
462 Photos and videos














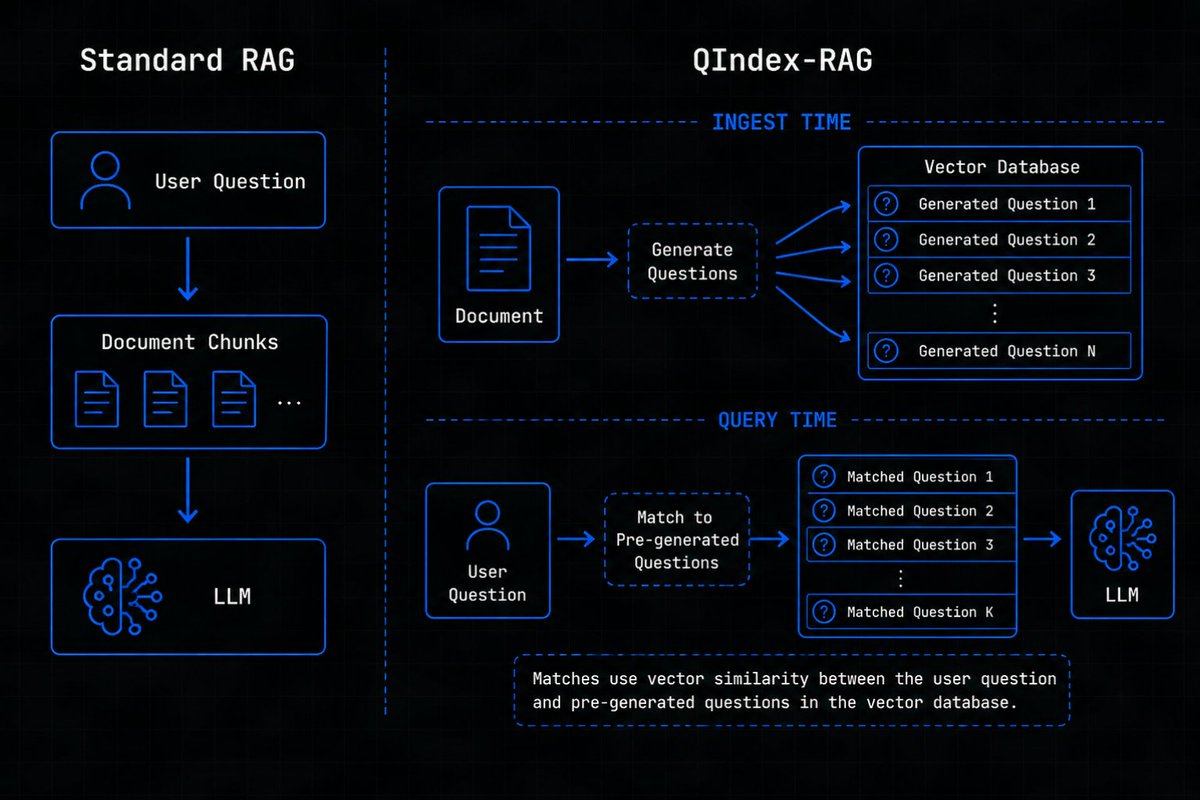
Most RAG systems work like this:
→ User asks question
→ Retrieve similar chunks
→ Send to LLM
→ Generate answer
The problem: question-to-chunk similarity is often weak.
Example: “How do I reset my password?”
That may not semantically match a documentation paragraph talking about authentication flows, account settings, or credential recovery.
So I’m experimenting with a different retrieval approach:
At ingest time: generate possible questions each page can answer.
At query time: match question-to-question instead of question-to-chunk.
Early results:
→ significantly better retrieval relevance
→ fewer unnecessary tokens sent to the LLM
→ much cleaner context windows
Calling this approach: QIndex-RAG.
Still testing and refining it, but the retrieval quality improvement is already noticeable.
2
278
Anthropic just dropped Claude Fable 5 and
it's not an Opus update
it's a whole new tier above it.
Same brain as Mythos 5, but generally available.
Opus 4.8 was the ceiling.
Fable just moved it.
The "most intelligent model" race isn't close anymore
Jun 9

"this model is too powerful to release"
instantly made me think of Gilfoyle talking about Pied Piper in Silicon Valley
except this time it wasn't fiction
Anthropic reportedly held Mythos back because of what it could do
months later, Fable is live
which means we're now living in a world where AI companies build the capability first...
and figure out how to safely release it afterwards
that's both exciting and a little terrifying
if Gilfoyle were real, would he be building with Fable...
or trying to stop everyone else from using it?

1
1
142
AI removes the barrier to becoming a software developer.
If you know the basics, data flow, and a little about databases, that's enough to launch your first startup.
12
4 years | No degree
No team | No funding
Just me, building real products that real people use.
- 50k monthly users.
- 1.2M monthly queries.
- 5 OSS tools.
- A RAG architecture I designed myself.
- GPT-5 pipelines in production.
I'm looking for a role or contract work where building fast and owning problems actually matters.
If that sounds useful to you or someone you know, My portfolio is yrj.fysk.dev
1
1
165
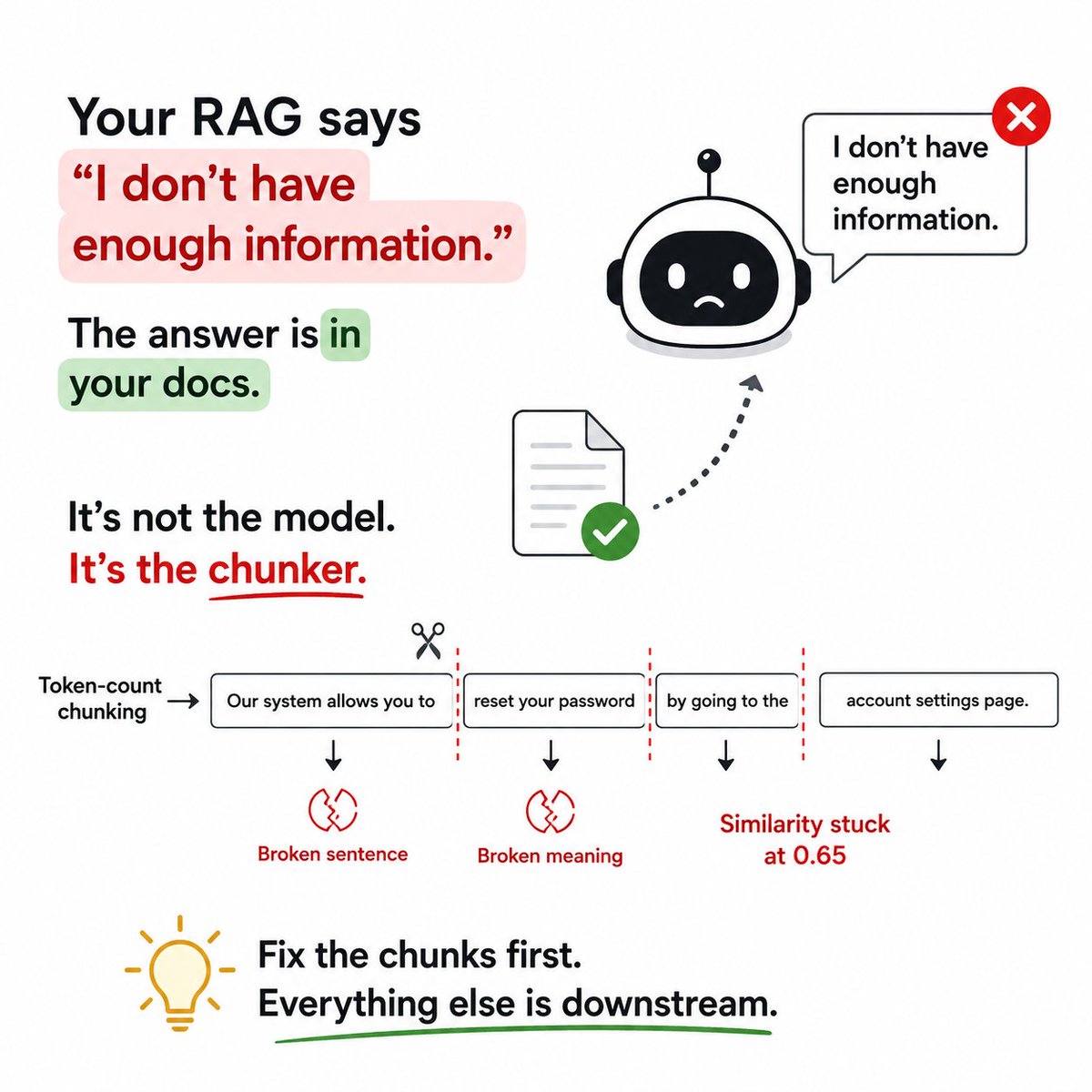
Why your RAG fails?

Your RAG says:
"I don't have enough information."
But the answer is sitting in your docs.
One reason?
Chunking.
Most chunkers split by token count.
That often breaks sentences, sections, and context.
Broken context → weaker embeddings → poor retrieval.
Before changing models, prompts, or embeddings, inspect your chunks.
A lot of RAG problems start there.
Learned this today while building SupportGPT - an AI support widget that actually knows your docs.
Building in public.
1
2
57
Your RAG says:
"I don't have enough information."
But the answer is sitting in your docs.
One reason?
Chunking.
Most chunkers split by token count.
That often breaks sentences, sections, and context.
Broken context → weaker embeddings → poor retrieval.
Before changing models, prompts, or embeddings, inspect your chunks.
A lot of RAG problems start there.
Learned this today while building SupportGPT - an AI support widget that actually knows your docs.
Building in public.
58

Techies can do anything they think

25
Secret Keys need to be Secret
Jun 3
never store private keys in plain .env files
@PatrickAlphaC keeps saying this for a reason
but people still do it because the safer workflow is usually clunky
so i built vaultenv
a small npm package to store secrets encrypted locally, then load them into your shell only when needed
npm install -g codeswithroh/vaultenv
2
3
147
When you work with LLM APIs.
Before setting up the Response structure
Setup for request data, so LLM can get only the information that needed.
Otherwise
Garbage In, Garbage Out
Generating a simple tweet was costing us >>>>>>> 18,000 tokens.
The prompt: ~400 tokens.
The tweet: 70 tokens.
So where did the other 17,500 go?
// GPT-5 Nano is a reasoning model. max_output_tokens doesn't just cap the output.
It caps reasoning output combined.
The model was spending 17,000 tokens thinking before writing 70.
The fix wasn't a bigger cap.
It was a dynamic one:
>> inputTokens = ceil(promptChars / 4.5)
>> reasoning = max(4000, inputTokens × 5)
>> cap = outputBudget reasoning
Why ×5?
Measured in production:
1,737 input → 7,273 reasoning tokens
That's x4.2, We use 5 for safety margin.
Short videos = small cap.
Long videos = large cap.
No waste. No truncation.
Reasoning models need reasoning budgets.
Not output limits.

3
19
Generating a simple tweet was costing us >>>>>>> 18,000 tokens.
The prompt: ~400 tokens.
The tweet: 70 tokens.
So where did the other 17,500 go?
// GPT-5 Nano is a reasoning model. max_output_tokens doesn't just cap the output.
It caps reasoning output combined.
The model was spending 17,000 tokens thinking before writing 70.
The fix wasn't a bigger cap.
It was a dynamic one:
>> inputTokens = ceil(promptChars / 4.5)
>> reasoning = max(4000, inputTokens × 5)
>> cap = outputBudget reasoning
Why ×5?
Measured in production:
1,737 input → 7,273 reasoning tokens
That's x4.2, We use 5 for safety margin.
Short videos = small cap.
Long videos = large cap.
No waste. No truncation.
Reasoning models need reasoning budgets.
Not output limits.
1
4
85
🥳 Finally Shipped CreatorJot-v2
creatorjot.com
What's new:
- SEO content in one click
YouTube titles (A/B/C), description, tags, chapters & keywords, all from your video
- Switched to GPT5 for faster and better response
- Dynamic reasoning token analyzer
- More credits in same plan (120 to 500)
- Removed the onboarding wall
- Full mobile layout on the SEO tab
--
Been building quietly for weeks. This one feels like a real step up.
Tomorrow I'll share my learning from this

3
6
100
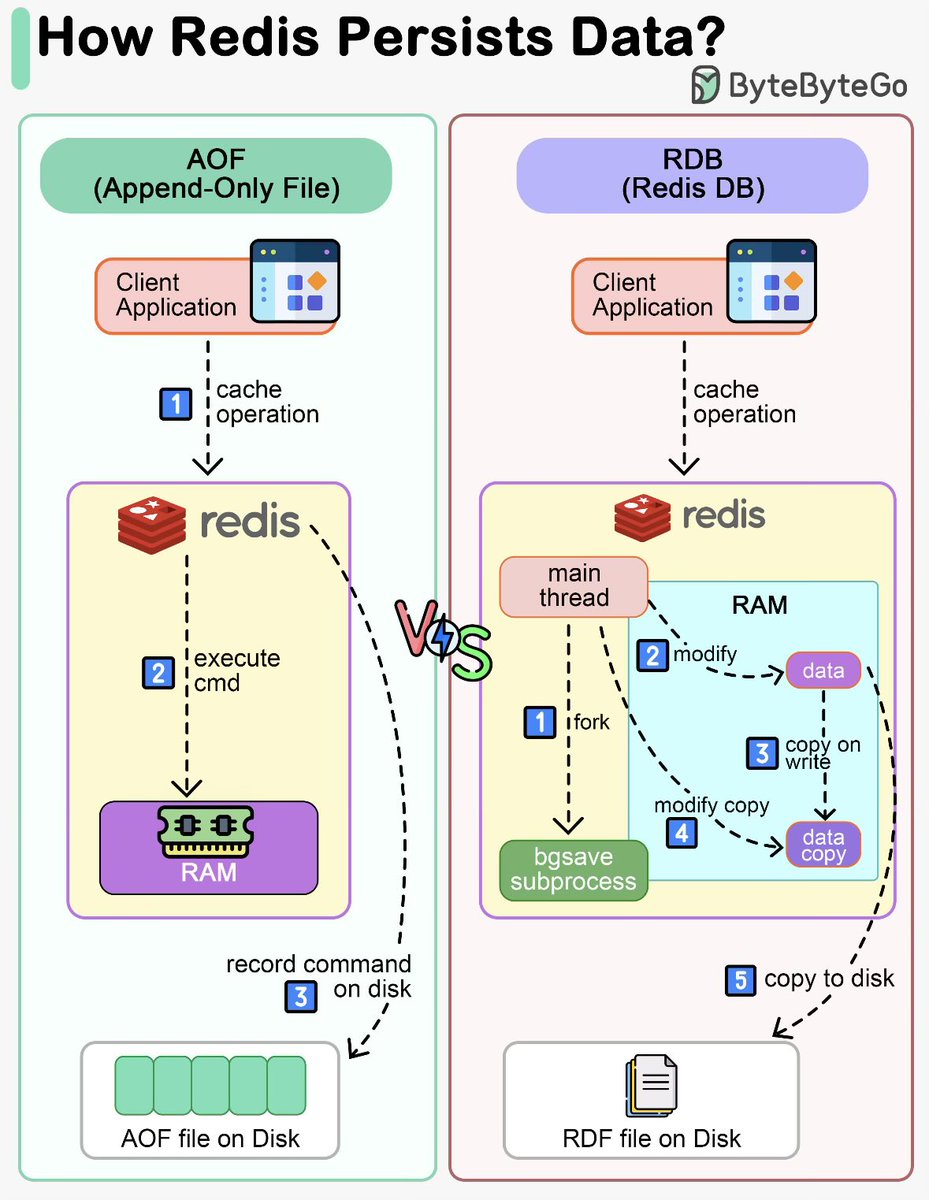
This is how Redis works
May 27

Redis stores data in memory but also supports persistence to avoid data loss.
RDB snapshots
Periodic backups to disk for fast recovery.
AOF (Append Only File)
Logs every write operation and replays them after restart.
Many setups use both RDB and AOF for performance and durability.
1
1
104
Spent 8 months building PixEarn.
$0 revenue.
Built CreatorJot.com on the side.
Tomorrow it ships the feature I actually care about.
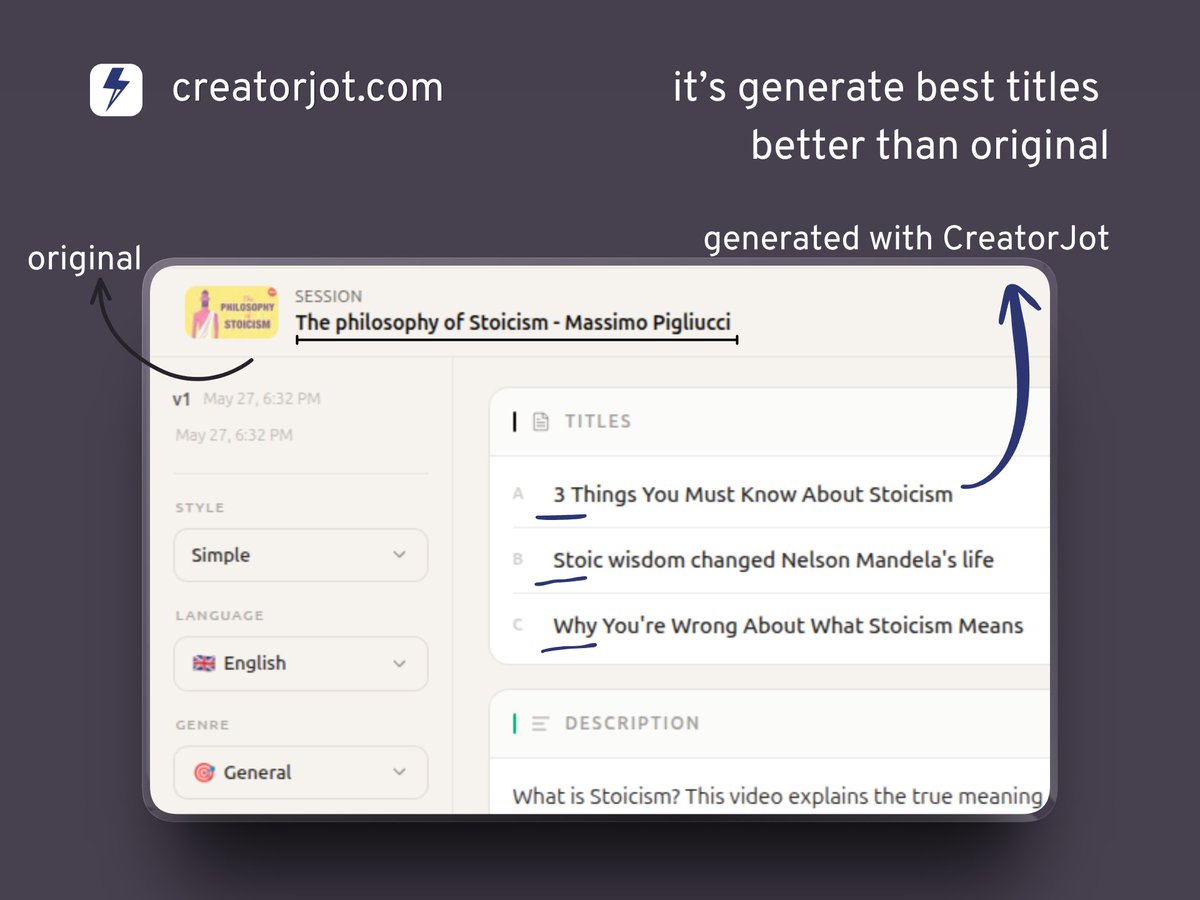
You make a YouTube video.
It gets zero views.
Not because it's bad. Because the title didn't rank.
Every SEO tool guesses based on your topic. CreatorJot reads your actual
- video script
- timestamps
- spoken content
And generates titles, descriptions, tags, and keywords from what's literally in it.
Not guesses. Evidence.
Live tomorrow at creatorjot.com
Drop your YouTube link and see what it finds.
5
89
OMG! 🤯
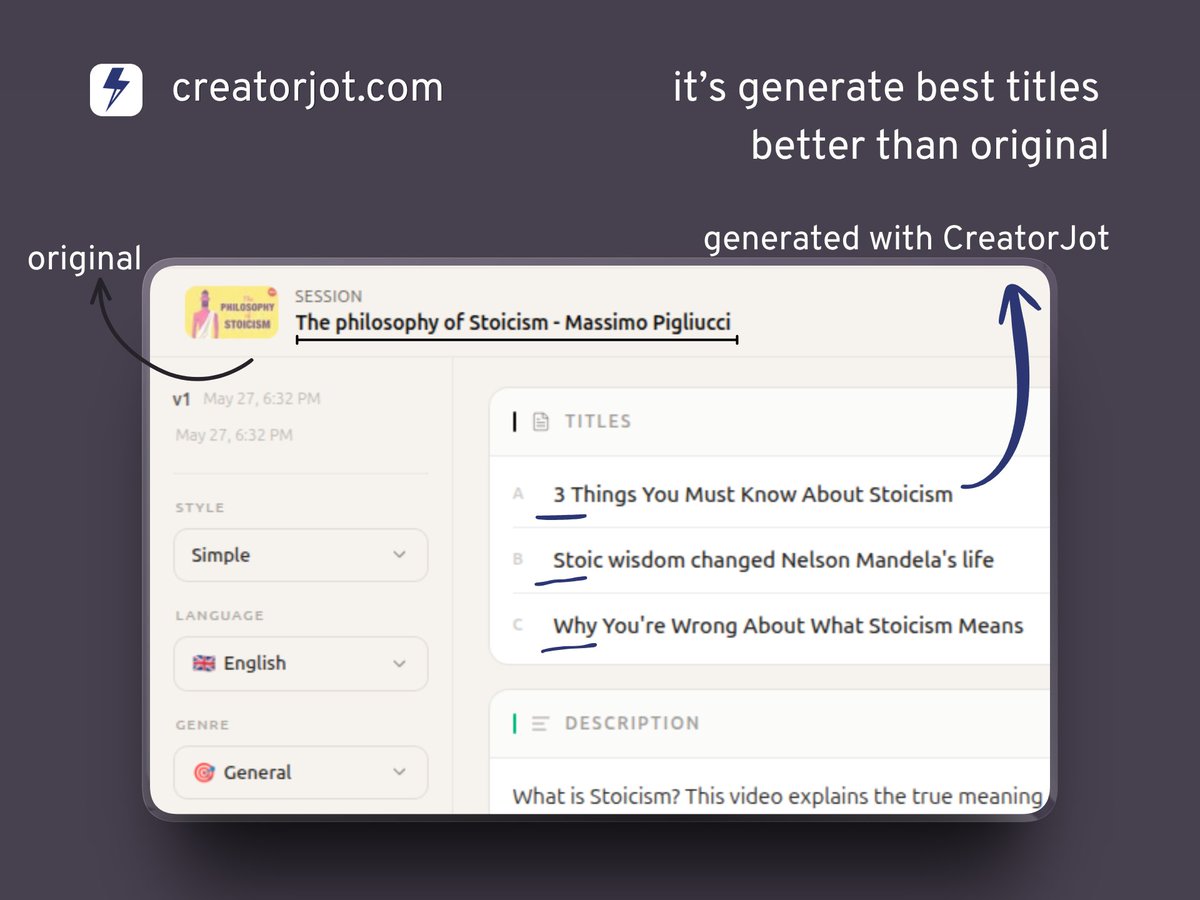
I tested CreatorJot.com on a real YouTube video...
Titles it generated were honestly better than what most creators spend hours writing manually👀
Launching in 2 days (29th may)
It generates:
- Viral-ready titles
- SEO descriptions
- Keywords
- Tags
- Full chapters with accurate timestamps
Instead of spending 2-3 hours optimizing one upload...
Generate everything in seconds.
Dropping on May 29
#BuildInPublic
2
3
143

Today we announced Workshop – a solution for launching sandboxed development environments in Ubuntu with a single command.
Spend less time on configuring your environment: with just a few lines of YAML, you’ve got a reproducible environment you can use across machines.
Find out how it works at: discourse.ubuntu.com/t/intro…
64
180
1,413
137,875
😐 Most Claude Code users waste tokens like crazy.
Every new terminal session:
- re-explaining the codebase
- reloading context
- rebuilding momentum
Better workflow:
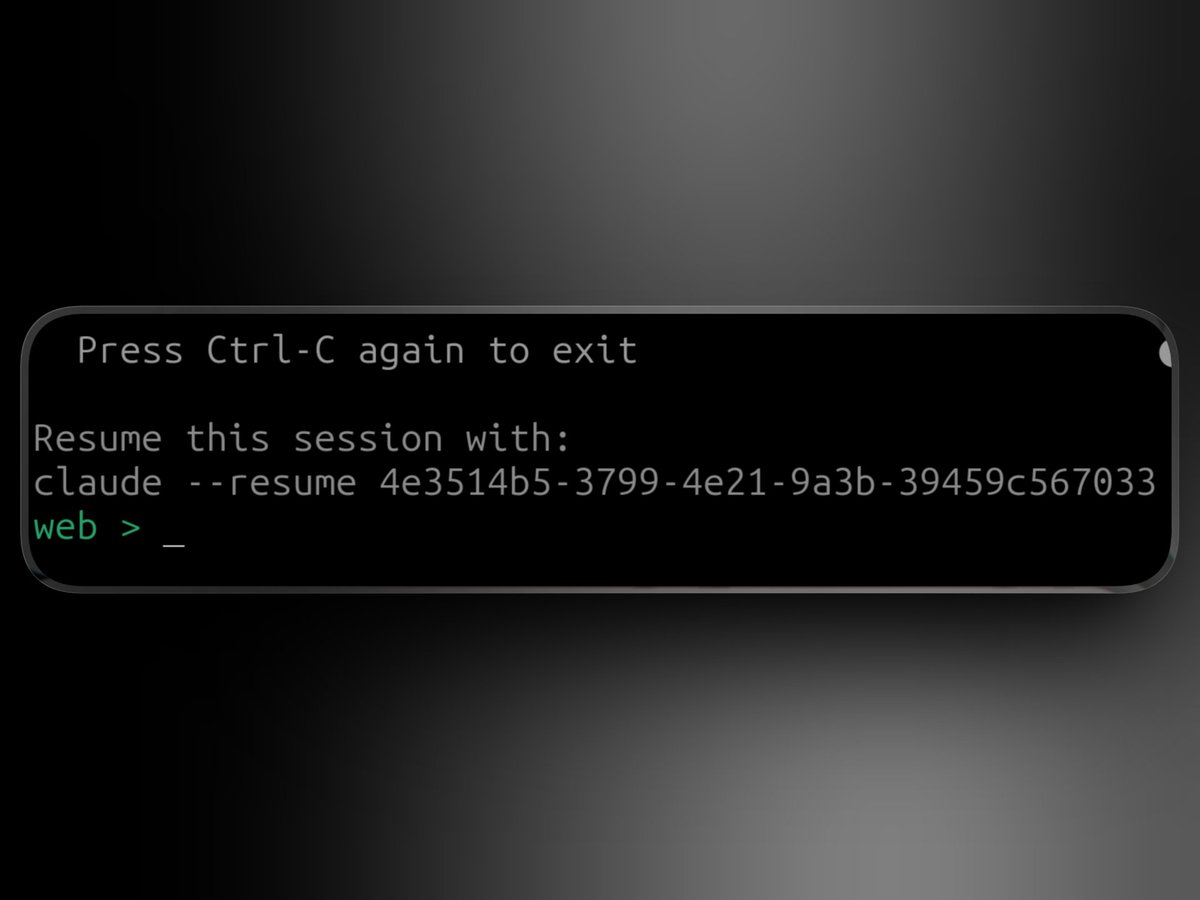
1. Before closing terminal:
· copy session ID
2. Resume instantly:
· claude --resume SESSION_ID
3. If context gets bloated:
· /compact
It compresses the session so Claude keeps context without carrying unnecessary token weight.
4. Reduce reasoning cost:
· /effort medium
--
Usually the best quality/speed/token tradeoff for coding.
Most people optimize prompts.
Few optimize workflow.
2
4
100