
Joined June 2025
- Tweets 768
- Following 72
- Followers 693
- Likes 2,239
132 Photos and videos









Pinned Tweet

May 28
🚨CVPR 2026 Accepted
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
in collaboration with @MIT & @IBM
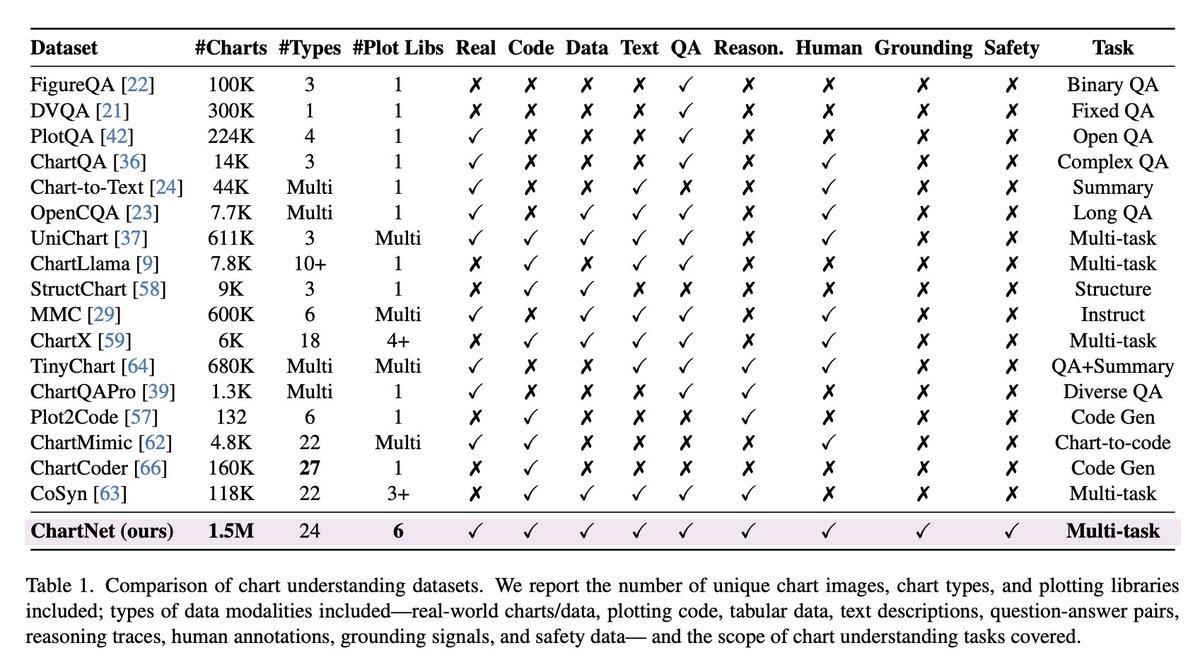
1.5M-sample open-source dataset for robust chart understanding
Each sample aligns a chart image, plotting code, CSV/table data, natural-language summary, and QA with reasoning
Full breakdown👇:
#CVPR26 #CVPR2026
2
2
16
1,058


Jun 5
Kicked off #CVPR2026 with the DataMFM workshop
📍 On June 3rd, the Emerging Directions in Data for Multimodal Foundation Models Workshop brought together speakers from top labs and universities
Ranjay Krishna @RanjayKrishna, Ziwei Liu @liuziwei7, Aishwarya Agrawal @aagrawalAA, Yilun Du @du_yilun, and challenge winners
It is now clear that the next big leaps in multimodal AI will come from better foundations!
Huge thanks to all speakers, organizers, challenge participants, and attendees for making the workshop a success. Abaka AI was proud to support the workshop as an organizer and sponsor🚀
If you missed it, catch highlights and workshop details here: datamfm.github.io/


2
11
299
Jun 3
✈️We're heading to #CVPR2026
🏄Booth #701 with free swags
📡DataMFM workshop with insights and prizes
🪩A Happy Hour with food, drinks, and relaxed chats
DataMFM workshop
June 3rd, Room 111, 1:00–6:00 PM
Happy Hour (spots are limited)
June 6th
Don’t forget to pass by and bring your perspective
DataMFM: datamfm.github.io/
Happy hour, register now: luma.com/rcz2dzht
1
9
154
Jun 1
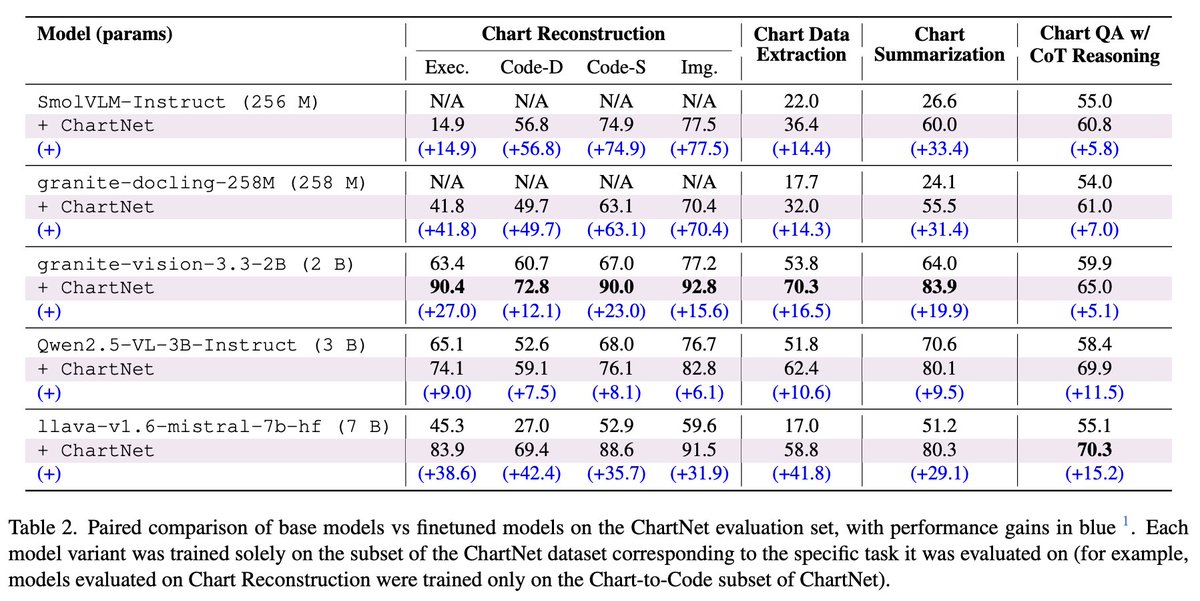
ChartNet: a 1.5M-sample open-source dataset for chart understanding
With an aligned chart image, plotting code, CSV/table data, summary, and QA with reasoning,
Improves chart reconstruction, data extraction, summarization, and chart QA across model sizes.
Huge thanks to respected collaborators @kondic_jovana, @RogerioFeris, @AudeOliva, @ZihanWang123, and everyone involved!
The dataset is out on Hugging Face.
Test it, break it, and we'll see you at #CVPR2026 to discuss!
May 28

🚨CVPR 2026 Accepted
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
in collaboration with @MIT & @IBM
1.5M-sample open-source dataset for robust chart understanding
Each sample aligns a chart image, plotting code, CSV/table data, natural-language summary, and QA with reasoning
Full breakdown👇:
#CVPR26 #CVPR2026
10
191
May 28
🚨CVPR 2026 Accepted
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
in collaboration with @MIT & @IBM
1.5M-sample open-source dataset for robust chart understanding
Each sample aligns a chart image, plotting code, CSV/table data, natural-language summary, and QA with reasoning
Full breakdown👇:
#CVPR26 #CVPR2026
2
2
16
1,058
May 28
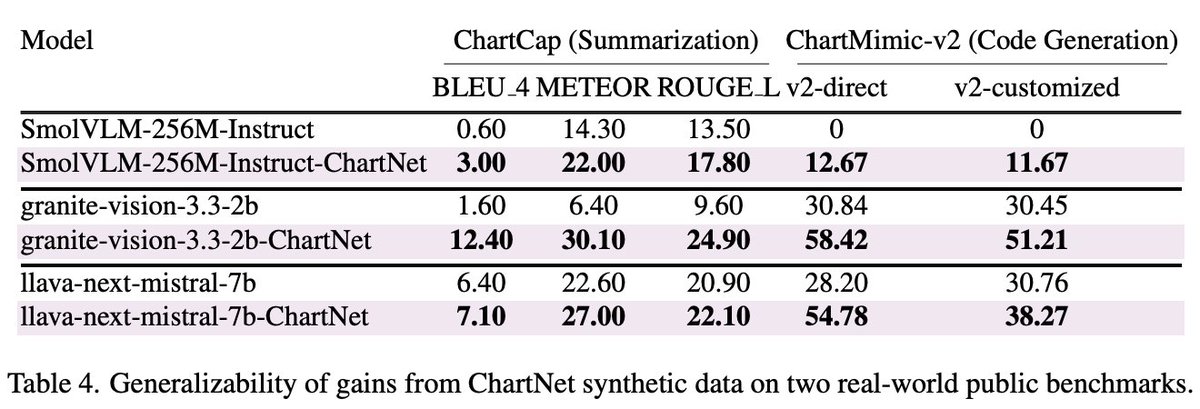
The gains to public benchmarks
Granite-Vision-2B improved from 1.6 to 12.4 BLEU on ChartCap from 30.8 to 58.4 on ChartMimic-v2
1
3
140
May 28
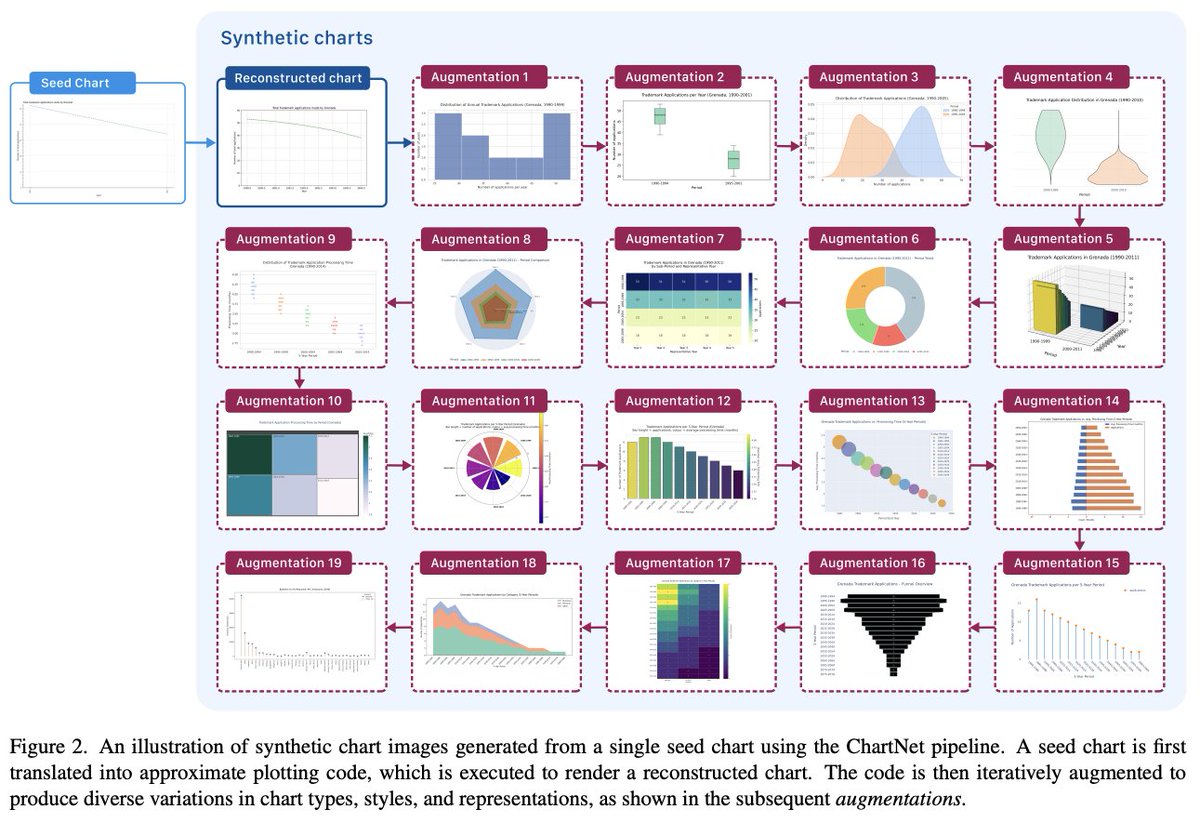
From describing what they see to recovering the structure underneath
For document AI, analytics, scientific plots, business dashboards, and visual reasoning, that difference is huge
Paper: arxiv.org/abs/2603.27064
Dataset: huggingface.co/datasets/ibm-…
3
133

May 11
Why are Coding Agents hitting a "glass ceiling"?
It’s not model scale—it’s post-training data quality.
We built AB-Terminal Bench to prove it. Using just 1.8k curated samples, we boosted @Alibaba_Qwen 3-32B’s Pass@1 from 3.37% → 17.24%. 🚀
The secret? Data must be:
✅ Containerized
✅ Pytest-verified
✅ Reproducible
Generating tasks is easy; providing a true discriminative signal is the hard part.
👉🏻Full blog: lnkd.in/gEY_J5GS
#AI #AbakaAI #CodingAgents #LLM
1
3
164
May 1
ICLR 🇧🇷 was loud.
The signals weren’t.
Where models break.
How reasoning holds.
Why data sits at the center.
Small. Curated.
Right people.
What comes next is taking shape. @iclr_conf
#AI #AbakaAI #ICLR #MachingLearning #LLM #Data
1
8
206
Apr 10
The Full-Duplex Paradox is 2026 AI architectures with 2004 data
Even state-of-the-art models like Moshi rely on the Fisher corpus 8kHz telephone speech from 20 years ago. The hardware has evolved, but inside is the same old (in every sense) data
@nvidia's PersonaPlex paper correctly diagnoses the core bottleneck: finding speech with natural interruptions where speakers are separated at the source.
Synthetic TTS is a band-aid. True conversational AI needs the "messiness" of real human overlap.
Enter the Abaka Bidirectional Speech Corpus:
✅ 20,000 Hours (10x larger than legacy sets)
✅ 7 Global Languages
✅ Hardware-synced dual-channel isolation
✅ Deeply annotated for conversational nuances
Building Spoken Dialogue Models?
DM for a technical sample pack📦

1
7
221