
69 Photos and videos







GeoPicker v1.6.0 is out! support
@GdalOrg
v3.7.0 github.com/opengeo-tech/GeoP… #GeoPicker #geospatial #opensource #webgis #nodejs #fastify #gdal
1
70
17
Installing Updating to GDAL 3.11.0 on Ubuntu: A Ground Up Rewrite #GDAL datacommons.substack.com/p/i…
16
Stef Cud retweeted

8 Jul 2025
🚀 GeoSolutions is headed to #FOSS4G Europe 2025 in Mostar as a ✨ Gold Sponsor ✨! Join us July 14–20 for talks, workshops & a chance to meet our developers.
We'll be diving into #GeoServer, #GeoNode, #MapStore and what’s cooking behind the scenes!
Details 👉 geosolutionsgroup.com/blog/f…
#OSGeo #FOSS4GEU #FOSS4G #OpenSourceGIS

3
6
595
Geospatial Developer Curriculm Vitae opengeo.tech/stefano-cudini #gis #nodejs #javascript #geospatial #programmer #developer #opensource #js #CurriculmVitae #Resume
87
Stef Cud retweeted

12 Sep 2024
GeoServer 3 Crowdfunding campaign launched: geoserver.org/behind the%2…
"Consortium members @camptocamp, @geosolutions_it , and @geocat_bv have a long-standing history of supporting and contributing to GeoServer and are fully committed to the success of this migration."

ALT GeoServer 3 Crowdfunding Campaign
8
17
1,178
Awesome Italia Remote
A list of 341 remote-friendly or full-remote companies that targets Italian talents. github.com/italiaremote/awes…… by @alessmarinoac & #edoardocostantini
43
GeoPicker: not only another simple elevation service. github.com/opengeo-tech/GeoP…
Upload file and return elevated #geospatial #elevationservice #webgis #nodejs #gdal
2
11
26
2,642
Stef Cud retweeted

23 Jan 2024
atuinsh / atuin: ✨ Magical shell history ★15018 github.com/atuinsh/atuin
10
51
4,546
Stef Cud retweeted

8 Apr 2024
Excited to share our latest work on improving LLM pre-training! 🚀 The amazing @yuzhaouoe et al. found that focusing on how pre-training sequences are composed and attended over can significantly improve the generalisation properties of LLMs on a wide array of downstream tasks, such as RAG, Knowledge-Intensive Tasks, In-Context Learning, Language Modeling, and much more! Check our pre-print, "Analysing The Impact of Sequence Composition on Language Model Pre-Training", arxiv.org/abs/2402.13991
Our approaches leverage intra-document causal masking and concatenation of related documents, which have the effect of reducing interference from unrelated texts while improving the pre-training dynamics and generalisation properties. We also propose a novel retrieval-based pre-training sequence construction method, refining the model's ability to learn from context and retain knowledge effectively.
All details are available in our paper, "Analysing The Impact of Sequence Composition on Language Model Pre-Training": arxiv.org/abs/2402.13991

1
25
105
10,856
17 Apr 2024

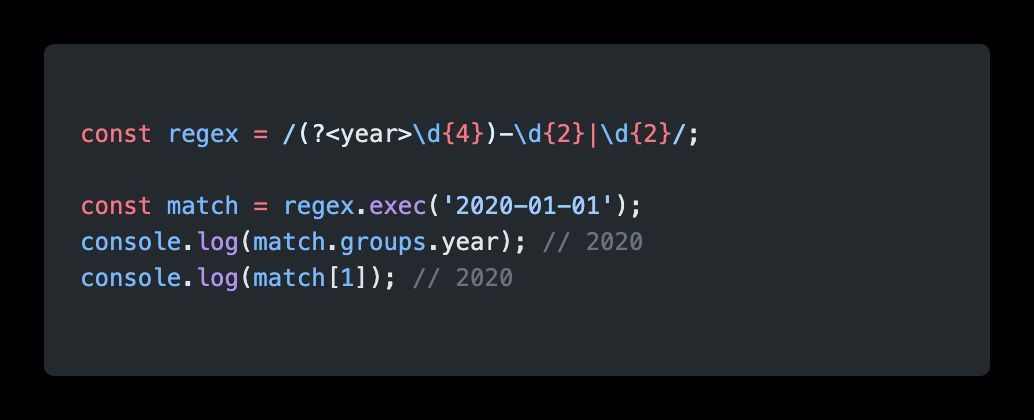
I know I'm late to the party, but I didn't know that regex supports named capturing groups!
51