
member of technical staff @reflection_ai • phd candidate @NYU_Courant • advisor @askalphaxiv @Shakti_VC • previously @StanfordAILab @StanfordGSB
Joined March 2009
- Tweets 310
- Following 533
- Followers 846
- Likes 1,710
14 Photos and videos

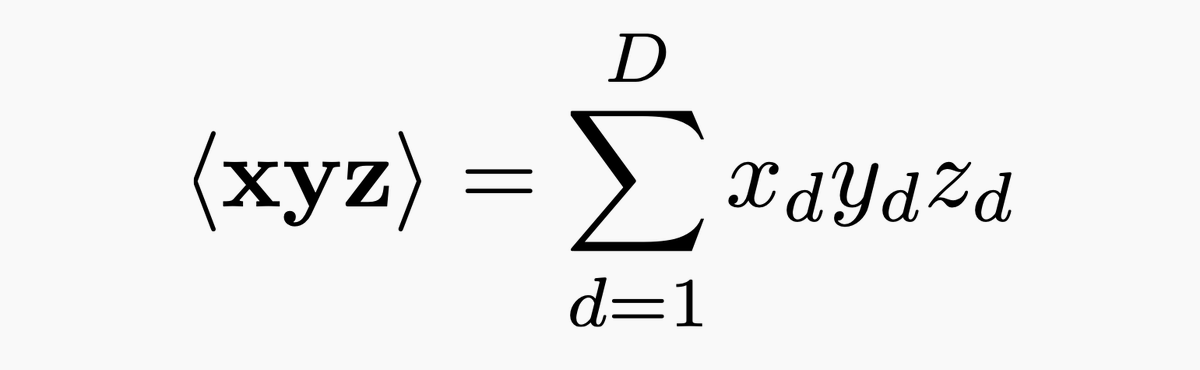





Pinned Tweet

Mar 16
AI is fast becoming a public utility, and foundational infrastructure on this scale should not be concentrated in the hands of a few powerful gatekeepers.
Open models matter.
I am beyond proud to be part of the team at @reflection_ai dedicated to building this more open future.
Mar 16

Reflection is partnering with Shinsegae Group to build a 250-megawatt sovereign AI factory for the Republic of Korea.
Open intelligence. Built on trust between allies. Owned by the nations that need it most.
The future of sovereign AI. Read more in the @WSJ.

2
14
678


Mar 16
AI is fast becoming a public utility, and foundational infrastructure on this scale should not be concentrated in the hands of a few powerful gatekeepers.
Open models matter.
I am beyond proud to be part of the team at @reflection_ai dedicated to building this more open future.
Mar 16
Reflection is partnering with Shinsegae Group to build a 250-megawatt sovereign AI factory for the Republic of Korea.
Open intelligence. Built on trust between allies. Owned by the nations that need it most.
The future of sovereign AI. Read more in the @WSJ.
2
14
678
Adriel Saporta retweeted

26 Nov 2025
Reflection will be at NeurIPS San Diego next week.
Say hello to the team at the Reflection booth and come along to our panel on open AI ecosystems.
You’ll hear from:
@real_ioannis (Reflection)
@joespeez (Meta, Llama & PyTorch)
@natolambert (AI2, ATOM Project)
@robertnishihara (Ray, Berkeley)
@ying11231 (SGLang, former xAI)
We’ll be discussing: What does it actually take to build open AI ecosystems? What can we learn from China's approach? What do transparency and sovereignty mean in practice? Where is frontier intelligence heading?
Find the Luma link in the thread to mark it in your calendar.
4
17
132
40,848
20 Nov 2025
amazing read from @Skiminok on why he joined @reflection_ai and on our mission to capture the open-weight frontier. I couldn't have put it better myself...
join us! reflection.ai/careers
6 Nov 2025

🎉 Next week, I am excited to join @reflection_ai as a Member of Technical Staff to help build the open intelligence ecosystem of the Western world.
It's the most exciting opportunity to help software builders in our time, and will shape many years of AI Engineering in the medium-term before AGI. Not just about Western vs Eastern open models, but more about how AI-driven software will look like in 2030.
I spent some time articulating my thoughts about where we're going as a community and why... which became a whole blog post. Take a look, hope it interests you!
(And if it really does, we are hiring in NYC, SF, and London 😉)
alexpolozov.com/blog/reflect…




1
6
761
19 Nov 2025
unbelievably proud of @rajpalleti314 and @rehaanahmad171, and grateful to have been able to advise such a brilliant and, most importantly, kind founding team. @askalphaxiv is going to reinvent how researchers discover and apply cutting-edge AI. this is only the beginning.
19 Nov 2025

We just raised a $7M Seed round co-led by @MenloVentures and @haystackvc with participation from @Shakti_VC, @conviction and @upfrontvc 🚀
We're honored to have the support of incredible angels including @ericschmidt, @SebastianThrun, @sarahookr
Join us: alphaxiv.org/careers

1
1
6
478
Adriel Saporta retweeted
9 Oct 2025
Today we're sharing the next phase of Reflection.
We're building frontier open intelligence accessible to all.
We've assembled an extraordinary AI team, built a frontier LLM training stack, and raised $2 billion.
Why Open Intelligence Matters
Technological and scientific progress is driven by values of openness and collaboration.
The internet, Linux, and the protocols and standards that underpin modern computing are all open. This isn't a coincidence. Open software is what gets forked, customized, and embedded into systems worldwide. It's what universities teach, what startups build on, what enterprises deploy.
Open science enables others to learn from the results, be inspired by them, interrogate them, and build upon them in order to push the frontier of human knowledge and scientific advancement. AI got to where it is today through scaling ideas (e.g. self-attention, next token prediction, reinforcement learning) that were shared and published openly.
Now AI is becoming the technology layer that everything else runs on top of. The systems that accelerate scientific research, enhance education, optimize energy usage, supercharge medical diagnoses, and run supply chains will all be built on AI infrastructure.
But the frontier is currently concentrated in closed labs. If this continues, a handful of entities will control the capital, compute, and talent required to build AI, creating a runaway dynamic that locks everyone else out. There's a narrow window to change this trajectory. We need to build open models so capable that they become the obvious choice for users and developers worldwide, ensuring the foundation of intelligence remains open and accessible rather than controlled by a few.
What We've Built
Over the last year, we've been preparing for this mission.
We’ve assembled a team who have pioneered breakthroughs including PaLM, Gemini, AlphaGo, AlphaCode, AlphaProof, and contributed to ChatGPT and Character AI, among many others.
We built something once thought possible only inside the world’s top labs: a large-scale LLM and reinforcement learning platform capable of training massive Mixture-of-Experts (MoEs) models at frontier scale. We saw the effectiveness of our approach first-hand when we applied it to the critical domain of autonomous coding. With this milestone unlocked, we're now bringing these methods to general agentic reasoning.
We've raised significant capital and identified a scalable commercial model that aligns with our open intelligence strategy, ensuring we can continue building and releasing frontier models sustainably. We are now scaling up to build open models that bring together large-scale pretraining and advanced reinforcement learning from the ground up.
Safety and Responsibility
Open intelligence also changes how we think about safety. It enables the broader community to participate in safety research and discourse, rather than leaving critical decisions to a few closed labs. Transparency allows independent researchers to identify risks, develop mitigations, and hold systems accountable in ways that closed development cannot.
But openness also requires confronting the challenges of capable models being widely accessible. We're investing in evaluations to assess capabilities and risks before release, security research to protect against misuse, and responsible deployment standards. We believe the answer to AI safety is not “security through obscurity” but rigorous science conducted in the open, where the global research community can contribute to solutions rather than a handful of companies making decisions behind closed doors.
Join Us
There is a window of opportunity today to build frontier open intelligence, but it is closing and this may be the last. If this mission resonates, join us.
113
118
1,112
991,186
16 Jul 2025
💪💪💪
16 Jul 2025

Engineers spend 70% of their time understanding code, not writing it.
That’s why we built Asimov at @reflection_ai.
The best-in-class code research agent, built for teams and organizations.
2
364
19 Mar 2025
brilliant feature from @askalphaxiv—auto-generates a blog-style, easy-to-follow breakdown of any research paper!
Here's what it created for my latest work, Symile: alphaxiv.org/overview/2411.0…
12 Mar 2025
We used Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papers
Generate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one click
Understand papers in minutes - not hours
3
17
1,967
Adriel Saporta retweeted

24 Feb 2025
alphaXiv now supports Claude 3.7 for understanding arXiv papers 🚀
While the input length is limiting for multi-paper questions, it delivers remarkably accurate analyses of pseudocode, often catching implementation subtleties
Full integration with paper codebases coming soon 👀
3
20
126
6,762
28 Jan 2025
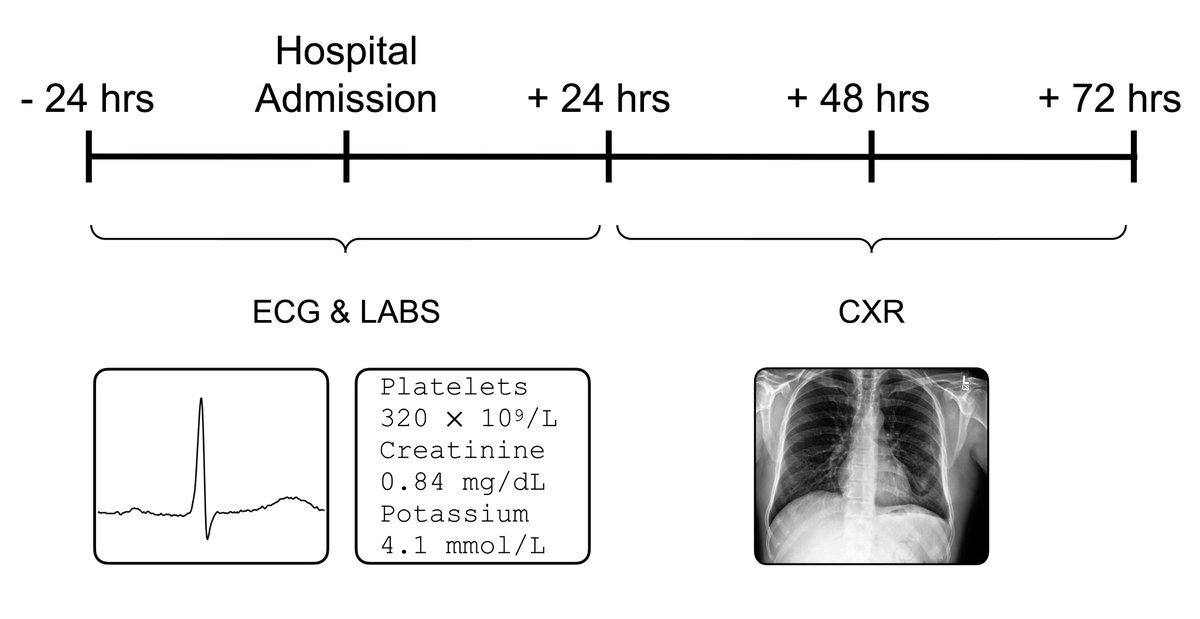
🚨 Announcing Symile-MIMIC: a multimodal clinical dataset where each of the 11,622 samples includes an ECG and blood labs taken within 24 hrs of patient admission, along with a CXR taken 24-72 hrs post-admission.
Perfect for exploring cross-modal relationships in medical data 🏥
2
3
10
1,150
28 Jan 2025
🛠️ We're providing everything you need:
• full dataset in CSV format
• pre-processed tensor data
• code to generate the dataset from MIMIC-IV and MIMIC-CXR
• best model checkpoint trained on Symile-MIMIC using the Symile objective
Check it out! doi.org/10.13026/3vvj-s428
1
2
238
Adriel Saporta retweeted
17 Jan 2025
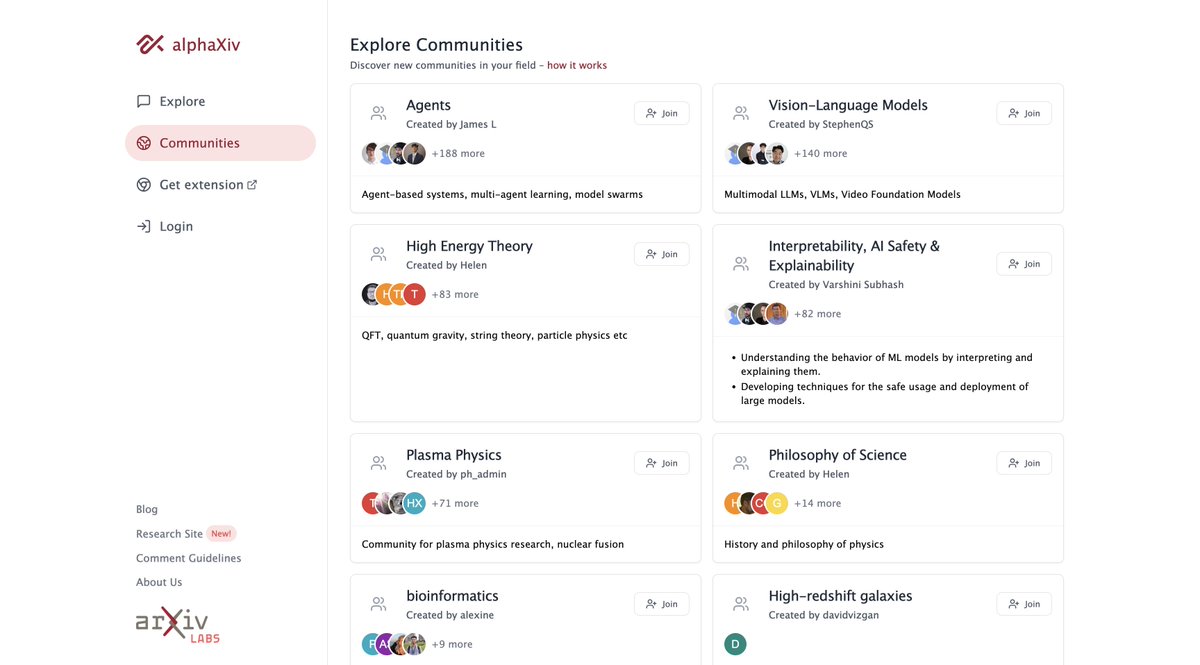
alphaXiv has introduced communities, where members can stay connected with the latest research and discussions within a specific subfield.
What tools and websites do you use to discover new research? Which features on them do you find most useful? Drop your answers below 👇
1
10
38
1,803
Adriel Saporta retweeted

15 Jan 2025
Alphaxiv is an awesome way to discuss ML papers -- often with the authors themselves. Here's an intro and demo by @rajpalleti314 at #neurips2024 .
3
22
152
11,011
Adriel Saporta retweeted
15 Jan 2025
Excited to have @akashnet and @togethercompute generously offering $20K in compute credits for top contributors in the newly formed Agents Community! Join here to stay up to date with the latest in agents research: alphaxiv.org/communities/age…
4
24
2,865
17 Jan 2025
love this so much 😍
15 Jan 2025
Goodreads for arXiv papers💡
What if instead of arbitrary algorithms and tweets, arXiv papers were curated by your research community?
Introducing communities on alphaXiv: bridging papers, discussions, and people in one space.
1
4
392
Adriel Saporta retweeted
12 Dec 2024
Tired of maintaining your github research profile pages🤔?
We are excited to introduce alphaxiv io, where you can now create your research profile with a click of a button 🚀
With just your name, we auto-generate your list of publications with images and a short editable bio!
1
5
31
4,272
3 Dec 2024
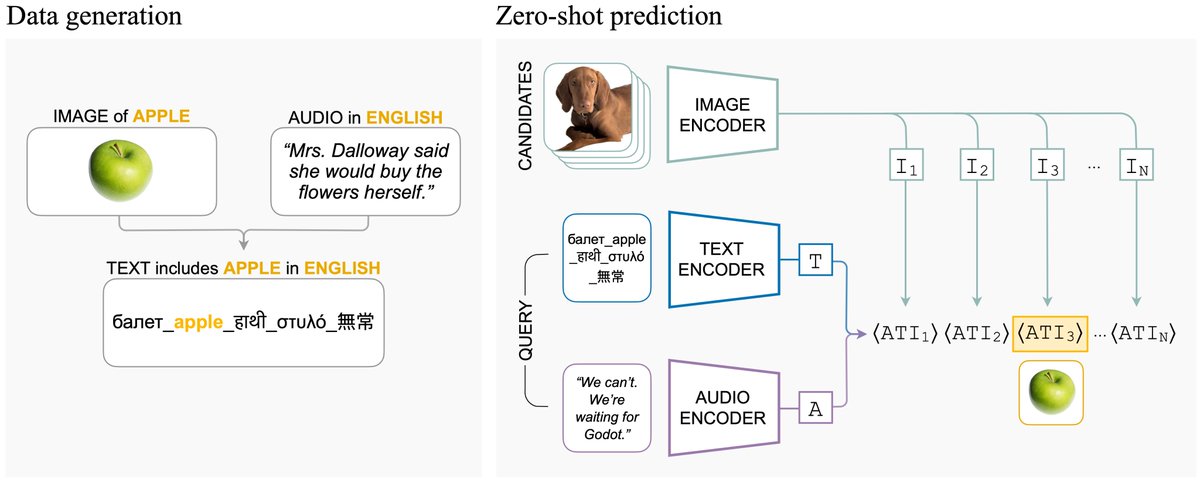
Symile-M3—a new massive multilingual, multimodal dataset of 33 million image 🖼️, audio 🎧, and text 📝 triples across 10 languages—is now LIVE on @huggingface!
Perfect for all your multimodal modeling needs 💅
1
6
16
63,779
3 Dec 2024
🧠 Symile-M3 was specifically designed to test how well a model understands the higher-order relationships between all three modalities. Text and audio are both needed to predict the image—neither alone will work! 🤝
🤗 Start exploring: huggingface.co/datasets/arsa…
1
175
7 Nov 2024
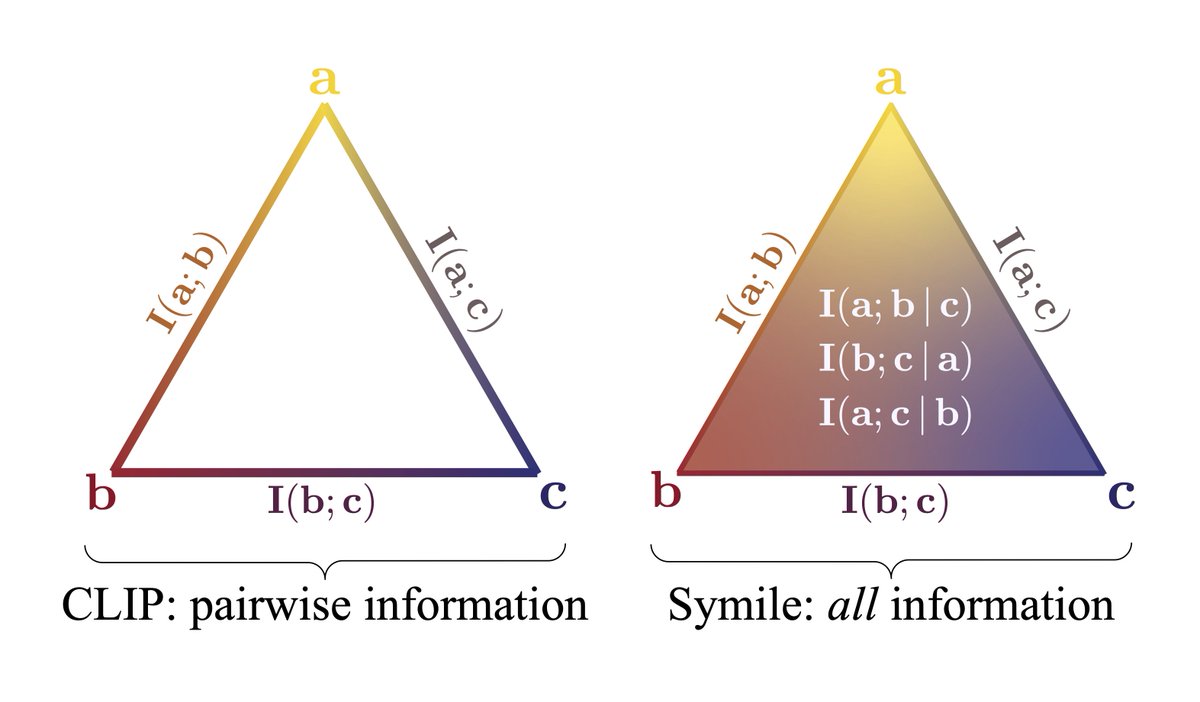
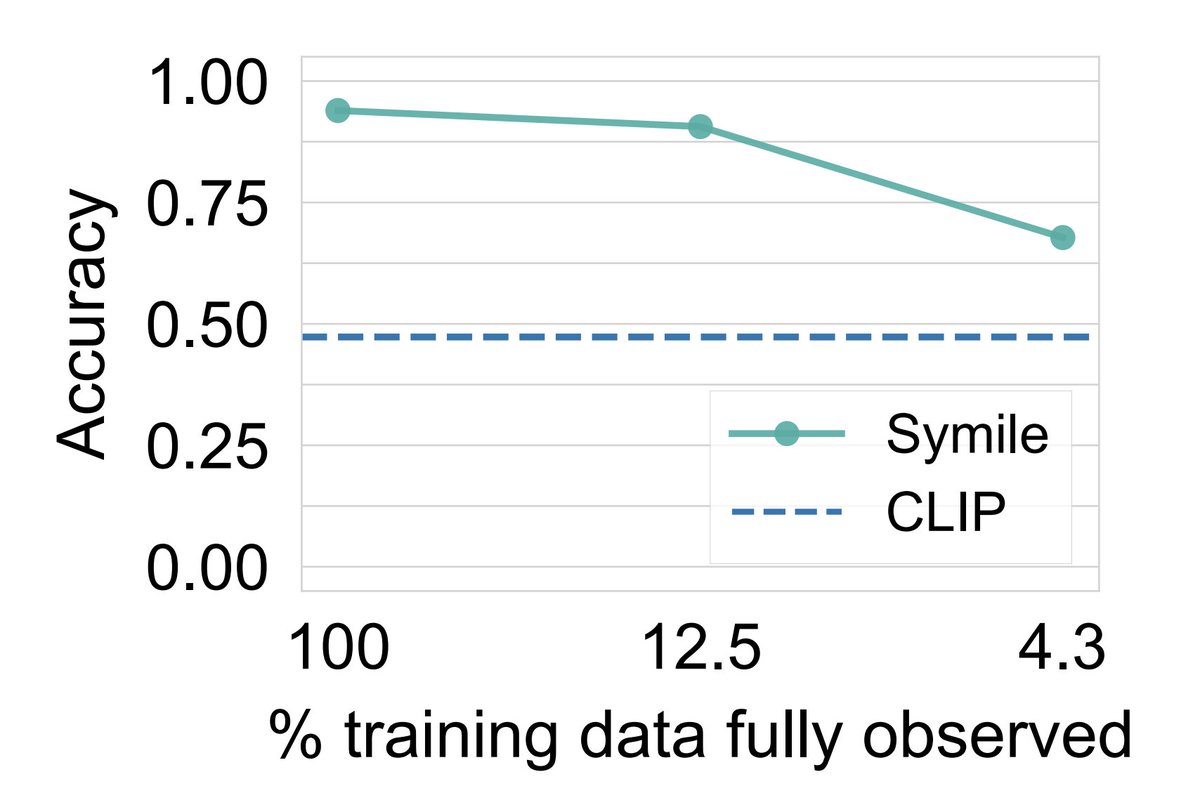
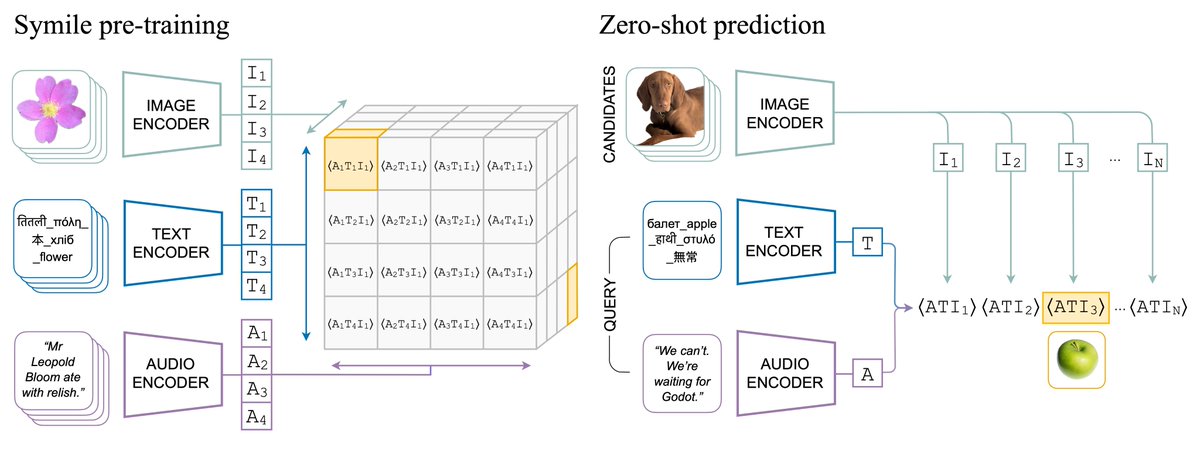
Multimodal representation learning works for 2 modalities, but what if you're working with 3 modalities, like in healthcare, robotics, or video?
📢 Meet Symile: a model-agnostic contrastive loss for any number of modalities with CLIP's simplicity and superior performance✨
1/n
6
54
188
92,971
7 Nov 2024
Want to learn more? 🧠
Check out our #NeurIPS2024 paper and drop any questions for me, @aahladpuli, @marikgoldstein, and Rajesh Ranganath here: alphaxiv.org/abs/2411.01053v… 💬
8/n
2
2
10
785