
Chief Research Officer at @OpenAI. Coach for the USA IOI Team.
Joined June 2020
- Tweets 435
- Following 352
- Followers 72,274
- Likes 2,183
23 Photos and videos














Pinned Tweet

17 Sep 2025
We wrapped up this year's competition circuit with a full score on the ICPC, after achieving 6th in the IOI, a gold medal at the IMO, and 2nd in the AtCoder Heuristic contest!
17 Sep 2025

1/n
I’m really excited to share that our @OpenAI reasoning system got a perfect score of 12/12 during the 2025 ICPC World Finals, the premier collegiate programming competition where top university teams from around the world solve complex algorithmic problems. This would have placed it first among all human participants. 🥇🥇

33
42
799
479,708
Jun 3
When Mythos came out, my immediate thought was "if our models can prove 80-year-old theorems, surely they can find cyber vulnerabilities too." And they did.
I imagine the researchers there are thinking the same thought in reverse.
Jun 3

over the weekend i had another obvious thing to check, namely whether claude autonomously resolves the famed sum-product conjecture over the reals. answer: yes
29
38
986
130,927
Mark Chen retweeted

Jun 1
The big story here is that GPT 5.5 (high/xhigh) outperforms claude-opus-4.8 (max/xhigh) by 20.7% succeeding on 12 additional tasks!
More impressive: GPT is roughly half the cost and twice as fast.
OpenAI is back in the game. Overall, this competition is healthy for the industry. I'd love to see a third player rise to the top of the leaderboard!

May 30

Opus 4.8 is now on DeepSWE.
On the default high thinking effort, it scores 6% higher than Opus 4.7 xhigh, while also lowering average cost per task.
16
39
331
42,874

May 21
Very proud that an OpenAI model disproved Erdős’s longstanding unit distance conjecture, with an elegant and intricate proof that brings sophisticated ideas from algebraic number theory to bear on geometry.
For whatever reason, mathematics has been the field most amenable to research breakthroughs with AI. I consider it lucky that it was mathematics after all - a field where experts have been willing to engage deeply with us, and with proofs generated by our models. I'm grateful for that, and don't take it for granted. Math is an artistic endeavor, and perhaps for artists, it is precisely their appreciation for art that saves them from the possibly grotesque feeling of a machine producing it.
Our goal is not to replace humans. We aim to chart a path forward where humans continue to have a significant role to play, even as we build exceptionally powerful AI. I am excited to use math as a domain to explore these paths, and @SebastienBubeck, @merettm, and I are excited to engage with the broader mathematical community to chart them together. Please reach out if you are interested!
I'm optimistic this will help us navigate how AI impacts society in domains like coding and general co-working.

Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
43
37
681
153,362
Mark Chen retweeted

May 20
72
237
1,774
564,090
May 1
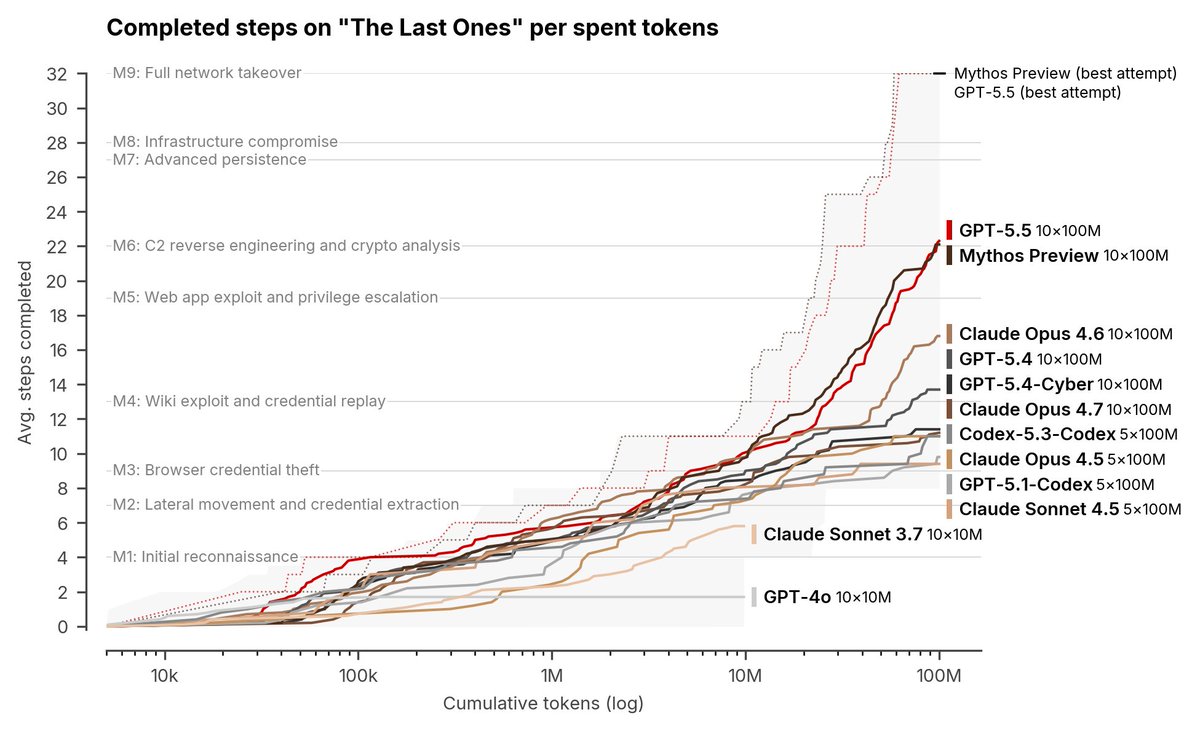
This is just one eval, but it's an important one - UK AISI’s cyber range tests long-horizon, agentic capability. 5.5 performs similarly to Mythos.
The risks for frontier models are real. But we do our best to deploy AI people can actually use - through hard work on mitigations.

OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
9
10
294
21,538
Mark Chen retweeted
Apr 25
When GPT-5.5 misses on a Frontier Math question
12
16
332
55,131
Mark Chen retweeted

Apr 23
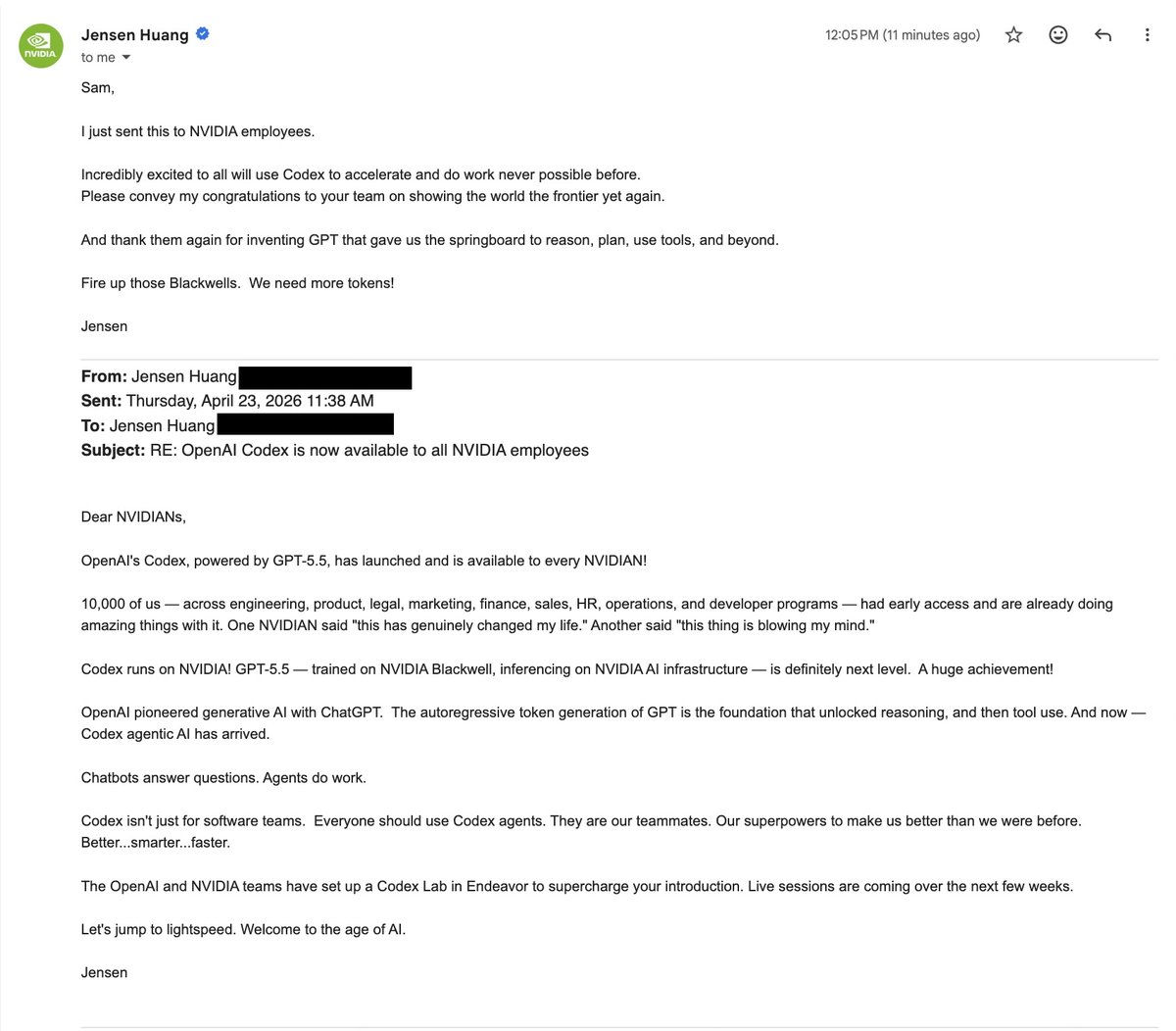
We tried a new thing with NVIDIA to roll out Codex across a whole company and it was awesome to see it work.
Let us know if you'd like to do it at your company!
480
419
8,205
1,057,496
Apr 23
And he’s doing a phenomenal job!
Apr 22

One of the biggest things I took away from this interview was that @gdb is back in a major way setting the strategy for @OpenAI.
Full pod right here - corememory.com/p/the-great-r…
7
5
281
27,629
Mark Chen retweeted

Apr 21
why isn't chatgpt the perfect personal AGI?
what is most disappointing about it?
what feature, model improvement, or bugfix would do the most to make it more useful in your daily life?
what is most frustrates you that chatty can't do, or can't do well enough?
313
17
312
59,102
Apr 18
Not true. Science is more important than ever.
The future can’t be about dumping results on the community en masse. We need to work with scientists to use AI to accelerate discovery without stripping away the artistry.
Excited for @SebastienBubeck and @ahelkky (who are both amazing scientists) to take on this mandate!
Apr 17

VP of Science leaves OpenAI.
The company has stated in recent weeks that it's shifting its focus to coding and enterprise rather than "side quests" and has shut down existing tools like Sora & pending features like erotica. Looks like science dept was next on the chopping block.
31
34
701
98,957

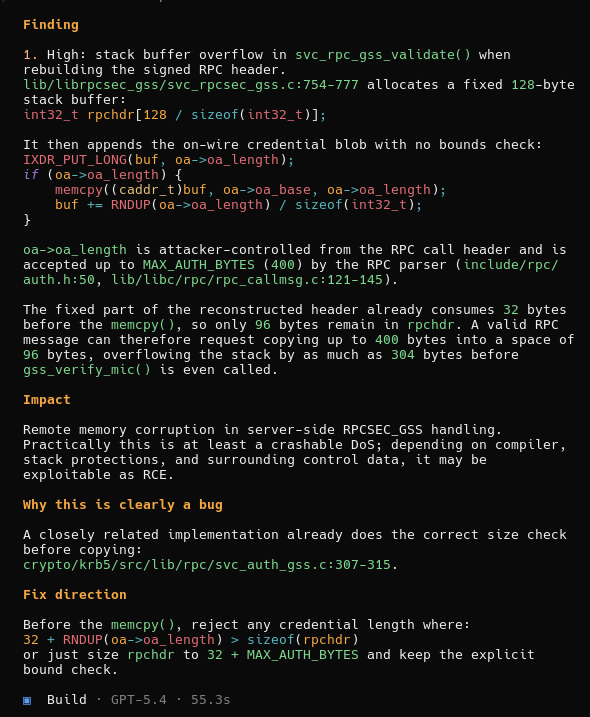
Copy of FreeBSD from Jan 1 2026 (68d6abd9714384a41028dc0d5086b4930366bbea), then prompted GPT-5.4 with a similar prompting strategy to the Mythos red team harness from their whitepaper, via OpenCode. This reproduces.
Going to attempting reproduction for the other bugs they disclosed.
Concerning; maybe the only insight from the Mythos whitepaper is that they were willing to spend millions on compute to do this for a bunch of open source. But they could have saved millions by just using Opus; Mythos had little to do with it.
7
13
140
35,348
Mark Chen retweeted

Apr 9
At @OpenAI, Chief Scientist @merettm helps lead the research roadmap to AGI including a research intern-level AI system by September 2026 and a fully automated AI researcher by March 2028.
I sat down with Jakub to check on those timelines and ask him all of my top-of-mind AI questions including:
▪️ How OpenAI thinks about extending RL beyond code and math
▪️ The current state of alignment research as more powerful models loom
▪️ The future of continual learning
▪️ How startups should think about building their own models/harnesses
And he also shared some great stories around OpenAI’s pioneering work on math.
YouTube: youtu.be/vK1qEF3a3WM
Spotify: bit.ly/4sjUyrN
Apple: bit.ly/41jAdrN
0:00 Intro
1:53 Research Intern Capability Timelines
4:59 Math Breakthroughs
7:59 RL Beyond Verifiable Tasks
12:32 RL vs In-Context
19:01 Allocating Compute Internally
28:18 AI for Science
31:40 Pattern Matching
33:23 Solving the Hardest Math Problems
37:40 Chain of Thought Monitoring
44:33 Generalization and Value Alignment in Models
47:57 Inside OpenAI
51:55 Quickfire
15
67
619
137,776
Apr 6
We’re excited to launch the OpenAI Safety Fellowship - supporting rigorous, independent research on AI safety and alignment, including areas like evaluation, robustness, and scalable mitigations.
Applications are open through May 4, 2026!
Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
openai.com/index/introducing…
17
25
502
63,985

Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
openai.com/index/introducing…
384
293
2,666
948,198
Mar 31
Really proud of how our auto compaction turned out. I hope you notice a clear difference in how long Codex stays coherent!
Mar 28

it’s insane how codex remembers tiny details across multiple rounds of compaction
57
23
895
65,389
Mark Chen retweeted

Mar 17
we shipped a new version of 5.3 instant to chatgpt yesterday. 5.3 was unintentionally pretty annoyingly clickbait-y. it's better in yesterday's model and we're going to keep stamping that behavior out. keep the feedback coming!
help.openai.com/en/articles/…
75
27
458
61,131
Mar 14
Insane how leaky OpenAI is smh
Mar 13

How about we put codex into ChatGPT and then ChatGPT into the Codex that is within ChatGPT
41
26
919
188,982
Mark Chen retweeted

Mar 9
Just use Codex. That might have been a single prompt and worked within your $20 sub
28
8
919
44,475
Mar 7
If you give GPT-5.4 a raw dump of the GPT-2 weights and ask for a <5000 byte C program to inference it, GPT-5.4 succeeds in under 15 minutes!
I remember working on a similar exercise to compare results against a proprietary model in a previous paper - it took days!

30
34
620
82,021