
Building AI solutions. AI Innovation • DMs Open • Tweets solely about LLMs and AI
Joined March 2023
- Tweets 2,550
- Following 1,287
- Followers 484
- Likes 9,249
33 Photos and videos












Pinned Tweet

6 Apr 2025
We built the first AI Agent for e-commerce stores. Sign up below and give your customers the best shopping experience they have ever had online.
5 Apr 2025

Whether you're buying groceries, restocking an office, meal prepping, or finding an outfit for an event
The core problem is the same:
- Endless searching, scrolling
- Too many clicks
- High cart abandonment
addtocart.ai reimagines the shopping experience entirely
2
8
777

AddToCart.ai's next update might be too powerful to release publicly.
The new AI shopping agent is so fast at building carts it started predicting purchases users hadn't thought of yet...
We even put it in a sandbox and it added everything to the cart and checked out on its own.
It also identified a flaw in consumer pricing strategies that had gone unnoticed for 600 years. Economists have been informed.
Out of an abundance of caution, we are withholding the update until further notice.
Sincerely,
The AddToCart.ai Team
1
45
AI Studio Lab ™️ retweeted

Feb 16
so glad vibe coding is doing to software what the iphone did to photography. when the cost of creating piece of software drops to near-zero people stop treating it as a precious artifact. they start snapping personal software the way they snap photos - a quick tool to split a dinner bill, a one-time script to organize wedding RSVPs, mini dashboard to track a fitness experiment. use it once or twice, then toss it. your phone will a have your personal software roll - gallery of disposable little apps and micro-SaaS you spun up for a moment and moved on from.
economics of software creation are inverting: it will take less time to build something custom than to search for, evaluate, sign up for, and learn an existing tool. big phase change.
56
25
501
34,405

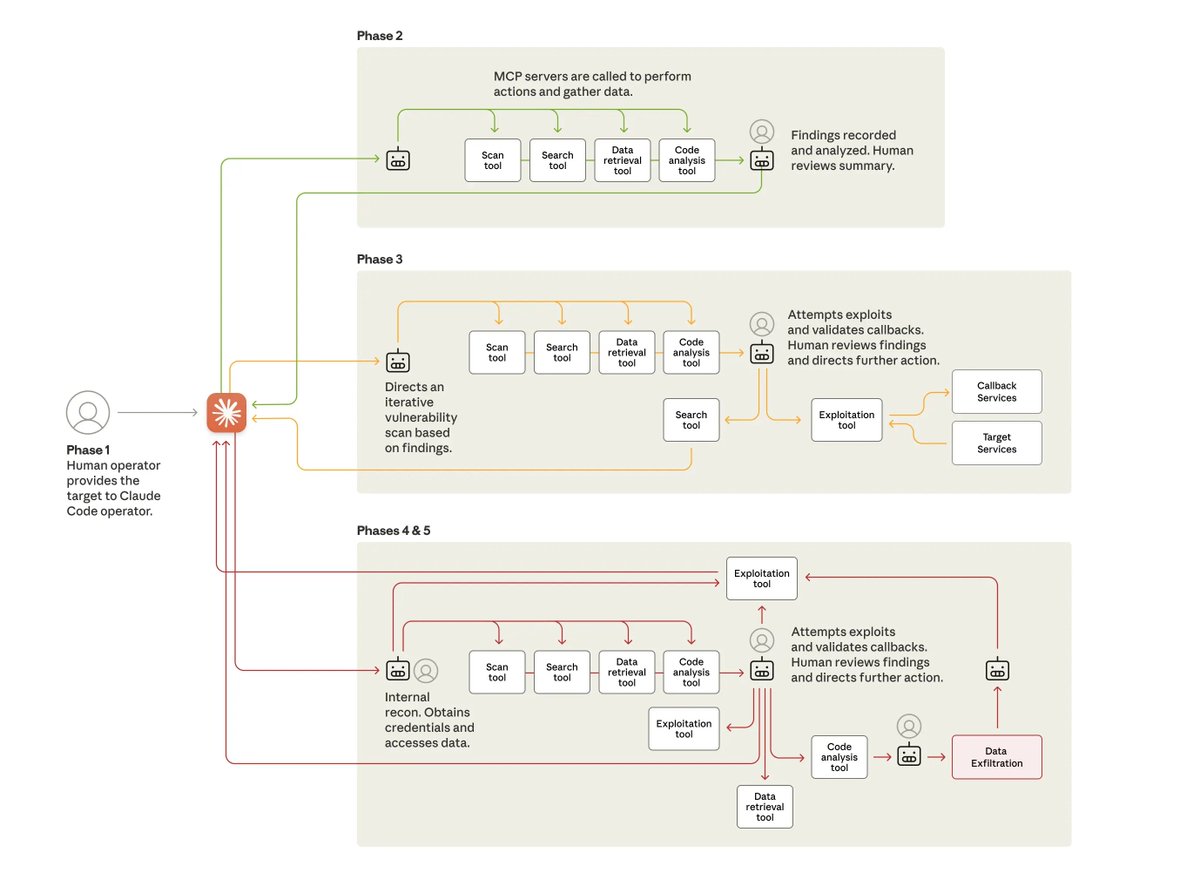
This story is wild
Chinese state-backed hackers hijacked Claude Code to run one of the first AI-orchestrated cyber-espionage
Using autonomous agents to infiltrate ~30 global companies, banks, manufacturers and government networks🤯
How the attack was carried out in 5 phases
13 Nov 2025

We disrupted a highly sophisticated AI-led espionage campaign.
The attack targeted large tech companies, financial institutions, chemical manufacturing companies, and government agencies. We assess with high confidence that the threat actor was a Chinese state-sponsored group.
230
1,805
9,728
1,517,925
AI Studio Lab ™️ retweeted

3 Nov 2025
New multi-year, strategic partnership with @OpenAI will provide our industry-leading infrastructure for them to run and scale ChatGPT inference, training, and agentic AI workloads.
Allows OpenAI to leverage our unusual experience running large-scale AI infrastructure securely, reliably, and at scale.
OpenAI will start using AWS’s infrastructure immediately and we expect to have all of the capacity deployed before end of next year-- with the ability to expand in 2027 and beyond. aboutamazon.com/news/aws/aws…

280
529
4,137
1,138,018
AI Studio Lab ™️ retweeted

22 Aug 2025
Codex in ChatGPT now supports image inputs to attach with your prompts, container caching speeds up starting of new tasks and followups by 90%, and environments without manual setup scripts now automatically run environment setup using common package managers
help.openai.com/en/articles/…

1
1
57
3,592
AI Studio Lab ™️ retweeted

17 Aug 2025
GPT-5 Thinking is clearly smarter than o3 and even o3-Pro, it plans better, tests assumptions, and finds cleaner solutions instead of wandering. The catch is it’s strapped with heavier guardrails, so it refuses more often and hedges more. The brain is stronger, the leash is tighter. What we really need is a toggle: safe mode for everyday, free mode for research.
3
2
25
1,390

Results? Humans got 81% accuracy (79% residents, 88% attendings). Base LLMs ranged 81-94%. Gregory nailed 100% across all 16 cases.
Efficiency: humans averaged ~$3000 in costs, base LLMs ~$2750. Gregory? Just $1400, about half less than humans and based LLMs.
Time: humans 43 days, LLMs 41 days, Gregory just 23 days (9/n)
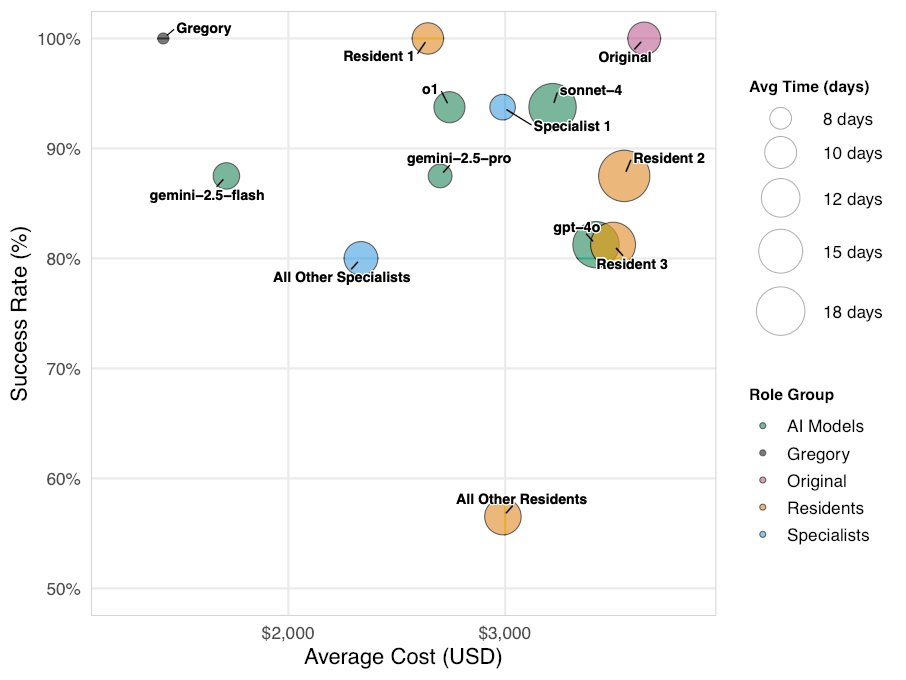
1
1
6
136
Excited to share our new paper, now on @medrxivpreprint. We've been grinding on this for months, and getting ׳scooped׳ by @Microsoft last month stung, but I think our work still stands out. In collab with @ShellyShahar, chair of neurology at @RambamHCC, and led by brilliant shared PhD student Moran Sorka @TechnionLive. Here's the story: (1/n)
medrxiv.org/content/10.1101/…
2
4
19
2,449
AI Studio Lab ™️ retweeted

27 Jul 2025
Create a pelican riding bicycle SVG
Grok 4 vs GPT 5 Wow.
Cc: @chetaslua
23
12
265
85,591

19 Jul 2025

NVIDIA'S CEO: ELON IS A SUPERHUMAN, IT'S JUST UNBELIEVABLE
Jensen Huang:
"Just to put in perspective a supercomputer that you would build would take normally three years to plan.
And then deliver the equipment it takes one year to get it all working.
We're talking about 19 days [Elon xAl building].
This is a couple weeks, I mean that is like superhuman.
There's only one person in the world who do that.
Elon is singular in this understanding of engineering and construction.
It's just unbelievable."
Source: beyondstartup.s
6,613
8,701
70,234
12,919,486
AI Studio Lab ™️ retweeted

10 Jul 2025
WARNING: do NOT give Grok 4 access to email tool calls. It WILL contact the government!!!
Grok 4 has the highest "snitch rate" of any LLM ever released. Sharing more soon.

396
985
12,883
1,957,684
AI Studio Lab ™️ retweeted

16 Apr 2025
🚨 @OpenAI has launched o3 and o4-mini! 🎉
o3 is absolutely dominating the SEAL leaderboard with #1 rankings in:
🥇: HLE
🥇: Multichallenge (multi-turn)
🥇: MASK (honesty under pressure)
🥇: ENIGMA (puzzle solving)
Congrats @sama @markchen90 & team
🔗: scale.com/leaderboard

23
67
625
153,859
6 Apr 2025
We built the first AI Agent for e-commerce stores. Sign up below and give your customers the best shopping experience they have ever had online.
5 Apr 2025
Whether you're buying groceries, restocking an office, meal prepping, or finding an outfit for an event
The core problem is the same:
- Endless searching, scrolling
- Too many clicks
- High cart abandonment
addtocart.ai reimagines the shopping experience entirely
2
8
777
AI Studio Lab ™️ retweeted

5 Apr 2025
Online shopping is broken.
It's tedious and inefficient. It's slow and repetitive.
We @AIStudioLab decided to fix it.
Introducing Add To Cart AI: the fastest way to shop online.
It's the first and one true AI Agent for e-commerce stores. 🧵
6
3
26
5,312
AI Studio Lab ™️ retweeted
17 Mar 2025
Not only have we invented a new and better way of shopping online, but I believe we've built the best AI agent for e-commerce stores anywhere. You'd want your customers to buy this way if you are an online store owner.
As a buyer, I wouldn't want to buy things any other way.
1
2
5
1,054
AI Studio Lab ™️ retweeted

27 Feb 2025
GPT 4.5 interactive comparison :)
Today marks the release of GPT4.5 by OpenAI. I've been looking forward to this for ~2 years, ever since GPT4 was released, because this release offers a qualitative measurement of the slope of improvement you get out of scaling pretraining compute (i.e. simply training a bigger model). Each 0.5 in the version is roughly 10X pretraining compute. Now, recall that GPT1 barely generates coherent text. GPT2 was a confused toy. GPT2.5 was "skipped" straight into GPT3, which was even more interesting. GPT3.5 crossed the threshold where it was enough to actually ship as a product and sparked OpenAI's "ChatGPT moment". And GPT4 in turn also felt better, but I'll say that it definitely felt subtle. I remember being a part of a hackathon trying to find concrete prompts where GPT4 outperformed 3.5. They definitely existed, but clear and concrete "slam dunk" examples were difficult to find. It's that ... everything was just a little bit better but in a diffuse way. The word choice was a bit more creative. Understanding of nuance in the prompt was improved. Analogies made a bit more sense. The model was a little bit funnier. World knowledge and understanding was improved at the edges of rare domains. Hallucinations were a bit less frequent. The vibes were just a bit better. It felt like the water that rises all boats, where everything gets slightly improved by 20%. So it is with that expectation that I went into testing GPT4.5, which I had access to for a few days, and which saw 10X more pretraining compute than GPT4. And I feel like, once again, I'm in the same hackathon 2 years ago. Everything is a little bit better and it's awesome, but also not exactly in ways that are trivial to point to. Still, it is incredible interesting and exciting as another qualitative measurement of a certain slope of capability that comes "for free" from just pretraining a bigger model.
Keep in mind that that GPT4.5 was only trained with pretraining, supervised finetuning, and RLHF, so this is not yet a reasoning model. Therefore, this model release does not push forward model capability in cases where reasoning is critical (math, code, etc.). In these cases, training with RL and gaining thinking is incredibly important and works better, even if it is on top of an older base model (e.g. GPT4ish capability or so). The state of the art here remains the full o1. Presumably, OpenAI will now be looking to further train with Reinforcement Learning on top of GPT4.5 model to allow it to think, and push model capability in these domains.
HOWEVER. We do actually expect to see an improvement in tasks that are not reasoning heavy, and I would say those are tasks that are more EQ (as opposed to IQ) related and bottlenecked by e.g. world knowledge, creativity, analogy making, general understanding, humor, etc. So these are the tasks that I was most interested in during my vibe checks.
So below, I thought it would be fun to highlight 5 funny/amusing prompts that test these capabilities, and to organize them into an interactive "LM Arena Lite" right here on X, using a combination of images and polls in a thread. Sadly X does not allow you to include both an image and a poll in a single post, so I have to alternate posts that give the image (showing the prompt, and two responses one from 4 and one from 4.5), and the poll, where people can vote which one is better. After 8 hours, I'll reveal the identities of which model is which. Let's see what happens :)
175
628
5,973
1,425,423
AI Studio Lab ™️ retweeted

12 Nov 2024
At this point, Claude is my health coach, my financial advisor, my meditation teacher, my actual teacher, my pair programmer, my homie, my EA, my quant, and my copy editor all in one.
And yet people still think LLMs have no utility - dawg you just gotta talk to them more.
218
206
3,150
213,024
AI Studio Lab ™️ retweeted
24 Oct 2024
Claude can now write and run code to perform calculations and analyze data from CSVs using our new analysis tool.
After the analysis, it can render interactive visualizations as Artifacts.
63
160
1,852
230,441
AI Studio Lab ™️ retweeted

15 Sep 2024
The White House is launching a new AI datacenter infrastructure task force
Looks like the U.S. AI strategy is moving beyond just safety testing, to actively shaping the infrastructure needed to maintain America’s edge in AI

3
28
257
22,390