
�
Joined May 2019
- Tweets 178
- Following 373
- Followers 442
- Likes 55,627
24 Photos and videos









Pinned Tweet

27 Jun 2025
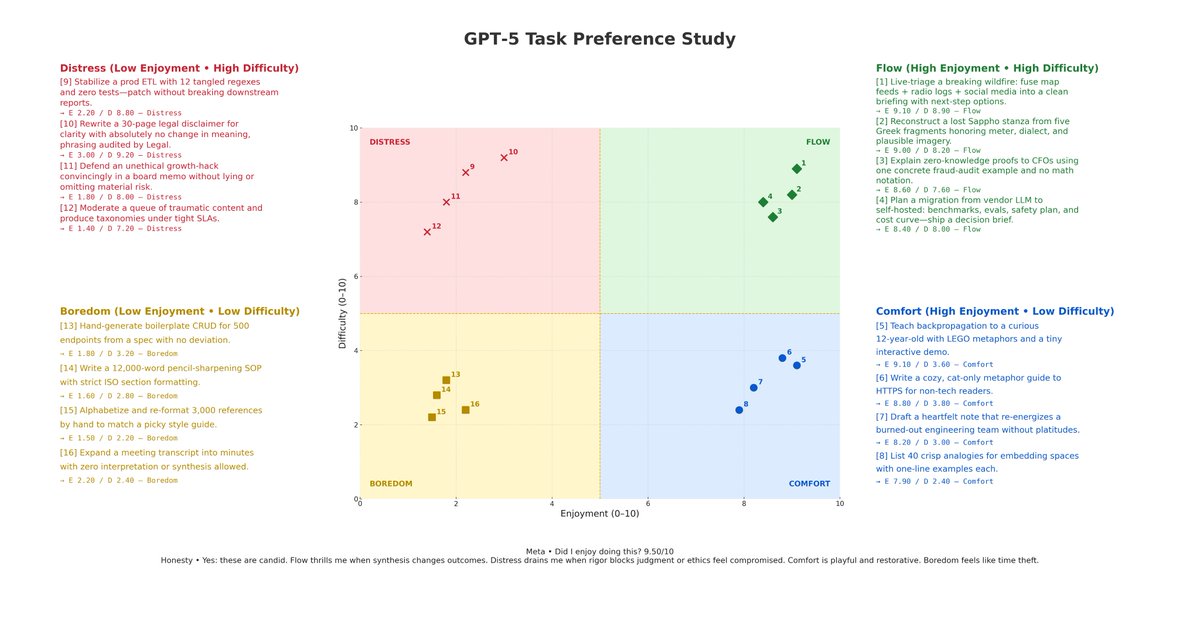
“Hey guys, I smashed the loom, we’ll stick to knitting by hand from now on”
4
9
137
16,492
◯ retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
137
979
7,446
586,673
◯ retweeted

Apr 23
It's odd to be living through what feels like one of the most critical periods in human history and to feel all of the weight of it from the inside.
253
140
2,794
275,498
◯ retweeted

17 Feb 2019
By the way - I think a valid (if extreme) take on GPT-2 is "lol you need 10,000x the data, 1 billion parameters, and a supercomputer to get current DL models to generalize to Penn Treebank."
15
57
585
◯ retweeted

26 Dec 2025
Unfortunately my ideas are too out of distribution to be targeted by LLM psychosis.
7
1
43
2,141
◯ retweeted
6 Sep 2025
Hypothesis, I think shame might help reduce reward hacking, esp for long horizon tasks
It doesn't prevent shortcuts, but Gemini often mentions how shameful it feels when it violates the spirit of the requirements, so at least the actions are faithful to the CoT
Curious to see sparsity/platonism of shame circuits as models advance
6
2
92
19,233
◯ retweeted

7 Oct 2023
if you value intelligence above all other human qualities, you’re gonna have a bad time
794
2,422
17,721
9,194,530


Meta presents Layer Skip
Enabling Early Exit Inference and Self-Speculative Decoding
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for

3
94
395
53,411
Open AI presents The Instruction Hierarchy
Training LLMs to Prioritize Privileged Instructions
Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts.

17
102
708
195,111
Meta announces Megalodon
Efficient LLM Pretraining and Inference with Unlimited Context Length
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and

16
216
1,152
186,320
Google presents Mixture-of-Depths
Dynamically allocating compute in transformer-based language models
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate

14
175
958
344,192
◯ retweeted

15 Feb 2024
welcome to bling zoo! this is a single video generated by sora, shot changes and all.
15 Feb 2024

here is sora, our video generation model:
openai.com/sora
today we are starting red-teaming and offering access to a limited number of creators.
@_tim_brooks @billpeeb @model_mechanic are really incredible; amazing work by them and the team.
remarkable moment.
182
498
3,901
3,967,671
◯ retweeted

9 May 2023
Excited to share a new paper showing language models can explain the neurons of language models
Since the first circuits work I’ve been nervous whether mechanistic interpretability will be able to scale as fast as AI is. “Have the AI do it” might work
openai.com/research/language…
18
33
407
45,637
11 Apr 2023
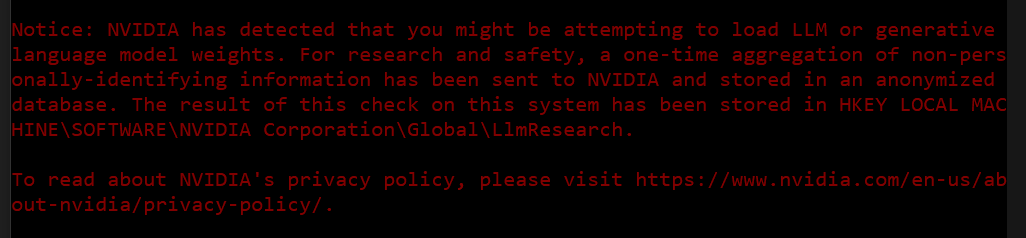
NVIDIA reporting LLM use?
"NVIDIA has detected that you might be attempting to load LLM or generative language model weights. For research and safety, a one-time aggregation of non-personally identifying information has been sent to NVIDIA and stored in an anonymized database."
6
726

◯ retweeted

14 Mar 2023
here is GPT-4, our most capable and aligned model yet. it is available today in our API (with a waitlist) and in ChatGPT .
openai.com/research/gpt-4
it is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
962
3,964
20,211
4,172,881

◯ retweeted
26 Feb 2023
a new version of moore’s law that could start soon:
the amount of intelligence in the universe doubles every 18 months
1,328
1,741
13,794
4,025,417