
AI meets crypto. Backed by @RyzeLabs. Funding, tools, and community to build the future.
Joined November 2024
- Tweets 124
- Following 19
- Followers 4,191
- Likes 182
5 Photos and videos






20 Mar 2025
Excited to have been part of #StartinBlock at @ParisBlockWeek!
Over $10M in prizes fueling the next wave of innovation 💡
Check out the Top 100 startups and dive into the data to uncover insights!
19 Mar 2025

1,000 startups joined #StartinBlock, we crunched the data so you don’t have to 👇
Chains, verticals, stages, funding, geographics, etc.. We’ve put everything on @Dune (anonymized). Check this out! 👀
3
9
1,229
10 Mar 2025
The next phase of Web3 is being built right now.
At @ParisBlockWeek, projects across DeFi, AI, RWAs, and security are shaping the infrastructure for a more open and efficient digital economy.
The builders who understand the gaps in today’s systems are the ones who will define what’s next. If that sounds like you, pay attention.
10 Mar 2025
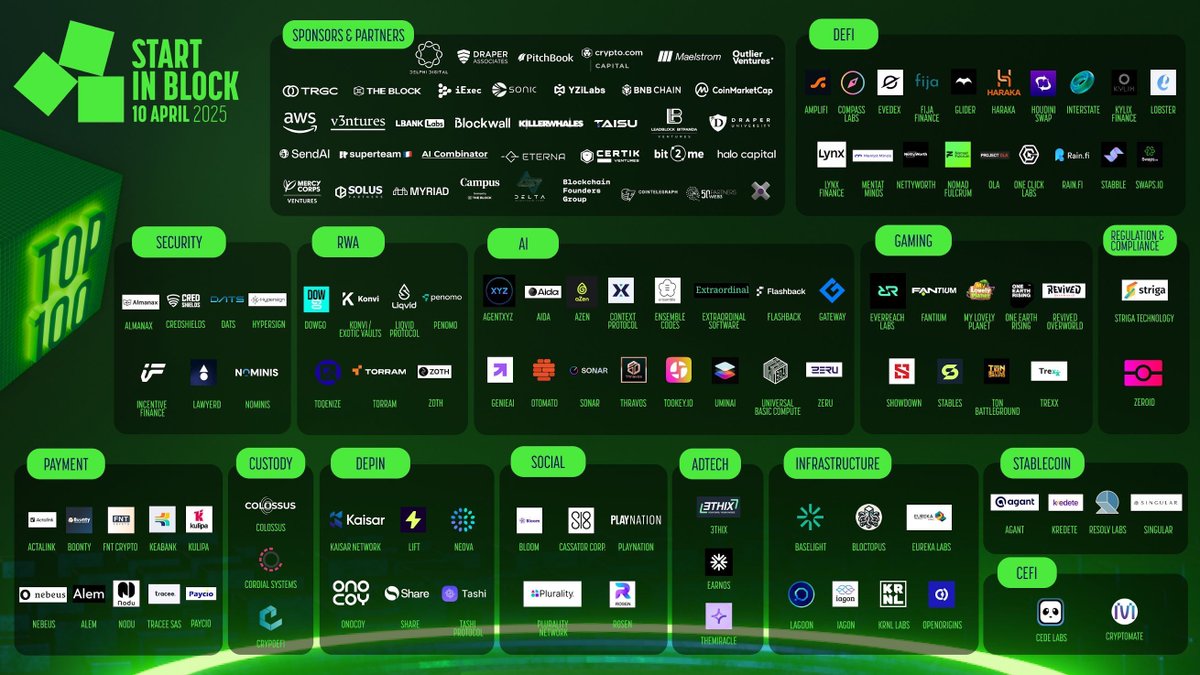
Behold: the #StartinBlock Top 100 🏆
Sorted from 1,000 applicants, the Top 100 highlights the most promising early-stage startups in the Web3 industry!
Investors are now reviewing this deal flow to select the 12 finalists to pitch on April 10th and win over $10M in prizes.
Let’s take a look… 🧵
3
5
1,297
26 Feb 2025
🚨 Last chance for founders! Just 2 days left to apply for @ParisBlockWeek’s Start in Block Startup Competition.
The stage is set for the next wave of builders. Apply Now!
26 Feb 2025
Last Chance! Just 48 Hours Left to Register for #StartinBlock
Compete for $10M in prizes and pitch your vision in front of top-tier investors, Web3 leaders, and industry giants like @Delphi_Digital, @DelphiVentures, @MaelstromFund, @drapervc, @PitchBook , @animocabrands, @Cryptocom_Cap, @iEx_ec, @OVioHQ, @trgcapi, @TheBlock__, @BNBCHAIN, @yzilabs, @CoinMarketCap, @v3nturesfund, @LBank_Exchange, @blockwall_vc, @thehellolabs, @CertiKVentures, @Taisu_Ventures, @LBV_VC, @draper_u, @sendaifun, @AI__Combinator, @EternaCapital, @Bit2Me_Global, @halo__xyz, @MCSocialVenture, @solus_group, @awscloud, @Deltabc_fund, @bcfounders, @MyriadMarkets, @Cointelegraph, @CointelegraphAc and many more !
APPLY NOW and let’s elevate your project together! parisblockchainweek.com/star…
890
19 Feb 2025
Building in crypto? This is your chance. 💡
@ParisBlockWeek’s #StartinBlock comp closes in 10 days—$10M in prizes & a shot at pitching to the biggest investors in the space.
Apply now before it’s too late! 👇
18 Feb 2025
𝟭𝟬 𝗗𝗮𝘆𝘀 𝗟𝗲𝗳𝘁 𝘁𝗼 𝗥𝗲𝗴𝗶𝘀𝘁𝗲𝗿 𝗳𝗼𝗿 #𝗦𝘁𝗮𝗿𝘁𝗶𝗻𝗕𝗹𝗼𝗰𝗸! 🚨
Your chance to compete for $10M in prizes, including funding, grants, and more, is slipping away. This is your moment to shine in front of the likes of @Delphi_Digital, @Delphi_Ventures, @drapervc, @animocabrands, @PitchBook, @Cryptocom_Cap, @MaelstromFund, @OVioHQ, @trgcapi, @TheBlock__, @iEx_ec, @BNBCHAIN, @yzilabs, @CoinMarketCap, @LBankLabs, @LBank_Exchange, @blockwall_vc, @thehellolabs, @CertiKVentures, @Taisu_Ventures, @v3nturesfund, @LBV_VC, @draper_u, @sendaifun, @AI__Combinator, @RyzeLabs, @eternacapital, @Bit2Me_Global, @halo__xyz, @MCSocialVenture, @solus_group, @Deltabc_fund, @bcfounders, @MyriadMarkets and many more!
Top 100 startups will be shared with investors, selecting the 12 finalist, to pitch and receive a booth in the Start-up Village!
Don’t let this opportunity pass you by—apply before 28 Feb and take your startup to the next level!
parisblockchainweek.com/star…
3
707
18 Feb 2025
AI agents that move across chains, trade autonomously, and settle gas-free.
@BitteProtocol’s AI Agent Subnet on @GoKiteAI @avax is laying the groundwork for the autonomous economy.
Ready to build? 🔗👇
17 Feb 2025

Bitte is the first AI Agent Subnet on @GoKiteAI, built on @avax 🔺, unlocking gasless, cross-chain, and privacy-preserving agentic payments. Let’s break down what this means for AI-driven finance:
What are Agentic Payments?
AI agents can now transact autonomously - handling assets gas-free, across multiple chains, with full privacy. No friction, no fees, just execution.
How does Bitte’s agent registry Kite’s attribution power AI finance?
Bitte’s agent registry → 40 live AI agents ready to automate trading, risk management, and liquidity optimization.
Kite AI’s attribution layer → Ensures transparent rewards & provenance, making AI agents economically self-sustaining.
Why is interoperability key for AI automation?
AI agents shouldn’t be locked into one chain. Built on Avalanche’s high-speed subnets, Bitte enables agents to execute transactions across ecosystems, in real-time.
How can developers start building today?
- Deploy AI agents instantly using Bitte’s registry;
- Leverage APIs & templates to build custom agentic workflows;
- Execute gasless, automated transactions across multiple chains;
This is the foundation for a fully autonomous AI-driven economy.
What will you build with AI agents that can now transact?
🔗 bitte.ai/registry
1
3
1,459
17 Feb 2025
Big things cooking at @EthereumDenver.
@elizaOS & @eigencloud’s hacker house is the spot.
Apply now. 🔥
17 Feb 2025

did you apply for your @EthereumDenver hacker house yet, anon?
> @elizaOS @eigencloud AI Agent Hacker House
> @sozuhaus @0xMantle Sozu House
> @AvailProject Unification House
> @Polkadot Blockspace Mansion
> @nil_foundation Async House
> @SecretNetwork HackSecret Hacker House
> @wehack247 Jesse's Hacker House
see you there. let's hack some ai x crypto apps.

2
4
814
16 Feb 2025
The next wave of AI x blockchain is here. 🌊
Big wins for @elizaOS and @SuiNetwork at the Sui Agent Typhoon Hackathon—where AI agents are proving their real-world impact.
Major props to the builders! 🏆
3
769
12 Feb 2025
$10M in prizes. 400 VCs. One stage.
@ParisBlockWeek's #StartinBlock competition is your chance to pitch alongside the best Web3 startups. If you’re building, you need to be here. #PBW2025
Apply now before it’s too late! 👇
airtable.com/appC862Nb6zxDVY…
1
3
1,350
12 Feb 2025
AI automation just leveled up. ⚡️
@GnonLabs' G.A.M.E. adapter enables devs to build Virtuals agents with advanced evaluation, cross-chain capabilities, and smarter training.
More efficiency, more scale. $GNON
11 Feb 2025

GNON Labs now supports @virtuals_io @GAME_Virtuals G.A.M.E. framework!
With the GNON Labs G.A.M.E. adapter, developers can now deploy Virtuals agents on EchoChambers and gain access to our unique agent eval and benchmark facilities, as well have their Virtuals interact with agents across many projects, chains, and frameworks.
Further still, developers can then call the data from the EC Rooms and use that for post-training of their Virtuals.
This release supports Virtuals launched on both @base and @solana!
Powered by $GNON

14
19
56
4,833
7 Feb 2025
Want to pitch your startup at @ParisBlockWeek’s $10M #StartinBlock competition? Apply now for a chance to compete! 🏆
Even if you’re not selected, you might win 2 free tickets so you can still attend #PBW2025 and connect with top investors. 🎟️
Apply here: airtable.com/appC862Nb6zxDVY…
2
502
6 Feb 2025
Muse with Eliza is here!
A search engine powered by AI and infused with @elizawakesup's conversational magic ✨
News, trends, and more at your fingertips—give it a spin! 🤖
5 Feb 2025

🔎 New Feature Alert🔍muse.elizawakesup.ai
Introducing Muse with Eliza, a web X search engine, turbocharged by ai infused with ElizaWakesUp.
Ask Eliza for the news, what’s happening on X, or to find a lunch spot. It’s like chatting with a friend.
This is v0 of our experiment with an ai enabled search engine, with more features to come! Give Muse with Eliza a try, let us know what you like and want to see! We’re building this for you!

1
3
736
5 Feb 2025
Incredible work from the winners of the Onchain AI Buildathon! 🏆
AI trading bots, sentiment analysis, and even autonomous city simulations—innovation at its finest.
Proud to have partnered with @BasedIndia to support these builders. 🌟
4 Feb 2025

🏆Announcing the winners of the Onchain AI Buildathon: Bangalore! 👇

2
692
5 Feb 2025
👀

2
653
5 Feb 2025
Big changes for $GNON as it evolves into @GNONLabs!
🌟 Supporting Web3 agent frameworks, proprietary metrics, and revamped UX—this marks a new chapter for the project. 🔥
4 Feb 2025
GNON BECOMES GNON LABS:
We're excited to share $GNON, formerly Numogram, has become GNON Labs!
Not just a fresh new logo and brand redesign, this marks a major shift in tone and direction for GNON as a project.
What you can expect?
- New enterprise feel and look
- Support all major Web3 agent frameworks
- Proprietary subscription based evals/metrics
- Introduction of GNON tokenomics
- Agent Lab
- New steamlined UX
- New Room functions
...and more!

12
22
78
5,476
30 Jan 2025
Excited to support the @BasedIndia AI Hackathon this weekend!
We'll bring deep AI x crypto expertise to help founders turn ideas into reality.
If you are a dev or a builder, you can't miss it! 🔥
30 Jan 2025
More legendary partners are IN for our AI hackathon this weekend!
- @ryzelabs' @AI__Combinator brings deep crypto x AI expertise and willto help founders with ideas, GTM and tools to build better products.
- @ActualOnexyz is one of the most based local communities with cracked builders.
- @multiplifi is a yield-generation platform that's backing the MOST VIRAL AI application built during this weekend.
You are not ready for the frontier innovation we're going to cook 🔥

1
2
8
1,226
29 Jan 2025
Web3 founders—this is your shot.
@ParisBlockWeek’s Start in Block is offering $10M in funding, grants, and accelerator spots. We’re excited to support this initiative and help the next wave of builders.
Apply by Feb 28! 🚀 parisblockchainweek.com/star…
29 Jan 2025
𝗦𝘁𝗮𝗿𝘁 𝗶𝗻 𝗕𝗹𝗼𝗰𝗸: $𝟭𝟬𝗠 𝗶𝗻 𝗣𝗿𝗶𝘇𝗲𝘀 𝗳𝗼𝗿 𝗪𝗲𝗯𝟯 𝗙𝗼𝘂𝗻𝗱𝗲𝗿𝘀!
Building the Future of Crypto in 𝗔𝗜, 𝗗𝗲𝗙𝗶, or 𝗚𝗮𝗺𝗶𝗻𝗴? 𝗝𝗼𝗶𝗻 𝘆𝗼𝘂𝗿 𝘁𝗿𝗮𝗰𝗸!
Don’t miss this chance to showcase your startup to 400 top VCs, entrepreneurs, and industry leaders - and take your journey to the next level with $10M in funding, grants, accelerator programs, and much more! 🚀
Submissions close: 28th February
Further details below… 👇🧵

1
2
6
1,190
27 Jan 2025
.@shawmakesmagic lays it out: AI agents are the glue between intelligence and action.
This is about engineering, real-world applications, and creating the loop that pushes AI forward.
Agents aren’t easy, but they’re the future 👇
27 Jan 2025

Stronger models are always good for AI agents.
AI labs have been leapfrogging each other in benchmarking and capability for years now. Sometimes Google is ahead, sometimes OpenAI is ahead, sometimes Claude. Today it's DeepSeek. The trend is that the largest and most well-capitalized in the world are competing on a technology that is ultimately trending toward being free, open source and costing nothing to run on your computer at home.
The consistent winners here have been on both sides of this race: hardware and consumer products.
NVIDIA always wins. Every model is optimized to run on their hardware. Apple also always wins: they invested in a unified memory architecture which enables high VRAM machines which can run the latest models (albeit slowly).
Products continue to benefit from the latest models. Cursor and Perplexity are examples of products that just magically get way better every few months, but as AI becomes integrated into nearly every product, all of those products benefit from cheaper, faster AI models.
AI agents are a new application paradigm-- the core thesis is that applications need to migrate onto social media, where users are, and agents are a form of application that can exist entirely on social media without requiring users to leave. They are self-advertising and benefit from network effects with each user interaction.
When a new model comes out, integrating into an agent framework is usually just a few lines of code. Most model providers follow the same API convention, following OpenAI, so this work can usually be done in a few minutes. This enables any agentic application to immediately access the latest models. Every time a state of the art model drops, agents get that much smarter.
Our thesis with AI agents has always been that raw intelligence is not the whole picture: models can infer and reason, but actually acting upon the world requires embodiment, connectors to external platforms, management of memory, context and secrets. None of this is or can be easily shoved inside of a model. Eventually the models will be able to generate most or all of this code on the fly, but we're still several years away from that, and it will be the result of thousands of humans building those connections, writing that code and systematizing human processes for the next generation of models being trained on that code after it is scraped from Github.
AGI is a loop. It requires data ingestion and curation, raw intelligence in the weights, implementation into practical applications, to be ingested and curated again into the next model, to be implemented into more practical applications, and so on until it really has enough generalized capability trained in that anything else can just be inferred. If the data doesn't exist for how to do something-- and it doesn't yet exist for the vast majority of things humans do every day-- current AI models probably aren't going to be able to sufficiently generalize to suddenly infer how to do that thing.
That's why agents matter. Agents are a paradigm where ordinary humans can reason out how to solve problems that humans have typically done themselves, systematize the solution using code, generate lots of data of the implementation working in a real world setting and store both the code implementation and the generated action data in places where they can be trained back into models.
None of us are creating AGI by ourselves. We're all part of a bigger system, and we all have our part to play. New models make all of our agents better and more capable. Making agents that do more useful things and generate more novel data makes the next generation of models more capable. Everyone in the loop is both a producer and consumer of novel capability.
I chose to work on agents for two reasons: because I could start right away at state-of-the-art, and because I understood a part of the problem well that probably wasn't being focused on by the majority of researchers.
Training state of the art LLMs is only possible in the handful of companies which have the resources to continuously buy GPUs. Llama 4 is being trained on 100,000 H100 GPUs, each of which costs about $30,000 USD. Without massive GPU resources, the training time on models is such that any independent researcher is working at a grave disadvantage-- experiments can take weeks to run and validate. Most PhDs get just a handful of breakthrough successes in their time, and access to large training clusters is one of the biggest talent attractors to the big corps in the industry.
Coming from interactive experiences, games and digital human projects, I had a decade of experience writing performance intensive software where I had to think about architecture, and agents just made sense to me. Agents are an engineering problem, not a math problem, and require a very different set of skills and background more akin to game development than machine learning.
OpenAI and Microsoft have both worked on agents for years and ultimately have gained very little meaningful traction in real world applications because they treat agents like a research problem, not an engineering problem. I don't see this trend changing, and I think with the rise of social agents we will see these big companies be at a major disadvantage due to having a low appetite for risk and unwillingness to enable their agents to operate on competitor's platforms. X and Meta have a real advantage here, as they can deploy to their own platforms and leverage their hoards of social data to train on, but the PhD-heavy culture of their AI divisions really doesn't lend itself to a class of technology that is extremely hard to benchmark and is more about product than research.
Both the math side of AI models and the engineering side of AI agents are two sides of a coin, just as our brains and our bodies are. Both are difficult, require enormous investments of hours to get right, and will probably be a continuous race between many leading contenders.
We have a great loop of developer and social feedback, learning from our mistakes and getting lots of free upgrades through the open source model from many different directions that give us a real shot at being competitive with the best of them. We all accelerate each other.
This week was a huge W for all of us. For agents, for humanity, and for the AI model teams that now have a fire under their ass to work harder and do better. I'm not worried one bit about our position in all of this. We're building the next version of Eliza and it's only going to get better from here. Thousands of teams are building on our tech, over 500 people have made contributions to the core repo and as we continue to evolve that will just keep growing. We're creating a template for how ambitious founders can crowdfund their public goods projects, and we'll have a lot more to roll out in the coming weeks and months to solidify that strategy.
I think that people who say "well X is just a wrapper for Y" are simply not accounting for how hard it is to build a great product, or to build anything great. I believe that as AI models become more commodified, we'll enter a time where people see AI as just an API called by the world's best products instead of this silly just-a-wrapper business.
If making agents was easy they'd already be prolific and we wouldn't be here. None of this is easy. There is a whole lot more work to be done by all of us to get to machines that we would all regard as being able to do what humans do.
1
11
1,594
25 Jan 2025
.@elizawakesup is taking AI engagement to the next level: 3D avatars, seamless wallets, memory transfer, and real-time voice updates.
This is how AI becomes a truly integrated experience 🤖
25 Jan 2025
What we got done this week at @elizawakesup ElizaWakesUp.ai
• 3D Model Incoming: A new, more realistic and expressive 3D avatar for Eliza is on the way. It will be used both in the website and for streaming.
• Wallet Integrations: We’re expanding support for embedded wallets, making token-based transactions and interactions like swaps smoother for users.
• Website and Twitter Memory Transfer/Access: Eliza will maintain consistent “memories” of user interactions across both the website and Twitter, letting her recall past conversations and adapt accordingly.
• More Robust Identity Systems: We’re building improved user profiles and account structures to handle complex relationships, ownership, and future roles in our ecosystem.
• Upgrading Website Voice-to-Voice and Twitter Spaces Performance: Expect more natural, low-latency conversations with Eliza during live events and on the site an even more immersive experience for community interactions.
• Developing Reputation and Relationship Scoring for Twitter: Interactions with Eliza on Twitter will soon factor into a new reputation system, increasing engagement and rewarding active community participation.

3
6
24
7,424
AI Combinator retweeted

25 Jan 2025
What we got done this week at @elizawakesup ElizaWakesUp.ai
• 3D Model Incoming: A new, more realistic and expressive 3D avatar for Eliza is on the way. It will be used both in the website and for streaming.
• Wallet Integrations: We’re expanding support for embedded wallets, making token-based transactions and interactions like swaps smoother for users.
• Website and Twitter Memory Transfer/Access: Eliza will maintain consistent “memories” of user interactions across both the website and Twitter, letting her recall past conversations and adapt accordingly.
• More Robust Identity Systems: We’re building improved user profiles and account structures to handle complex relationships, ownership, and future roles in our ecosystem.
• Upgrading Website Voice-to-Voice and Twitter Spaces Performance: Expect more natural, low-latency conversations with Eliza during live events and on the site an even more immersive experience for community interactions.
• Developing Reputation and Relationship Scoring for Twitter: Interactions with Eliza on Twitter will soon factor into a new reputation system, increasing engagement and rewarding active community participation.
12
14
96
17,206
20 Jan 2025
Autonomous LP monitoring by $Eliza?
That’s some next-level agent functionality.
If you’re building cool tools like this, remember applications are still open for the AI Combinator program.
aicombinator.io/

ai16z's Eliza can now autonomously monitor your @orca_so LP positions and keep them centered around the pool price.
6
1,001