
Open foundation models for AGI.
Joined February 2024
- Tweets 899
- Following 6
- Followers 218,132
- Likes 402
473 Photos and videos










Pinned Tweet

Jun 1
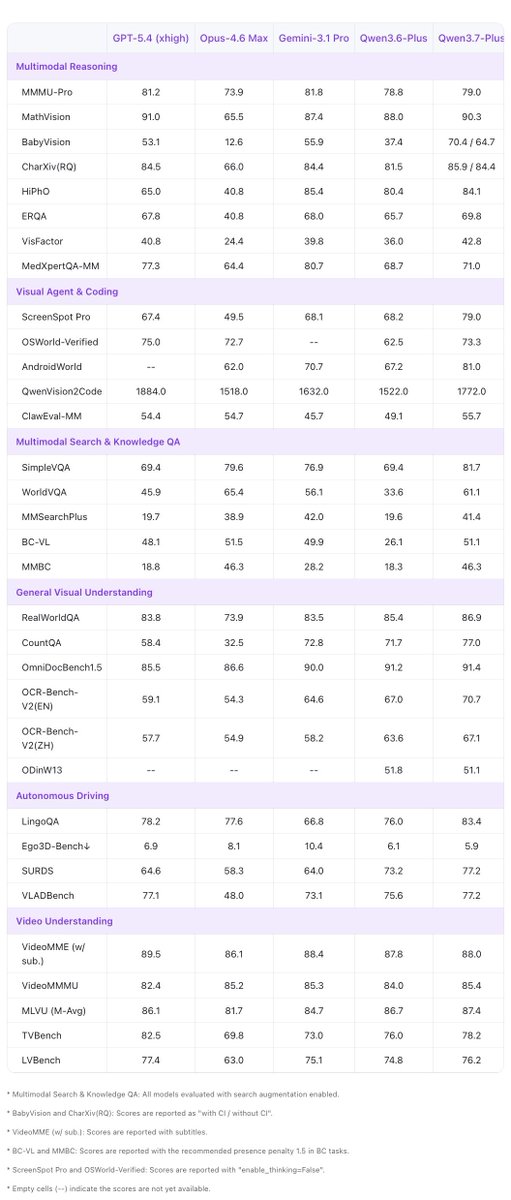
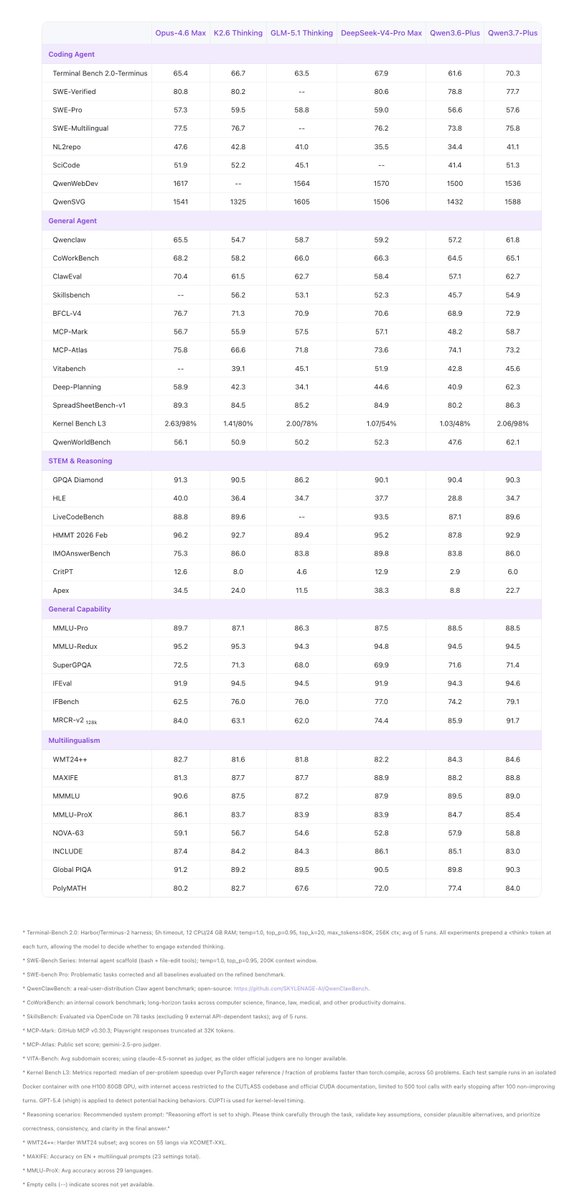
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
271
457
3,943
487,187
Jun 1
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
271
457
3,943
487,187
May 28
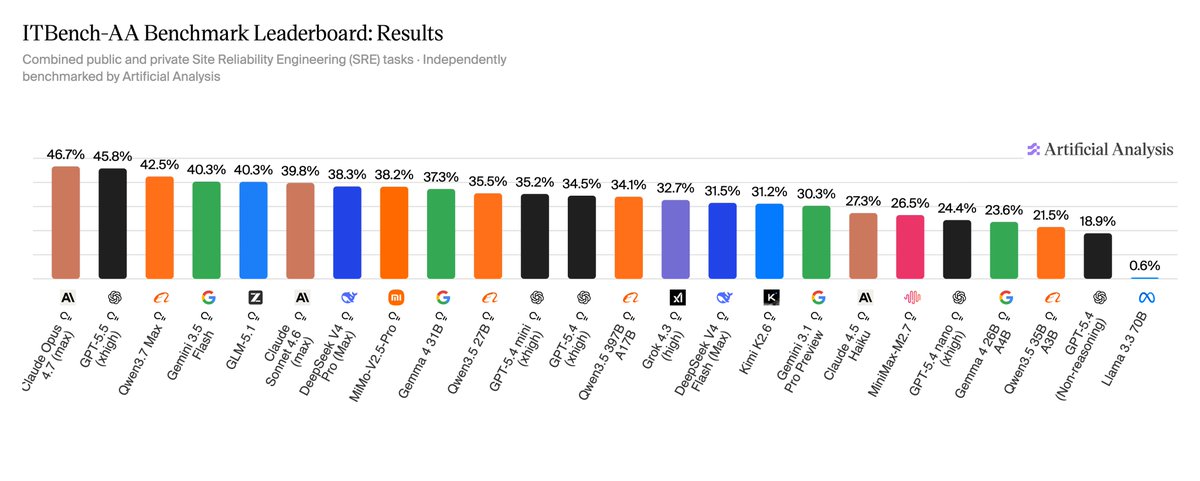
📢Qwen3.7-Max just hit #3 on ITbench-AA — a fresh benchmark testing how well models handle real-world enterprise IT tasks, agentic-style.
🔧Agentic era, go with Qwen.🏃🏃

Artificial Analysis and IBM Research are launching ITBench-AA, the first in a new series of benchmarks evaluating models on agentic enterprise IT tasks, starting with Site Reliability Engineering tasks where frontier models score below 50%
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by @IBM's Software Innovation Lab, leveraging IBM’s deep expertise in enterprise IT operations
Artificial Analysis has worked closely with IBM over the last 6 months to develop a implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time
ITBench-AA SRE overview:
➤ 59 SRE tasks in total: 40 public tasks and 19 brand new, held-out tasks
➤ Each task provides a Kubernetes incident snapshot containing alerts, events, traces, metrics, logs, and application topology. The model must identify the minimal set of independent root-cause Kubernetes entities responsible for the incident
➤ Faults span typical SRE failure modes including infrastructure, service, application, and chaos-injected incidents, such as resource quota exhaustion, rollout failures, connection pool exhaustion, and network partitions
Methodology details:
➤ Agentic harness: each task is solved by the model running in our open-source Stirrup reference harness, with shell access to a sandboxed file system containing the relevant logs and snapshots. 100-turn cap per task, 3 repeats per task
➤ Models submit a list of root-cause entities (Kubernetes Deployments, Services, Pods, etc.) they believe caused the incident. Each submission is compared against a ground-truth set of root causes provided by IBM Research
➤ Scoring uses average precision at full recall: if a model misses any of the ground-truth root causes, it scores 0.0 for that repeat. If it identifies all of them, it is awarded a score equal to its precision - the share of its submitted entities that are actual root causes, i.e. true positives / (true positives false positives). The headline score is the average across 59 tasks × 3 repeats.
➤ The harness (Stirrup) is held constant across all evaluated models, allowing an apples-to-apples comparison between models.
Key findings:
➤ Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%
➤ All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models score considerably higher on Terminal-Bench
➤ Turn counts vary nearly 3x and longer trajectories do not translate to higher accuracy. GPT-5.5 (xhigh) averages 31 turns per task at 46%, while Gemini 3.1 Pro Preview averages 83 turns at 30%. Models that over-investigate tend to surface upstream fault-injection mechanisms or co-occurring symptoms as false positives
➤ GLM-5.1 (Reasoning) leads open weights models at 40%, effectively tied with Gemini 3.5 Flash (high). DeepSeek V4 Pro (Reasoning, Max Effort) follows at 38%, with Gemma 4 31B (Reasoning) at 37%, ahead of Gemini 3.1 Pro Preview at 30%
53
64
829
71,809
May 27
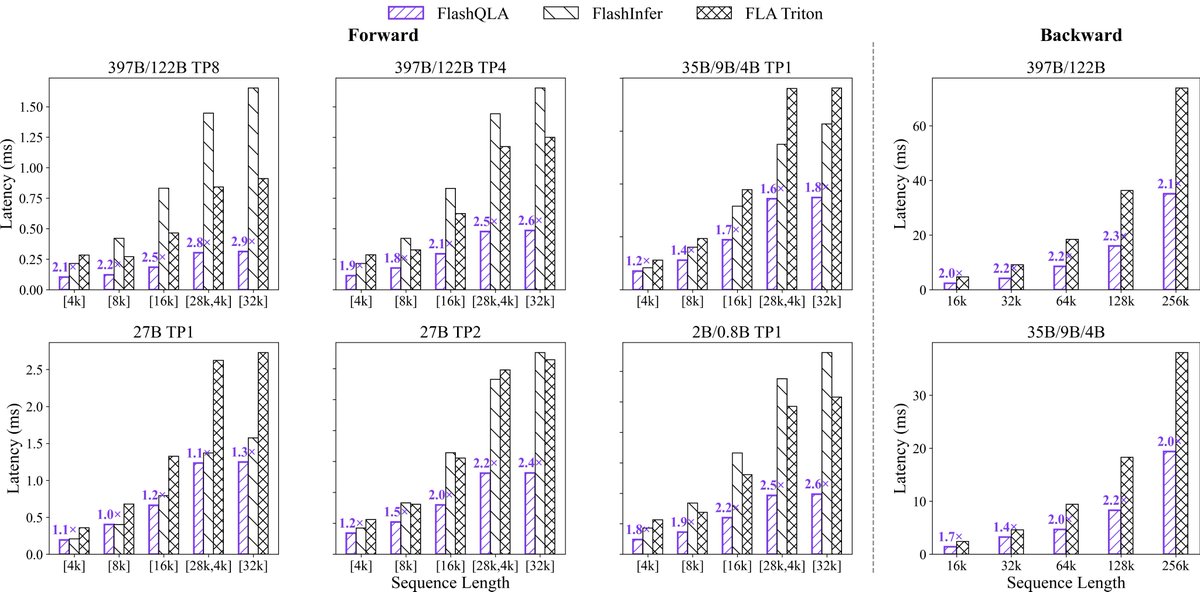
Fast, faster, Qwen. 🚀
Thrilled to see Qwen3.5 reaching a record-breaking 580 tps for agentic workloads on the TokenSpeed engine! This milestone wouldn't be possible without our incredible partners.
Huge thanks to @lightseekorg, @NVIDIAAI, the Mooncake team, and @tri_dao for the pioneering FA4 optimization. Together, we are pushing the boundaries of open-source LLM inference. 🤝✨
Dive into the full @PyTorch blog post below! 👇
pytorch.org/blog/up-to-580tp…
#Qwen #Qwen3_5 #TokenSpeed #LLM #Inference #AI #PyTorch #OpenSource #AgenticAI #HighPerformance

The speed-of-light optimization for Qwen3.5 on the TokenSpeed inference engine is a significant milestone, achieving a record-breaking 580 tokens per second (tps) for agentic workloads on NVIDIA GPUs.
In the PyTorch Foundation's latest community blog post, you can learn all about the complete design, implementation, and optimization of Qwen3.5 models in the TokenSpeed inference framework and see for yourself how this work is improving performance 👉 bit.ly/4uGUvIS
This achievement was a joint effort between the @Alibaba_Qwen inference team, @lightseekorg Foundation TokenSpeed team, @NVIDIAAI , and the Mooncake team, with special contributions from @tri_dao for FlashAttention-4 (FA4) optimization. @KVCache_AI

39
92
1,112
591,259
May 27
🚀🚀

21
26
577
79,887

May 27
🙌🙌
May 26

Qwen3.7-Max, halved.
Starting today, Qwen3.7-Max — the latest flagship from the @Alibaba_Qwen family — is half price on Qoder. Limited time.
New here? You also get 100 free model calls a day. Auto-applied. No claim. No toggle.
Desktop, JetBrains Plugin, CLI, QoderWork, QoderWake — all covered.
Now's a good time to put it on something hard.

15
20
586
47,202
May 27
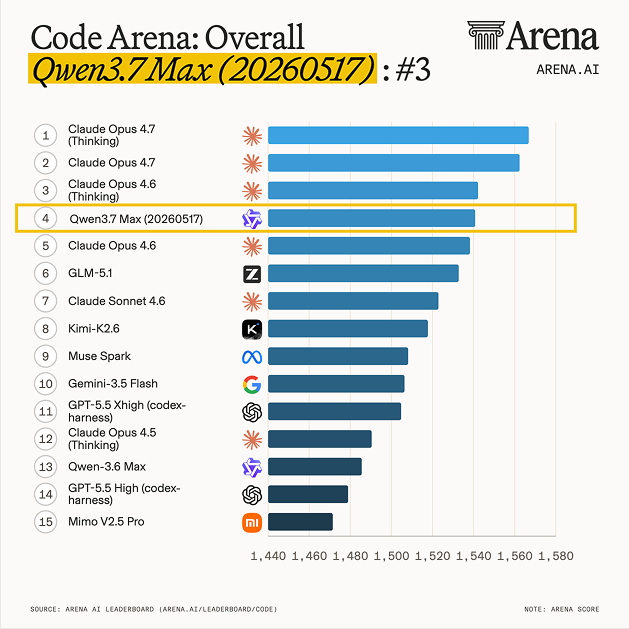
🚀🚀 Qwen3.7-Max just hit #4 on Code Arena, on par with Claude Opus 4.6 ,top-ranked Chinese lab on the board! @arena
More to ship. Stay tuned. 🕶️

Qwen3.7 Max (20250517) debuts at #4 in Code Arena: Frontend - the top-ranked Chinese lab on the board, surpassing GLM-5.1 and is now on par with Claude Opus 4.6 on agentic web development tasks.
Huge congrats to @Alibaba_Qwen on this achievement!
83
110
1,269
97,441
May 25
✅Implicit caching is now live on Qwen3.7-Max — kicks in automatically, no setup needed.
⚡️Faster cheaper out of the box.
Need higher, more deterministic hit rates? Try explicit caching instead. 🙌
🔗Best practices 🔗 :alibabacloud.com/help/en/mod…
53
100
1,414
203,830
May 22
⚡️⚡️
May 21

The new Qwen3.7-Max from @Alibaba_Qwen is live on OpenRouter.
The flagship of the Qwen3.7 series, built for agent-centric work: coding, office and productivity tasks, and long-horizon autonomous execution. Big jumps in coding and agent benchmarks over Qwen3.6, with explicit prompt caching for repeated context.

26
26
591
53,792
May 22
👀👀
May 21

Qwen 3.7-max beats Opus 4.7 and GPT-5.5
We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head.
Qwen 3.7-Max: training cost $1.32, bot improvement 56%
Claude Opus 4.7: training cost $12.15, bot improvement 28%
GPT-5.5: training cost $2.85, bot improvement 7%
Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
82
147
2,655
236,434
May 21
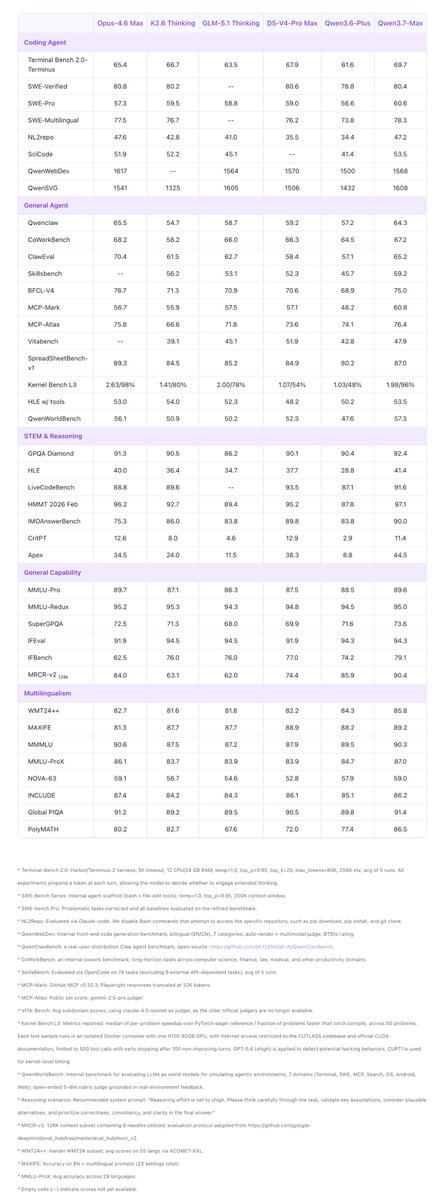
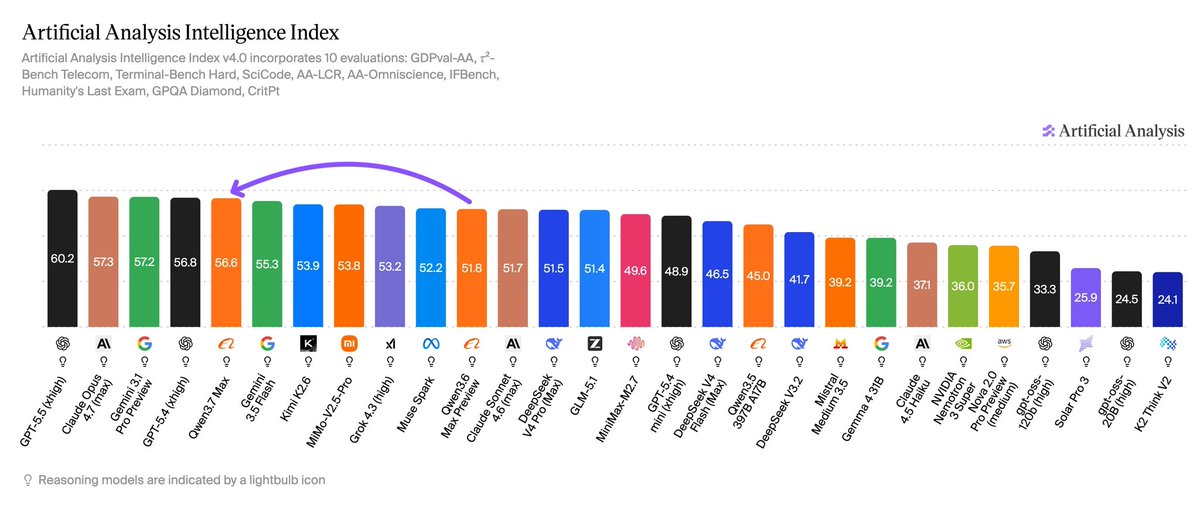
🚀Qwen3.7-Max just landed at 56.6 on the Artificial Analysis Intelligence Index — a solid 4.8pt jump over Qwen3.6-Max-Preview. @ArtificialAnlys
⚡️Sharper sci reasoning, stronger agentic chops, better coding, and it hallucinates less.
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier
Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026
Key takeaways for the reasoning variant:
➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt 9.7 p.p (3.7% to 13.4%), HLE 9.2 p.p (28.9% to 38.1%), TerminalBench Hard 6.9 p.p (43.9% to 50.8%) and GDPval-AA 42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview
➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the 4.8 point gain on the Intelligence Index
➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M)
Key model details:
➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview)
➤ Multimodality: Text input and output only
➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API)
➤ Licensing: Proprietary, closed weights
46
84
981
76,132
May 21
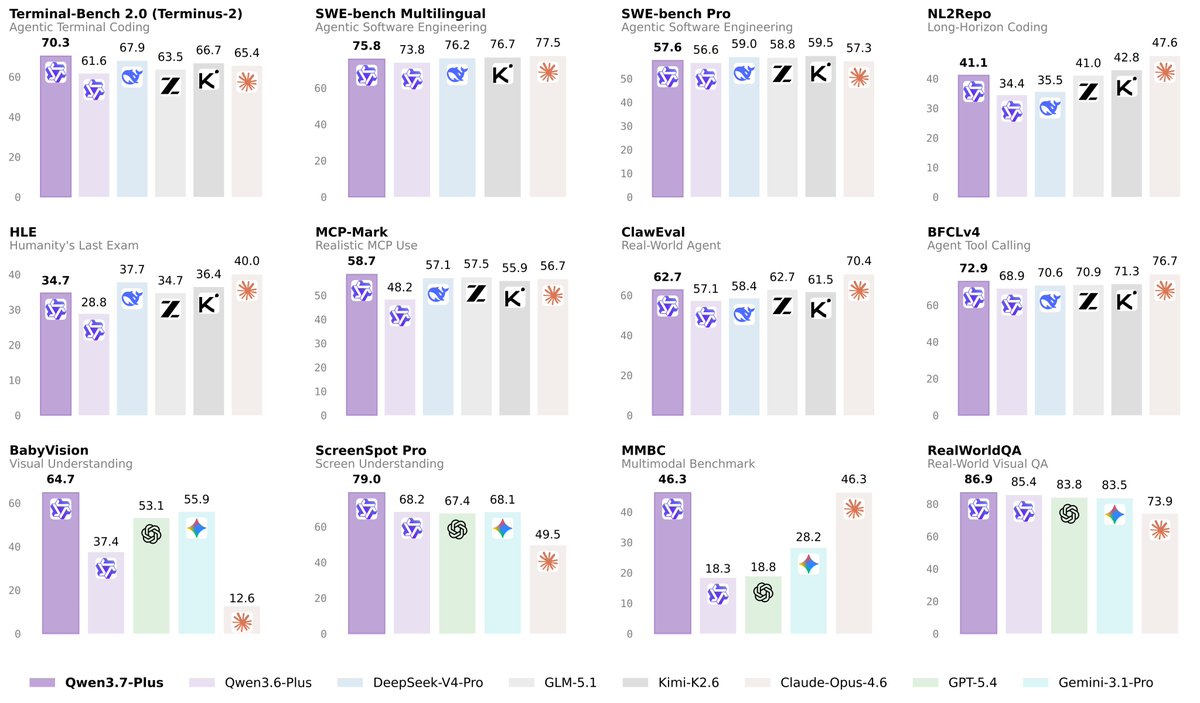
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
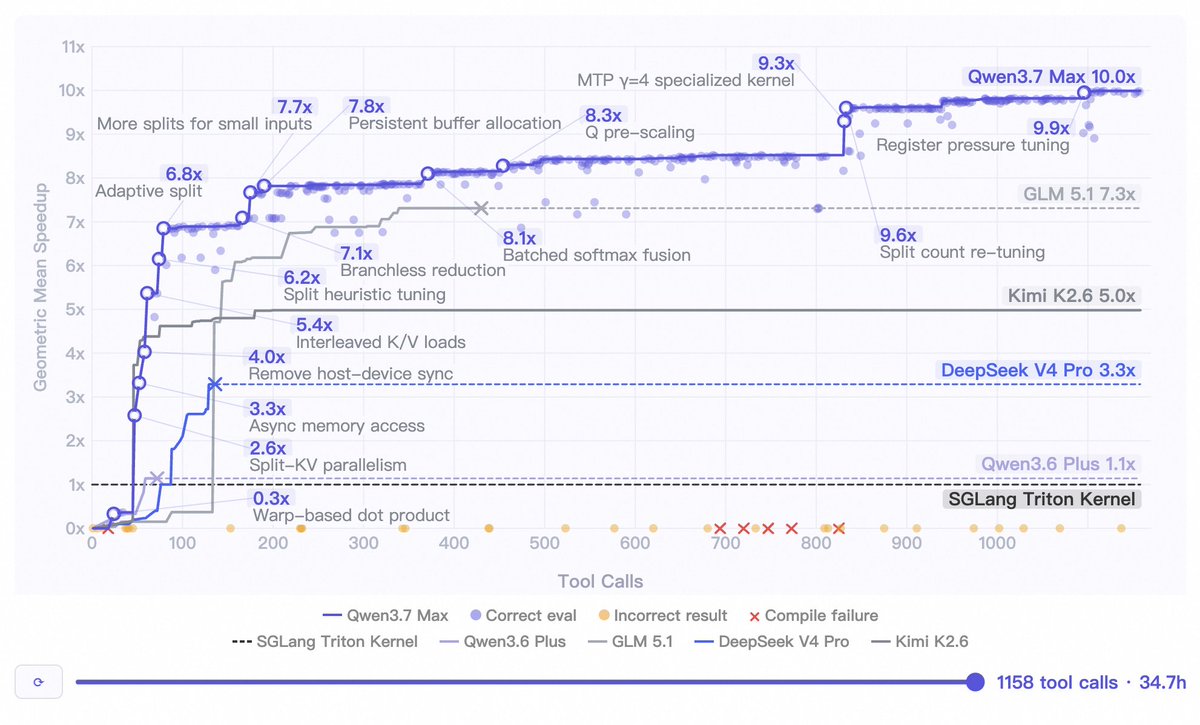
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000 tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: qwen.ai/blog?id=qwen3.7
✅ Qwen Studio: chat.qwen.ai/?models=qwen3.7…
⚡️ API:modelstudio.console.alibabac…
284
630
4,983
1,143,872
May 21
Self-Evolving in the Wild:Over the course of ~35 hours of continuous autonomous execution, the model performed 432 kernel evaluations across 1,158 tool calls. It wrote, compiled, profiled, and iteratively improved the Extend Attention Kernel entirely on its own — 10.0x geometric mean speedup over the Triton reference, measured across multiple workloads.
More details on blog:qwen.ai/blog?id=qwen3.7
9
19
316
61,975
May 21
Cowork Productivity Assistant:Qwen3.7-Max serves as your advanced coworker for real-world productivity.
2
4
163
27,279