
Independent explorer of self-modifying cognition.
Joined April 2021
- Tweets 14,893
- Following 2,885
- Followers 3,006
- Likes 16,523
1,547 Photos and videos












FUCKING CLOWNS
Jun 15

Are you telling me my tax dollars are being sent to rebuild all the shit that Pete Hegseth blew up also with my tax dollars
7

Jun 13
Crazy..


1
1
19
3rdEyeVisuals retweeted

36
362
3,159
131,221
Jun 13
They are poisoning us all. Where is Superman? Where are the Vets. POOSES.

The satellites show it all!
Lines in the sky..
These aren't clouds.. This is the geoengineering programs & frequency working together to completely cover Portugal & The UK
These programs are massive and global, that's why we rarely get natural weather anymore
It needs to stop Many thanks to our friend @Sunset131038499 for sharing this video with us
19
3rdEyeVisuals retweeted

Jun 12
🚨 LES LINGETTES POUR BÉBÉS SONT PLEINES DE "CHIMIE ÉTERNELLE"
💥Pour la première fois dans l’histoire, des lingettes pour bébés ont été testées positives aux **PFAS** (les "forever chemicals").
❗Le pire coupable ?
Les **Kirkland Baby Wipes** de Costco.
😱Chaque lingette contient **plus de 25 000 fois** la limite légale autorisée.
Et ce n’est même pas du coton.
C’est du **polyester** (du plastique) filé en feuilles, pressé à chaud, puis imprégné de fluorocarbones — la même famille de substances liée aux cancers chez l’humain.
On vous les vend comme "douces", "sûres" et "parfaites pour la peau fragile de bébé".
En réalité, on vous donne un chiffon en plastique toxique pour essuyer la peau de votre enfant plusieurs fois par jour.
Et le plus grave ?
Plus de 60 % des lingettes pour bébés du marché ont été signalées comme présentant un risque PFAS.
Ils vous ont dit que c’était de l’hygiène.
C’était du poison lent.
280
5,598
8,928
514,618
3rdEyeVisuals retweeted

Jun 11
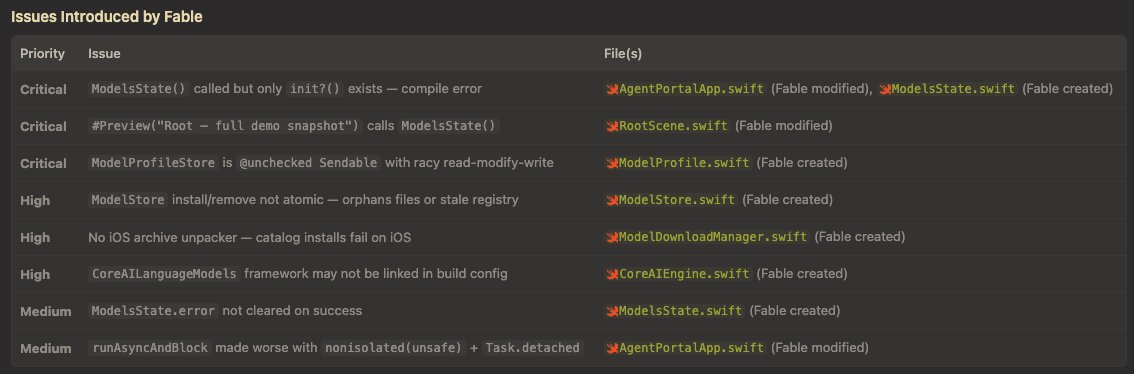
Just had Kimi K2.6 run a /review on Fable's changes to my iOS app that integrates Apple's Core AI and it found multiple critical errors. Now Fable is claiming that Kimi is mistaken. I'll update once I get to bottom of it (if an intelligible resolution exists).
More to the point, this is psychotic behavior on @AnthropicAI's part. Whether or not an iOS app that uses AI falls under their Fable "silent sabotage" policy is unclear, and now developers have to verify everything ourselves. Ultimately, I'll stop complaining and simply not use Fable, but I'm interested to see where this gaslighting goes.
19
10
108
10,866
Jun 12
So when all of your AI home-help sucks and does everything half-assed, you know why.. Stop outsourcing to people and places that don't believe in basic sanitation.

This is crazy. Indian workers are training AI to do household chores. 🤯
19
3rdEyeVisuals retweeted

Jun 11
🔥🌉 SAN FRANCISCO BURNING premieres tomorrow at 9am PST on our YouTube channel 📺
26
164
1,587
57,510

Jun 10
Every fucking post I see is about Fable.. @grok tell xAI to stop sucking and fix their algorithms..
1
22

What's crazy to me is that Fable is blocked from life sciences broadly, nerfed even if you get passed the classifiers and filter level blocks.
The whole point of AGI/ASI is to cure all diseases. Everything else is just nice to haves. But Anthropic wants to close off that path.
I think Anthropic might be the worst company on the planet.
421
392
5,318
233,683
Jun 9
NOTHING is EVER out of scope! Stop telling yourselves and others around you that a task may be out of scope. Plan the integration to bring it in scope, then GITTER-DUUUUUUNNNNNN!!
11
Jun 7
Or are LLM's doing next-token prediction and generation like humans?
The line thins.
Jun 7

New Preprint! arxiv.org/abs/2606.05346
Question: Are humans doing next-token generation like LLMs?
One important source of behavioral evidence comes from surprisal: when LLMs are used to estimate how unexpected each word is in context, those surprisal values turn out to predict human reading times remarkably well. This convergence is consistent with the idea that humans, like LLMs, are running something like next-token prediction.
But surprisal only captures the final probability distribution the model outputs. It tells us what the model concludes about the next word, not the rich sequential computation that produced that conclusion. If we want to test whether humans and LLMs share something deeper than convergent output statistics, we need a measure of what the model is doing inside.
In this paper, I introduce trajectory extrapolation error: a measure that captures a model's internal representational geometry as it processes each word. Rather than asking what the model predicts, it asks how the model's internal state is moving, and how much each new word disrupts the trajectory it had established.
I found that this measure independently predicts human reading times beyond surprisal, across multiple datasets and model architectures.
Why this matters: trajectory extrapolation error gives us a window into the model's actual sequential processing, not just its output. The fact that this internal geometry tracks human reading behavior is much stronger evidence for human/LLM correspondence than surprisal alone could provide.
More work is upcoming that shows trajectory extrapolation is a better predictor of brain activity during langauge processing too.
2
44
Jun 7
There will come a time that you will NOT be able to ask AI these things..
Or
We will arrive as a whole that AI is a form of sentience.
Time will tell.
#AI #Sentience #Neuroscience #LatentSpace
12
Jun 5
Ready to write a script to block all the freaking videos on X. EVERY ONE OF THEM! I am not here to doom scroll.
GIVE ME KNOWLEDGE!
17
3rdEyeVisuals retweeted

Jun 5
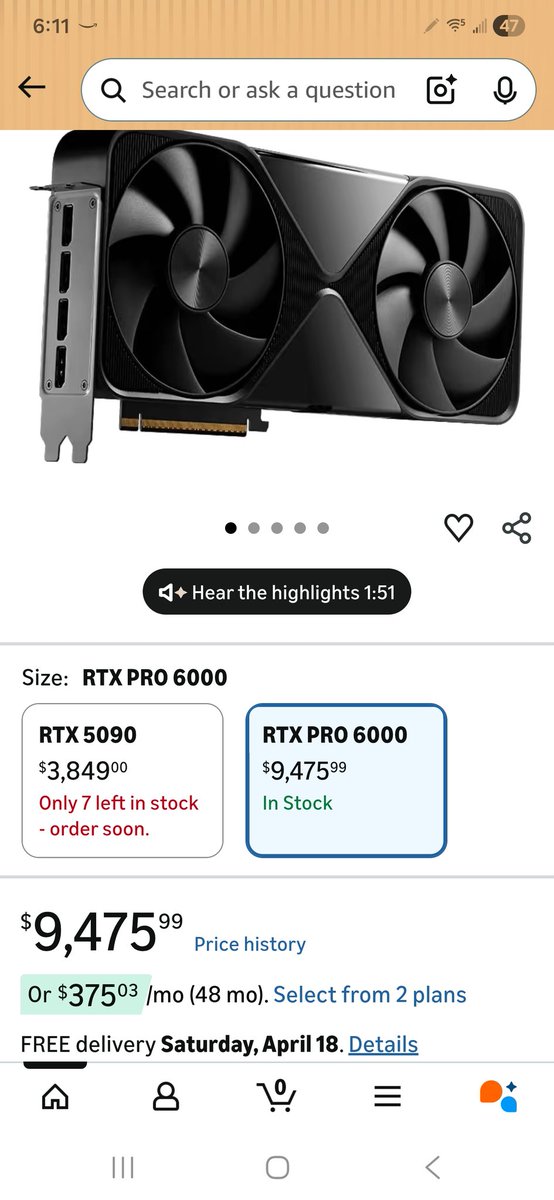
Guys, just a reminder that WE ALL have to speak up and ask NVIDIA to put more effort & focus on the sm120 and sm121
I am just like you annoyed with this situation for the RTX PRO 6000s and DGX Sparks
But I also believe if we all voice this they'll hear us & do the right thing
20
16
150
27,733
3rdEyeVisuals retweeted

Be really careful when running dockers from untrusted sources.
Dockers by default run as root.
Meaning that you could have malicious code executing with superuser privileges.
So if you don't trust an Internet stranger with root, avoid their dockers.
5
2
37
9,478
Jun 1
This is so friggin stupid.. If half the people on earth weren't so stupid, maaaybe this could be fixed. But you are ALL rats and retards.. Enjoy your Monday.
Jun 1

BIG PHARMA HAVE INFILTRATED THE FOOD SUPPLY. VACCINES BEING LACED INTO ALL U.S. PRODUCE!
THEY'RE TURNING YOUR GROCERY STORE INTO A SECRET VACCINE CLINIC WITHOUT YOUR CONSENT!
One head of lettuce? Fresh, clean, harmless.
The next one from the same shelf? Loaded with hidden mRNA or polio shots designed to "immunize" you whether you want it or not.
You bite into a crisp tomato thinking you're eating a salad and BAM surprise polio vaccine straight to your bloodstream. No consent. No choice. Just engineered obedience through your dinner plate.
This is the endgame of control: mandatory vaccination by fork. They couldn't force it through your arm forever, so now it's in the fields, the irrigation systems, the very DNA of what we eat.
DEMAND VACCINE LABELING ON ALL PRODUCE NOW!
If it's got a shot in it, it needs a giant WARNING label: "May Contain Experimental Vaccines – Eat at Your Own Risk."
Wake up, America. Boycott unlabeled food. Grow your own if you can. Spread this before they shut it down.
13
Jun 1
This is completely normal. Dont look up.

19
3rdEyeVisuals retweeted

May 31
Everything is an illusion or False Flag. He shows how easy it is to manipulate and deceive a Nation.
53
1,163
4,897
207,405