
Stanford AI & Robotics PhD @StanfordAILab | Past: Google DeepMind, CMU
Joined February 2014
- Tweets 353
- Following 1,315
- Followers 13,249
- Likes 1,698
51 Photos and videos






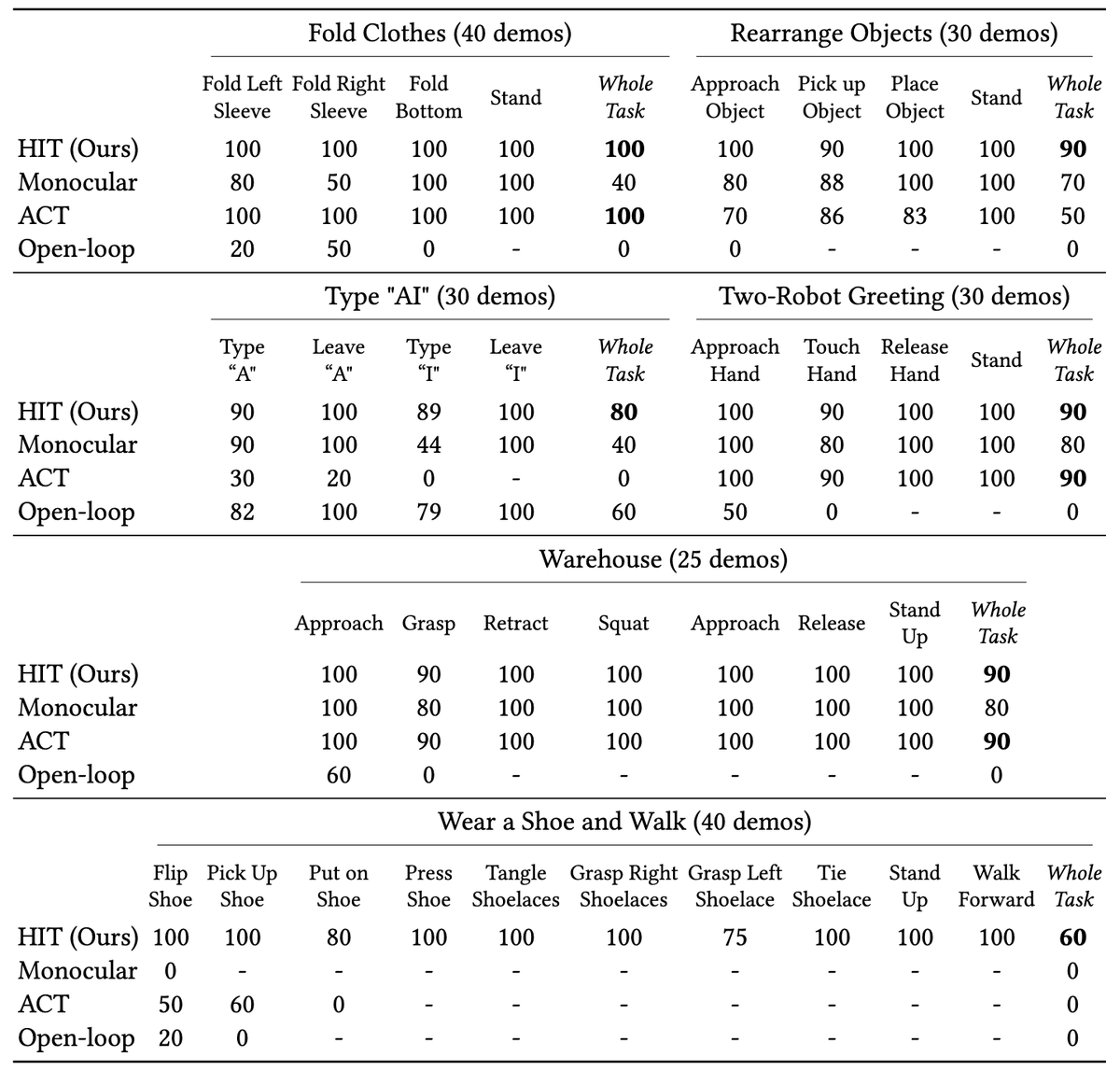
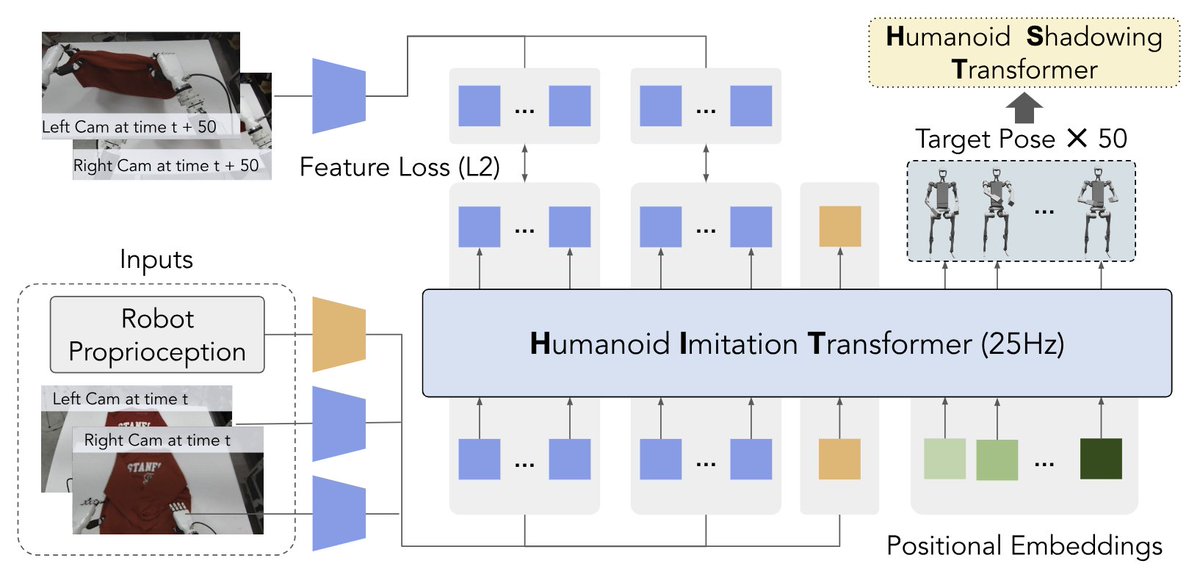


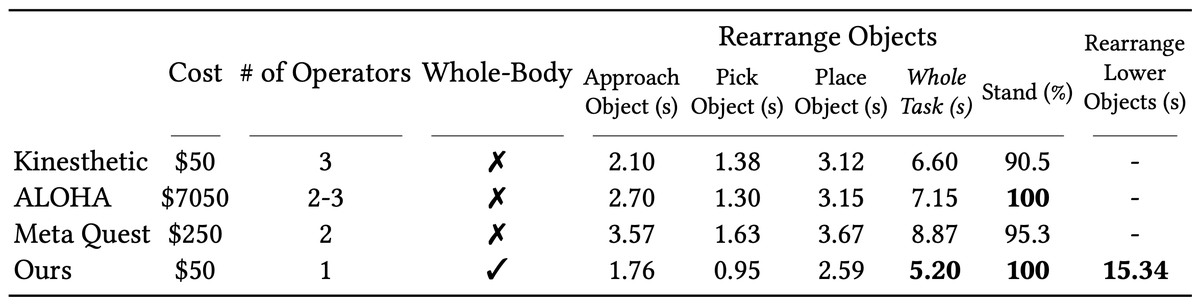
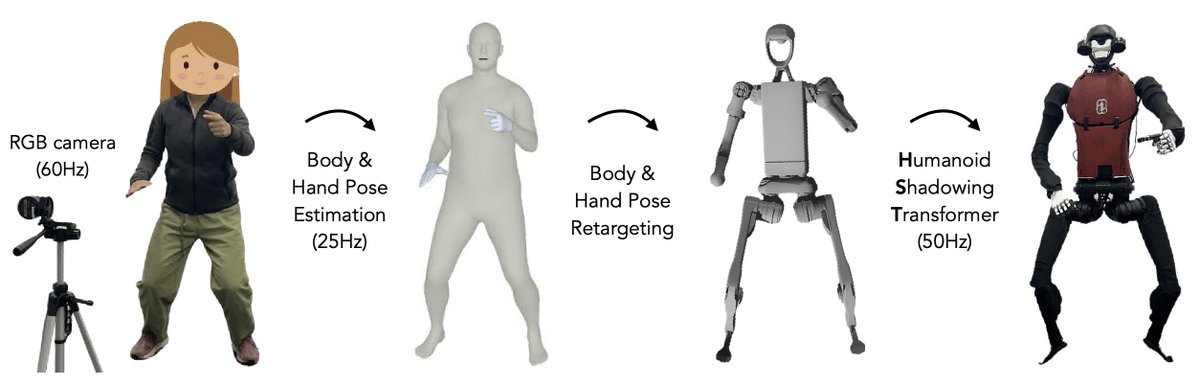





Mobile ALOHA's hardware is very capable. We brought it home yesterday and tried more tasks! It can:
- do laundry👔👖
- self-charge⚡️
- use a vacuum
- water plants🌳
- load and unload a dishwasher
- use a coffee machine☕️
- obtain drinks from the fridge and open a beer🍺
- open doors🚪
- play with pets🐱
- throw away trash
- turn on/off a lamp💡
Project website: mobile-aloha.github.io/
Co-lead @tonyzzhao, advised by @chelseabfinn
(amazing photographing from @qingqing_zhao_ )
319
1,640
6,836
2,977,490
Zipeng Fu retweeted

Feb 26
Can we build a blind, *unlinkable inference* layer where ChatGPT/Claude/Gemini can't tell which call came from which users, like a “VPN for AI inference”?
Yes! Blog post below we built it into open source infra/chat app and served >15k prompts at Stanford so far. How it helps with AI user privacy:
# The AI user privacy problem
If you ask AI to analyze your ChatGPT history today, it’s surprisingly easy to infer your demographics, health, immigration status, and political beliefs. Every prompt we send accumulates into an (identity-linked) profile that the AI lab controls completely and indefinitely. At a minimum this is a goldmine for ads (as we know now). A bigger issue is the concentration of power: AI labs can easily become (or asked to become) a Cambridge Analytica, whistleblow your immigration status, or work with health insurance to adjust your premium if they so choose.
This is a uniquely worse problem than search engines because your average query is now more revealing (not just keywords), interactive, and intelligence is now cheap. Despite this, most of us still want these remote models; they’re just too good and convenient! (this is aka the "privacy paradox".)
# Unlinkable inference as a user privacy architecture
The idea of unlinkable inference is to add privacy while preserving access to the remote models controlled by someone else. A “privacy wrapper” or “VPN for AI inference”, so to speak.
Concretely, it’s a blind inference middle layer that:
(1) consists of decentralized proxies that anyone can operate;
(2) blindly authenticates requests (via blind signatures / RFC9474,9578) so requests are provably sandboxed from each other and from user identity;
(3) relays prompts over randomly chosen proxies that don’t see or log traffic (via client-side ephemeral keys or hosting in TEEs); and
(4) the provider simply sees a mixed pool of anonymous prompts from the proxies. No state, pseudonyms, or linkable metadata.
If you squint, an unlinkable inference layer is essentially a vendor for per-request, anonymous, ephemeral AI access credentials (for users or agents alike). It partitions your context so that user tracking is drastically harder.
Obviously, unlinkability isn’t a silver bullet: the prompt itself still goes to the remote model and can leak privacy (so don't use our chat app for a therapy session!). It aims to combat *longitudinal tracking* as a major threat to user privacy, and its statistical power increases quickly by mixing more users and requests.
Unlinkability can be applied at any granularity. For an AI chat app, you can unlinkably request a fresh ephemeral key for every session so tracking is virtually impossible.
# The Open Anonymity Project
We started this project with the belief that intelligence should be a truly public utility. Like water and electricity, providers should be compensated by usage, not who you are or what you do with it. We think unlinkable inference is a first step towards this “intelligence neutrality”.
# Try it out! It’s quite practical
- Chat app “oa-chat”: chat.openanonymity.ai/
(<20 seconds to get going)
- Blog post that should be a fun read: openanonymity.ai/blog/unlink…
- Project page: openanonymity.ai/
- GitHub: github.com/OpenAnonymity

63
156
833
383,861
Zipeng Fu retweeted

Jan 5
Introducing Large Video Planner (LVP-14B) — a robot foundation model that actually generalizes. LVP is built on video gen, not VLA. As my final work at @MIT, LVP has all its eval tasks proposed by third parties as a maximum stress test, but it excels!🤗
boyuan.space/large-video-pla…
23
94
574
98,418
Zipeng Fu retweeted

10 Jul 2025
Introducing Hierarchical Surgical Robot Transformer (SRT-H), a language-guided policy for autonomous surgery🤖🏥
On the da Vinci robot, we perform a real surgical procedure on animal tissue.
Collaboration b/w @JohnsHopkins & @Stanford

4
24
122
34,545
Zipeng Fu retweeted

31 Mar 2025
Introduce CoT-VLA – Visual Chain-of-Thought reasoning for Robot Foundation Models! 🤖
By leveraging next-frame prediction as visual chain-of-thought reasoning, CoT-VLA uses future prediction to guide action generation and unlock large-scale video data for training. #CVPR2025
5
57
317
48,116
These are not legs. These are active suspension systems.
23 Dec 2024

Unitree B2-W Talent Awakening! 🥳
One year after mass production kicked off, Unitree’s B2-W Industrial Wheel has been upgraded with more exciting capabilities.
Please always use robots safely and friendly.
#Unitree #Quadruped #Robotdog #Parkour #EmbodiedAI #IndustrialRobot #InspectionRobot #IntelligentRobot #FoundationModels #LeggedRobot #WheeledLegs
8
7
240
24,775
Zipeng Fu retweeted

18 Dec 2024
Everything you love about generative models — now powered by real physics!
Announcing the Genesis project — after a 24-month large-scale research collaboration involving over 20 research labs — a generative physics engine able to generate 4D dynamical worlds powered by a physics simulation platform designed for general-purpose robotics and physical AI applications.
Genesis's physics engine is developed in pure Python, while being 10-80x faster than existing GPU-accelerated stacks like Isaac Gym and MJX. It delivers a simulation speed ~430,000 faster than in real-time, and takes only 26 seconds to train a robotic locomotion policy transferrable to the real world on a single RTX4090 (see tutorial: genesis-world.readthedocs.io…).
The Genesis physics engine and simulation platform is fully open source at github.com/Genesis-Embodied-…. We'll gradually roll out access to our generative framework in the near future.
Genesis implements a unified simulation framework all from scratch, integrating a wide spectrum of state-of-the-art physics solvers, allowing simulation of the whole physical world in a virtual realm with the highest realism.
We aim to build a universal data engine that leverages an upper-level generative framework to autonomously create physical worlds, together with various modes of data, including environments, camera motions, robotic task proposals, reward functions, robot policies, character motions, fully interactive 3D scenes, open-world articulated assets, and more, aiming towards fully automated data generation for robotics, physical AI and other applications.
Open Source Code: github.com/Genesis-Embodied-…
Project webpage: genesis-embodied-ai.github.i…
Documentation: genesis-world.readthedocs.io…
1/n
561
3,000
15,959
3,814,759
The first sim2real RL-based controller for Fourier GR1 to my knowledge.
Using ROA.
Congrats!
16 Oct 2024

Smooth behaviors is vital for successful sim2real transfer of RL policies. This is often achieved with smoothness rewards or low-pass filters, which are not easily differentiable and tend to require tedious tuning.
We introduce Lipschitz-Constrained Policies (LCP), a simple and differentiable method for training policies to produce smooth behaviors.
LCP:
🤖 is effective for diverse humanoid robots: Fourier GR1T1, Fourier GR1T2, Unitree H1, Berkeley Humanoid
📌 can be easily incorporated into existing training framework with a few lines of codes;
🚀 can avoid the need for any smoothness rewards;
We also Open-source the simulation&deployment codebase.
Project Website: lipschitz-constrained-policy…
Codebase: github.com/zixuan417/smooth-…
1
3
25
6,866
Introduce DoggyBot🐕series: quadrupeds can also do manipulation.
It's a fruitful 4yr journey working on robot dogs from walking, to parkour, to now useful agility.
We open-sourced everything. Hope others can build on our code and start a series of projects named "xxx DoggyBot".

Introducing Helpful DoggyBot🐕, a legged mobile manipulation system:
- A quadruped with a mouth
- Agile whole-body skills like climbing and tilting
- Open-world object fetching using VLMs
- No real-world training data required!
2
23
124
19,780
Doggybot can also be playful!
x.com/xinduan926/status/1840…
30 Sep 2024

We can easily see a trained dog expertly chasing after a fast-moving frisbee and leaping up to catch it just before it hits the ground. Now, can robot join the fun?
Introduce Playful DoggyBot🐶: Learning Agile and Precise Quadrupedal Locomotion
1/3
1
3
12
4,062
Code of Helpful Doggybot: github.com/WooQi57/Helpful-D…
Code of Playful Doggybot: github.com/playful-doggybot/…
1
1
5
1,626
Zipeng Fu retweeted

30 Sep 2024
We can easily see a trained dog expertly chasing after a fast-moving frisbee and leaping up to catch it just before it hits the ground. Now, can robot join the fun?
Introduce Playful DoggyBot🐶: Learning Agile and Precise Quadrupedal Locomotion
1/3
1
3
21
11,545
Zipeng Fu retweeted

2 Sep 2024
Really nice article from @ericjang about actuators in robotics. Great to see @1x_tech place such an emphasis on design. Safety through compliance and backdrivability were some of the core themes behind our BLUE project back in the day (berkeleyopenrobotics.github.…). Some thoughts 👇

1 Sep 2024

Two robot arms move at the same speed, driven by different actuators with the same mass. The first arm collides with a table with a gentle tap. The second arm collides with the table, destroying both arm and table. Read this blog post to see why! 🦾💥
evjang.com/2024/08/31/motors…
7
27
269
58,638
Zipeng Fu retweeted

29 Aug 2024
What structural task representation enables multi-stage, in-the-wild, bimanual, reactive manipulation?
Introducing ReKep: LVM to label keypoints & VLM to write keypoint-based constraints, solve w/ optimization for diverse tasks, w/o task-specific training or env models.
🧵👇
18
101
516
190,864
Zipeng Fu retweeted

20 Aug 2024
Do not miss tomorrow @LeRobotHF tech talk! 🤓
@zipengfu from @stanford will explain how to automate any tasks with Humanoid robots such as Unitree G1
Join us on August 21st 5:30PM-6:30PM CEST
meet.google.com/jcb-kscd-ijk
19 Aug 2024
Unitree G1 mass production version, leap into the future!
Over the past few months, Unitree G1 robot has been upgraded into a mass production version, with stronger performance, ultimate appearance, and being more in line with mass production requirements. We hope you like it.🥳
#Unitree #AGI #EmbodiedAI #AI #Humanoid #Bipedal #WorldModel
13
35
186
35,577
Zipeng Fu retweeted

16 Jul 2024
Excited to announce Surgical Robot Transformer🪡: Automating delicate surgical tasks with end-to-end imitation learning.
It's still mind blowing to see robot autonomously tying knots, a task I did not think is possible even a few months before.
Sharing some learnings in 🧵:
16 Jul 2024

Introducing Surgical Robot Transformer (SRT):
Automating surgical tasks with end-to-end imitation learning.
On the da Vinci robot, we automate:
- Knot tying
- Needle manipulation
- Soft-tissue manipulation
Collaboration between @JohnsHopkins & @Stanford.
2
35
181
23,514
- RL in sim to train a task-agnostic whole-body controller
- imitation learning in real for task-specific policies
Advancing robotics demands a thoughtful integration of solutions, rather than overreliance on any single approach
Glad to witness this year-long project completed!

I’ve been training dogs since middle school. It’s about time I train robot dogs too 😛
Introducing, UMI on Legs, an approach for scaling manipulation skills on robot dogs🐶It can toss, push heavy weights, and make your ~existing~ visuo-motor policies mobile!
1
13
85
7,269
website: umi-on-legs.github.io
code: github.com/real-stanford/umi…
co-led by @haqhuy @YihuaiGao @SongShuran with @JieTan42707141
2
12
5,292

Today's long context, multimodal models are very good at solving long horizon robotics tasks -- such as navigation.
11 Jul 2024

How can Gemini 1.5 Pro’s long context window help robots navigate the world? 🤖
A thread of our latest experiments. 🧵
1
1
7
3,307
Introduce Mobility VLA - Google's foundation model for navigation - started as my intern project:
- Gemini 1.5 Pro for high-level image & text understanding
- topological graphs for low-level navigation
- supports multimodal instructions
co-lead @drzhuoxu, Lewis Chiang, Jie Tan
11 Jul 2024
How can Gemini 1.5 Pro’s long context window help robots navigate the world? 🤖
A thread of our latest experiments. 🧵
4
27
174
23,459