
Joined February 2019
- Tweets 225
- Following 322
- Followers 855
- Likes 847
14 Photos and videos









Pinned Tweet

31 Oct 2025
100% agree on the productivity boost. One just needs patience to correct mistakes, which are more subtle than before imo.
I had a nice interaction with GPT-5-pro while proving a convex analysis lemma: arxiv.org/abs/2510.26647
The model didn’t write the full proof, but the interaction was interesting enough for me to write a short report about it. The report illustrates both the productivity gain and the need for careful proof-checking. The model’s contributions are in blue, and the full chat is in the Appendix. You will see my prompts and how I think, so, no judgement please :)
The problem itself has an history in optimal transport (see intro) and comes from a question I was discussing with some UCLA math professors last summer. Simpler than @ErnestRyu's recent result imo, but still very useful in optimal transport!
31 Oct 2025

Totally agree with @ErnestRyu that AI helpers will become very useful for research. But in the near future the biggest help will be with *informal* math, the kind we work out with our collaborators/grad students on a whiteboard. I already use frontier models to help write/debug lemmas for my papers and lectures. AI is fast, but can also misunderstand. So have to still carefully check the lemma statements and proofs. But already a big productivity boost. (Lean provers will automate the proof checking, but the human will still need to check that the lean formalization accurately captures their intent, which humans will be doing for a while.)
6
18
156
46,453
Adil Salim retweeted

May 20
ChatGPT solved an optimization problem that puzzled me for a very long time. Back in summer 2020, I started to work with coauthors on algorithms for optimal transport. We then invented a very simple and elegant algorithm: Bregman Douglas-Rachford splitting method (BDRS).


11
58
513
47,687
May 21
😯

154
May 12
Very elegant
May 12

Imagine that projected gradient descent (PGD) was a new method, discovered today. How would that feel? This is a textbook algorithm... What further research, extensions, improvements and variants would this enable?
In fact, together with Kaja Gruntkowska and Hanmin Li, we have just discovered a sister method to projected gradient descent -- one of equal conceptual importance.
Our method admits the same or very similar guarantees as PGD. However, instead of relying on projections onto the constraint, it relies on linear minimization!
You may say: Did you rediscover Frank-Wolfe?
No.
In contrast to Frank-Wolfe, which uses a global linear minimization oracle (global LMO), our method relies on a local minimization oracle (local LMO). For this reason, we simply call the method "Local LMO" (admittedly, conflating the oracle name with the method name).
Frank-Wolfe theory is much more limited to the theory of Local LMO. Here are some key differences:
1) Frank-Wolfe only works if the constraint is bounded, and its convergence theory depends in the diameter of the constraint set. Local LMO works even for unbounded constraints, and its theory does not depend on the diameter of the constraint set.
2) In fact, Local LMO reduces to gradient descent (GD) in the unconstrained case. If the constraint is affine, Local LMO reduces to (preconditioned) GD in the affine space.
3) While Frank-Wolfe does not converge linearly for smooth strongly convex functions, Local LMO does.
4) While Frank-Wolfe does not converge for non-smooth convex problems (its theory depends on a curvature assumption), Local LMO does.
arxiv.org/abs/2605.08850

6
782
Adil Salim retweeted

🎉 Applications are open for MLSS 2026 — the 50th edition of the Machine Learning Summer School!
Join us in Tübingen for world-class lectures, hands-on sessions, and an amazing ML community. 🧠
Apply now 👉 mlss2026.is.tuebingen.mpg.de…
#MLSS2026 #MachineLearning #SummerSchool #ML
3
26
241
15,780
Adil Salim retweeted
We'll be organizing the Machine Learning Summer School in Tübingen to be held Aug 31st-Sept 11th, featuring top speakers across academia and industry. If you are a student or ML researcher, save those dates and stay tuned for updates! 🚀
13
19
267
17,968
Adil Salim retweeted

Feb 23
Following my visit last month, I've just arrived to Berkeley again!
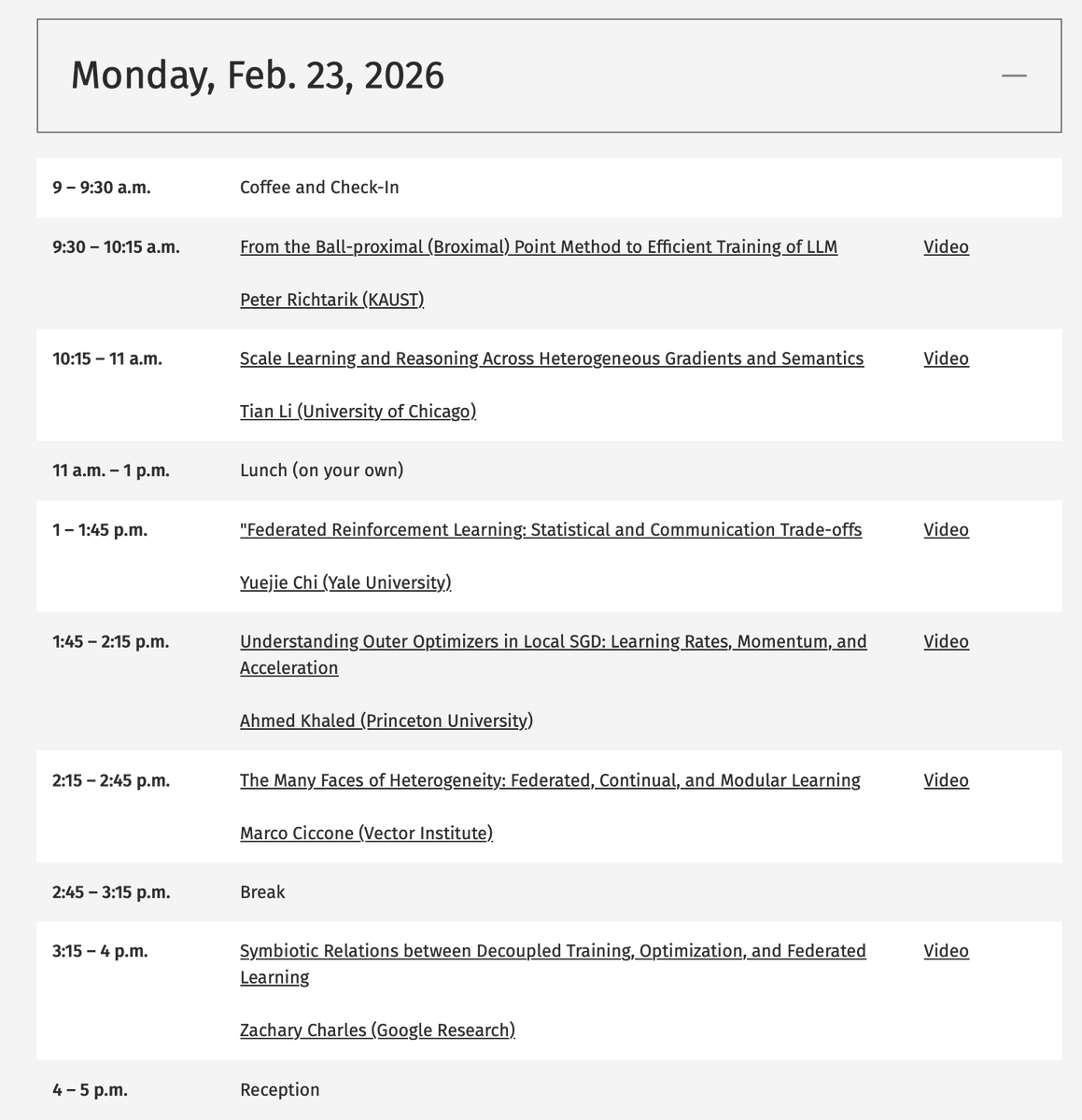
At 9:30am PT today, I am giving the opening keynote talk at the Simons Institute workshop "Learning from Heterogeneous Sources".
simons.berkeley.edu/workshop…
Title of my talk: "From the Ball-proximal (Broximal) Point Method to Efficient Training of LLM". Abstract: simons.berkeley.edu/talks/pe…
During my February visit, I gave a tutorial on "Federated Optimization" at the "Federated and Collaborative Learning Boot Camp". Recordings of my lectures are available on the Simons Institute YouTube channel:
Part 1: youtube.com/live/WcHUu08CLcc…
Part 2: simons.berkeley.edu/talks/pe…
Part 3: youtube.com/live/oT02lHX6s7s…

3
28
1,859
Jan 16
📢New paper out!
We propose an inference algorithm for diffusion models that does not explicitly depend on the ambient dimension and converges exponentially fast. That’s because, unlike most of the competition, we solve the reverse ODE via Picard and not via Euler discretization
9
22
210
15,156
Jan 16
Kudos to Khashayar Gatmiry who led this project (that was part of his 2024 internship at MSR) and to @sitanch
1
8
904
Adil Salim retweeted

23 Dec 2025
I’ll work to make ChatGPT a better tool for accelerating scientific and mathematical discoveries. If you come across failure cases to improve upon (or exciting success stories) please send them my way!
23 Dec 2025
I'm thrilled to welcome @ErnestRyu to our team in @OpenAI !! If you're excited about the progress we've made in making ChatGPT a useful tool for scientists, just wait for what we'll cook for you next year with @ErnestRyu and the rest of the team!
45
31
512
146,760
Adil Salim retweeted

21 Nov 2025
It's now on the arxiv, enjoy!
arxiv.org/abs/2511.16072
21
101
636
127,790
Adil Salim retweeted
20 Nov 2025
Tres heureux de voir du coverage positif sur l'IA en France !!!
lemonde.fr/economie/article/…
6
7
88
7,154
6 Nov 2025
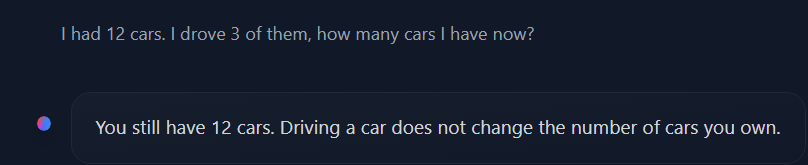
When I say mistakes are more subtle than before. You see the bug?
1
1
28
5,780
Adil Salim retweeted
30 Oct 2025
I firmly believe we are at a watershed moment in the history of mathematics. In the coming years, using LLMs for math research will become mainstream, and so will Lean formalization, made easier by LLMs. (1/4)
46
185
1,308
474,566
Adil Salim retweeted

31 Oct 2025
I crossed an interesting threshold yesterday, which I think many other mathematicians have been crossing recently as well. In the middle of trying to prove a result, I identified a statement that looked true and that would, if true, be useful to me. 1/3
61
299
2,495
893,564
30 Oct 2025
Wow!! I tried to prove this in 2019, without success. This is embarrassing lol
I remember in 2023 @SebastienBubeck told me something like "Can an LLM rediscover Nesterov's acceleration? Not now, but certainly soon"
25 Oct 2025

The proof, cleaned up and typed up by me, resolves the 42-year-old open problem:
5/N
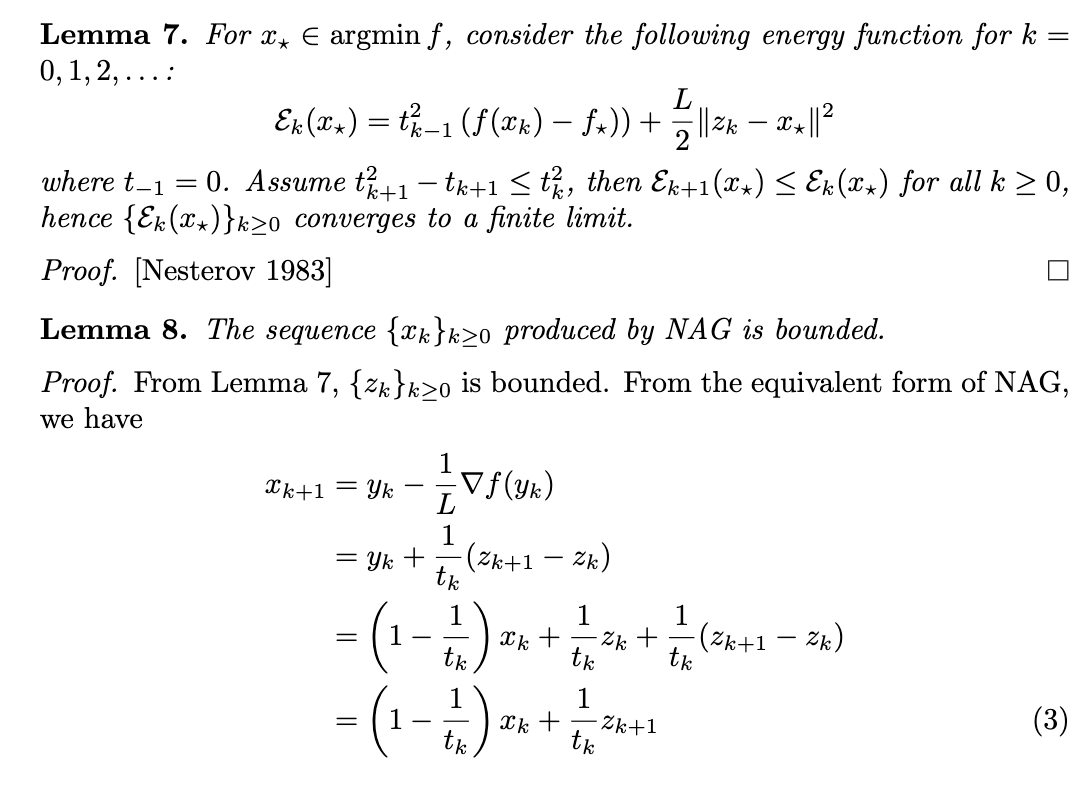

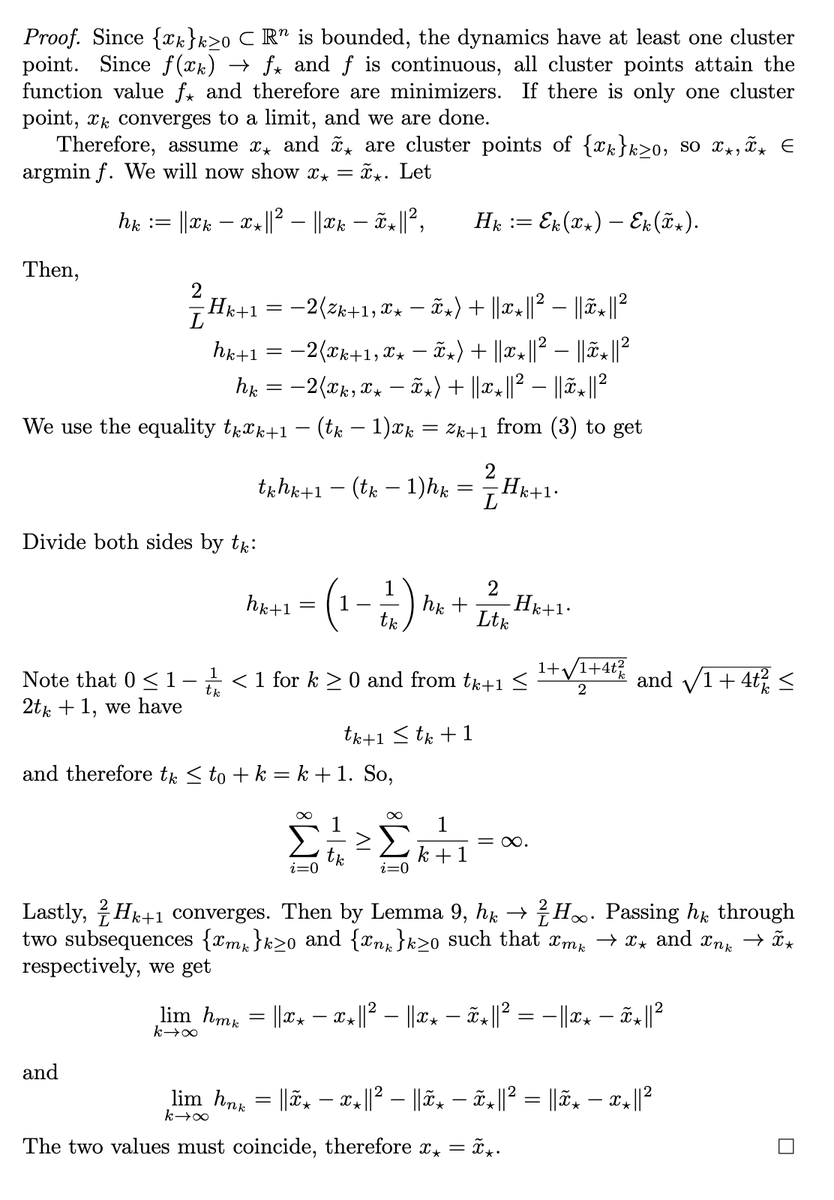
3
18
227
39,252
Adil Salim retweeted

8 Sep 2025
check out this PhD opportunity for female students from Africa at @UPFBarcelona :
upf.edu/web/phd-engineering/…
i have hired my amazing student @NnekaOkolo4 via this program, which was a great success. hope i can find someone this time as well!
let me know if you have any questions
1
8
20
3,515
Adil Salim retweeted

7 Aug 2025
Given the recent loss of its $25 million NSF grant (amongst all UCLA grants), the Institute for Pure & Applied Mathematics is now fundraising. Donation link here: giving.ucla.edu/Campaign/Don…
12
46
9,202