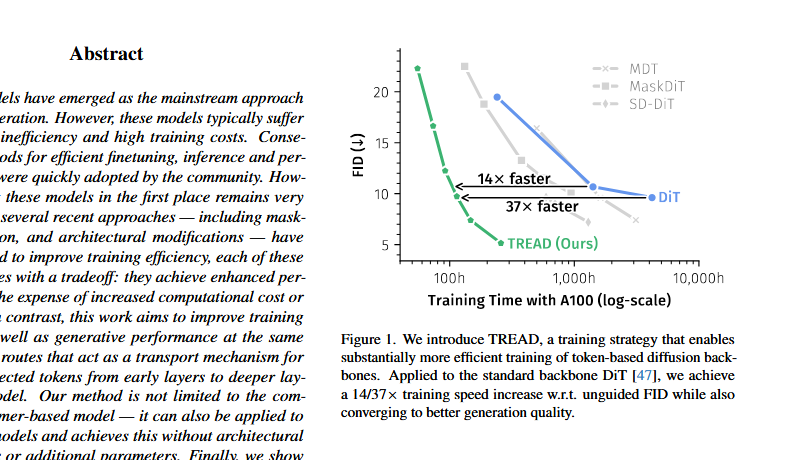
bros, DiT is wrong.
it's mathematically wrong.
it's formally wrong. there is something wrong with it
2
2
18
1,834
14 Aug 2025
Shout out for Doji!

Introducing Look Studio.
Style looks from scratch with 1M products from designer brands - including shoes, multiple layers and more.
Reply for an invite.
3
313
Xianghao Kong retweeted

8 Jul 2025
Excited to introduce Reka Vision, an agentic visual understanding and search platform. Transform your unstructured multimodal data into insights and actions.
7
24
116
485,863
Xianghao Kong retweeted

18 Jun 2025
Introducing our V1 Video Model. It's fun, easy, and beautiful. Available at 10$/month, it's the first video model for *everyone* and it's available now.
359
562
3,902
1,949,747
Xianghao Kong retweeted

12 Jun 2025
@cveu_workshop starting at 1:00 PM, 207 A-D.
12 Jun 2025

Very happy to be in Music City for #CVPR2025 My lab is presenting 7 papers, 4 selected as highlights. My amazing students @IrohXu @zixuan_huang @Wenqi_Jia @bryanislucky Xiang Li @fionakryan and postdoc Sangmin Lee are here! @siebelschool @uofigrainger

1
4
578
11 Jun 2025
Heading to Nashville 🎸 for @CVPR (06/11 - 06/16)!
Always excited to catch up with old friends and make new connections. Let’s grab a coffee ☕️ or chat about diffusion models, post-training, or just life!
#CVPR2025 #Diffusion #GenerativeAI #Nashville
3
298
Xianghao Kong retweeted

6 Jun 2025
you're now closer to the year 2050 than the year 2000
55
88
1,172
79,181
Xianghao Kong retweeted

7 Mar 2025
📢 Our paper "Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer" has been accepted to hashtag#MLSys2025, taking place May 12-15! Excited to share our research at the intersection of machine learning and systems in San Jose, CA. 🎉
Check out the full program here: lnkd.in/ecyzGbwJ
hashtag#MLSys hashtag#MachineLearning hashtag#Systems hashtag#Conference

3
8
1,294
Xianghao Kong retweeted

27 Feb 2025
Delighted to see MicroDiffusion paper being accepted at CVPR.
Checkout the code and models if you are looking for an extremely low cost setup for latent diffusion models.
12 Jan 2025

Following fully open-source philosophy, we’ve released the official training code, data code, and model ckpts for our micro-budget training of diffusion models from scratch (MicroDiTs).
Now anyone can train a Stable Diffusion v1/v2-quality model from scratch in just 2.5 days using 8 H100 GPUs (<$2000 cost).
Github: github.com/SonyResearch/micr…
Checkpoints: huggingface.co/VSehwag24/Mic…
@SonyAI_global 1/3

2
7
69
3,598
Xianghao Kong retweeted

23 Jan 2025
Our **Flow Matching Tutorial** from #NeurIPS2024 is now publicly available: neurips.cc/virtual/2024/tuto…
@helibenhamu @RickyTQChen
4
89
521
29,483
Xianghao Kong retweeted
12 Jan 2025
Following fully open-source philosophy, we’ve released the official training code, data code, and model ckpts for our micro-budget training of diffusion models from scratch (MicroDiTs).
Now anyone can train a Stable Diffusion v1/v2-quality model from scratch in just 2.5 days using 8 H100 GPUs (<$2000 cost).
Github: github.com/SonyResearch/micr…
Checkpoints: huggingface.co/VSehwag24/Mic…
@SonyAI_global 1/3
15
101
578
60,710