
assistant professor of computer science @hseas, learning theorist, 🎹
Joined April 2020
- Tweets 198
- Following 204
- Followers 1,876
- Likes 804
37 Photos and videos


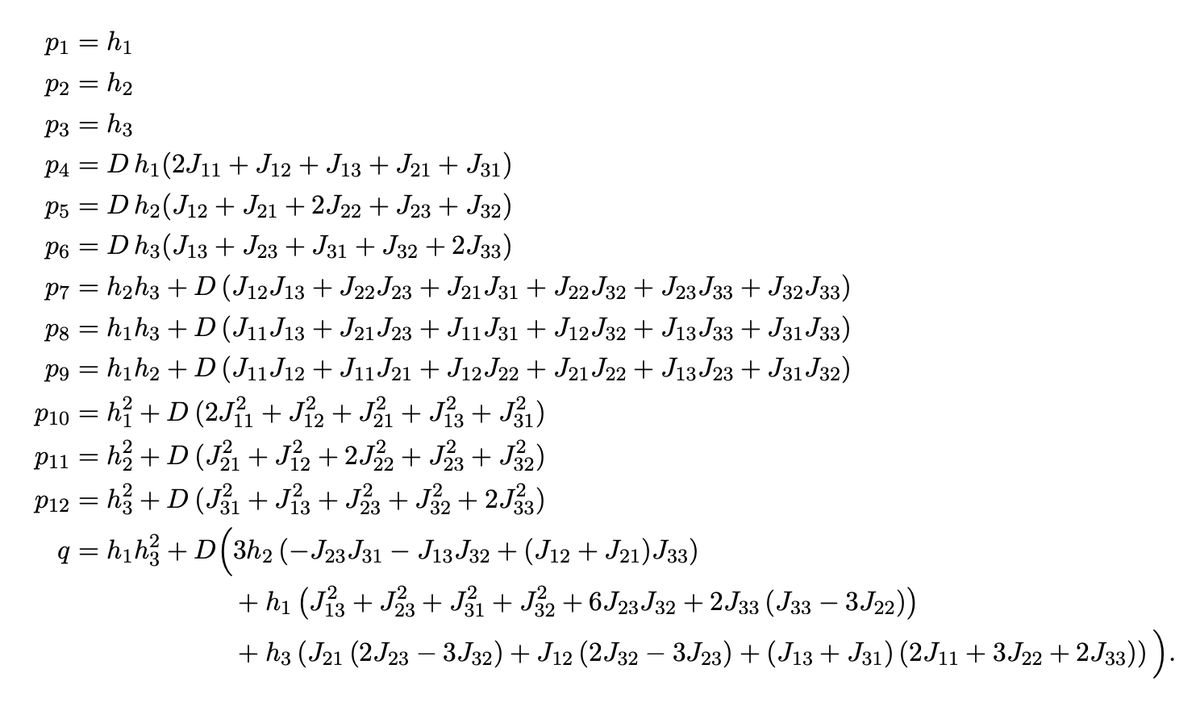









Pinned Tweet

11 Feb 2025
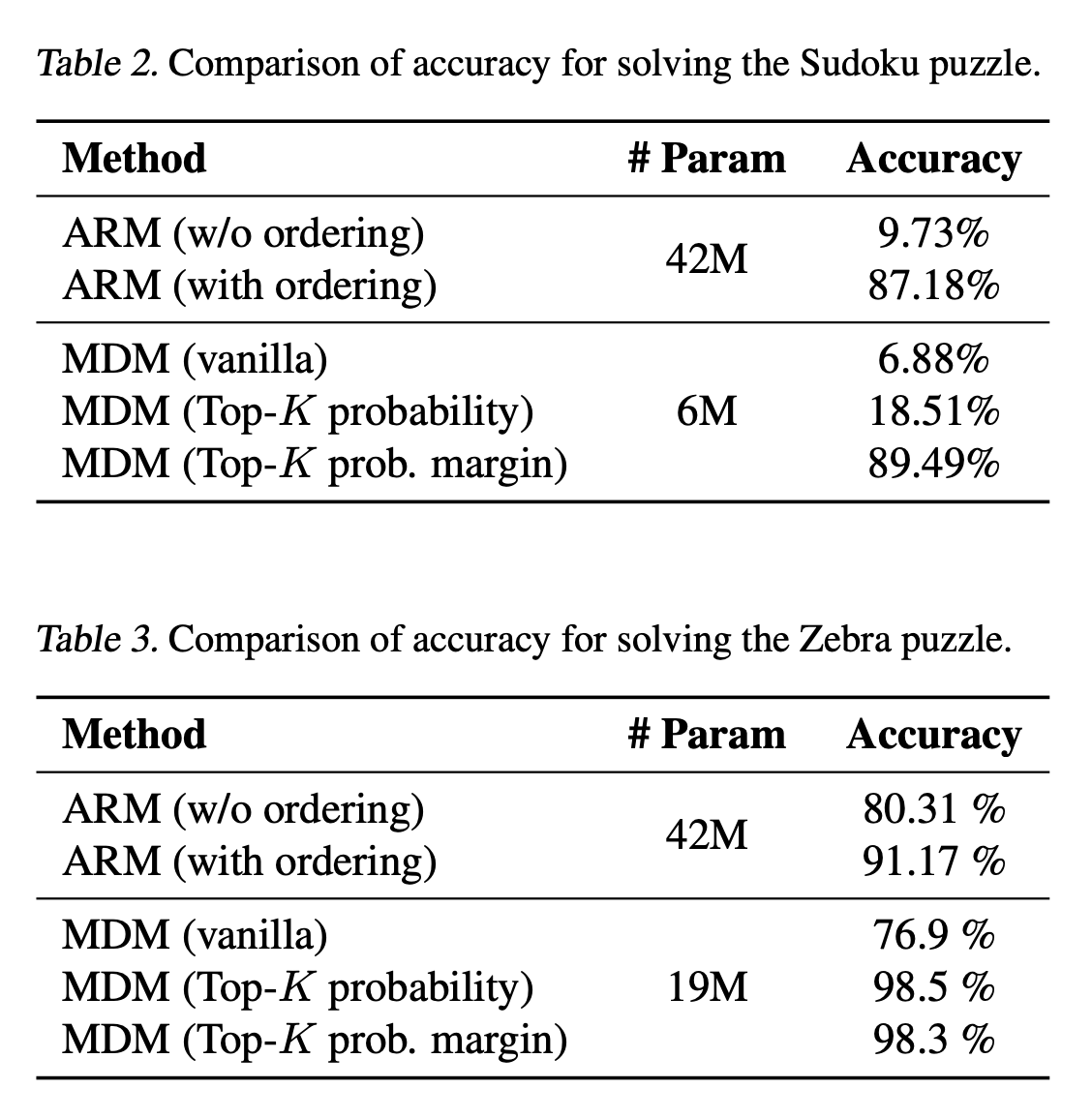
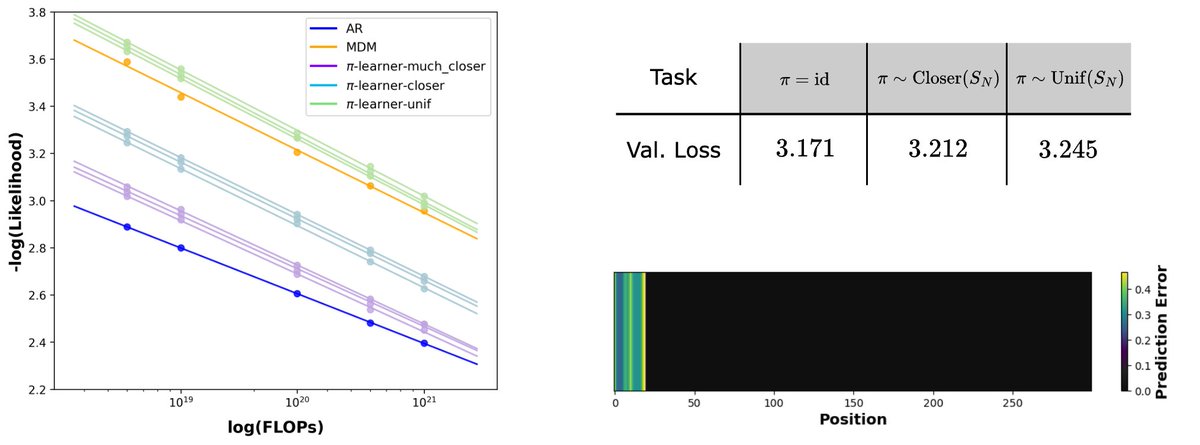
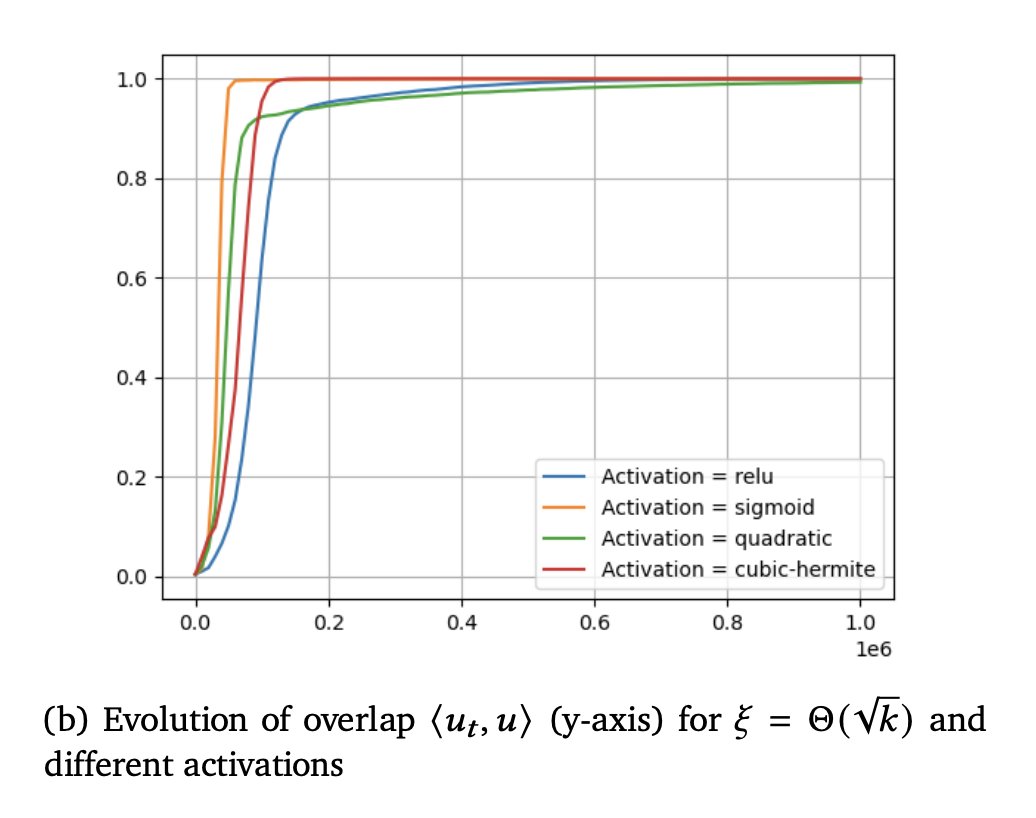
Excited about this new work where we dig into the role of token order in masked diffusions!
MDMs train on some horribly hard tasks, but careful planning at inference can sidestep the hardest ones, dramatically improving over vanilla MDM sampling (e.g. 7%->90% acc on Sudoku) 1/
5
21
154
38,922
Sitan Chen retweeted
We’re organizing the first workshop on non-AR Language Models (eg discrete diffusion models)! Excited to be part of this and to collaborate with so many good researchers / and have amazing speaker line-up!!
Check it out here: pengzhangzhi.github.io/NonAR…
Jun 9

Diffusion language models are super cool — but what's next? 🤔
Non-autoregressive LMs have come a long way: they decode in parallel, generate in any order, can revise their own outputs, and they've been scaled up. The field has grown up fast. So I keep asking — What are the most urgent open problems? what's the next paradigm? Where is all of this heading?
I wanted a place where we could actually get in a room and hash that out together. That's what NonAR-LM @ COLM 2026 is: a platform for the whole community — industry and academia — to talk about the future of language generation beyond next-token prediction.
We've brought together researchers from OpenAI, Google DeepMind, Meta, NVIDIA, and ByteDance, with academics from Duke, Stanford, Princeton, UCLA, Harvard, Cornell, HKU, and Oxford. We'd genuinely love for you to be part of it.
⏳ Two weeks to go — submissions close June 23. If you work on language generation beyond next-token prediction — diffusion, flow matching, or any-order autoregression — we'd love to see your work. Up to 8 pages, non-archival, double-blind.
🔗 Website & CFP: pengzhangzhi.github.io/NonAR…
📨 Submit on OpenReview: openreview.net/group?id=colm…
🧑⚖️ We're also recruiting reviewers — a light load, perfect for students and early-career researchers who want a close look at the newest work. Sign up: forms.gle/K3wfLD6WjuHgXCT78
A huge thanks to the speakers & panelists making this one fun: @StefanoErmon · Shansan Gong · @adityagrover_ · @thjashin · @ArashVahdat · @MengdiWang10 · @ssahoo_ · @aaron_lou
and our wonderful co-organizers: @mariannearr · @Jaeyeon_Kim_0 · @siyan_zhao · @AlexanderTong7 · @ArnaudDoucet1 · @bodonoghue85 · @kb_syx
Help us spread it out, repost appreciated!

1
6
50
5,626
Feb 17
Excited about this paper where we revisit the core message of our ICML '25 work (diffusion LM training is hard, but enables any-order generation) and develop a new paradigm that achieves 2.5x training speedups by aligning the orders encountered at inference and over training!

🚨🚨🚨 Now you can stop training your masked diffusion models ''for the worst''.
We propose 🐆PUMA🐆--Progressive UnMAsking, a simple modification of the forward masking process that speeds up the masked diffusion training.
1
2
34
4,581
Sitan Chen retweeted

Jan 16
📢New paper out!
We propose an inference algorithm for diffusion models that does not explicitly depend on the ambient dimension and converges exponentially fast. That’s because, unlike most of the competition, we solve the reverse ODE via Picard and not via Euler discretization

9
22
210
15,156
Sitan Chen retweeted

Adam Klivans Wins Test of Time Award at FOCS 2025:
cs.utexas.edu/news/2025/adam…
7
11
75
33,067
8 Dec 2025
Proponents of diffusion language models tout their ability to generate many tokens in parallel. Skeptics argue this is fundamentally broken as it ignores token dependencies. Who's right? 🤔🤔🤔
🚀 In a new work, we rigorously prove that the picture is a lot more nuanced... 1/
3
24
126
16,557
8 Dec 2025
Was very fun working with my amazing coauthors Kevin Cong and Jerry Li on this project! Remarkably, Kevin is still an undergrad but could easily pass for a seasoned PhD student given the mathematical level at which he operates..
Paper link: arxiv.org/pdf/2511.04647 7/
1
11
1,094
8 Dec 2025
Additionally, please check out the nice concurrent work of Lavenant & Zanella which also proved the connection to Riemann approx of the information curve, plus prior works of Li & Cai and the seminal work of Tim Austin giving operational meaning to dual total correlation. 8/8
6
980
28 Nov 2025
Congratulations to the authors for building this awesome resource for the community! Excited to see FlexMDM here 😄
28 Nov 2025
We’re releasing UNI-D², a unified codebase for discrete diffusion language models 🤝🚀
Co-led with @vincentpaulinef and an amazing advisor team: @stefanAbauer, @AlexanderTong7 , @andrea_dittadi, @AMK6610, @KaplFer 🙌
🔗 GitHub: github.com/nkalyanv99/UNI-D2
📚 Docs: nkalyanv99.github.io/UNI-D2/
Reproduce and extend state-of-the-art baselines with one toolkit. Let’s move beyond autoregressive models and push discrete diffusion together 🧵👇
12
1,831
Sitan Chen retweeted

10 Nov 2025
🚨🚨🚨 Now your Masked Diffusion Model can self-correct! We propose PRISM, a plug-and-play approach fine-tuning method that adds self-correction ability to any pretrained MDM! (1/N)
6
51
302
47,833
Sitan Chen retweeted

29 Oct 2025
Researchers have demonstrated an algorithm that characterizes quantum systems of any size with optimal efficiency and precision without needing prior information or assumptions about the system’s structure. go.aps.org/4hr1wHO
3
2
8
2,498
Sitan Chen retweeted

17 Oct 2025
We found a new way to get language models to reason. 🤯
No RL, no training, no verifiers, no prompting. ❌
With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.
74
250
1,705
277,291
10 Oct 2025
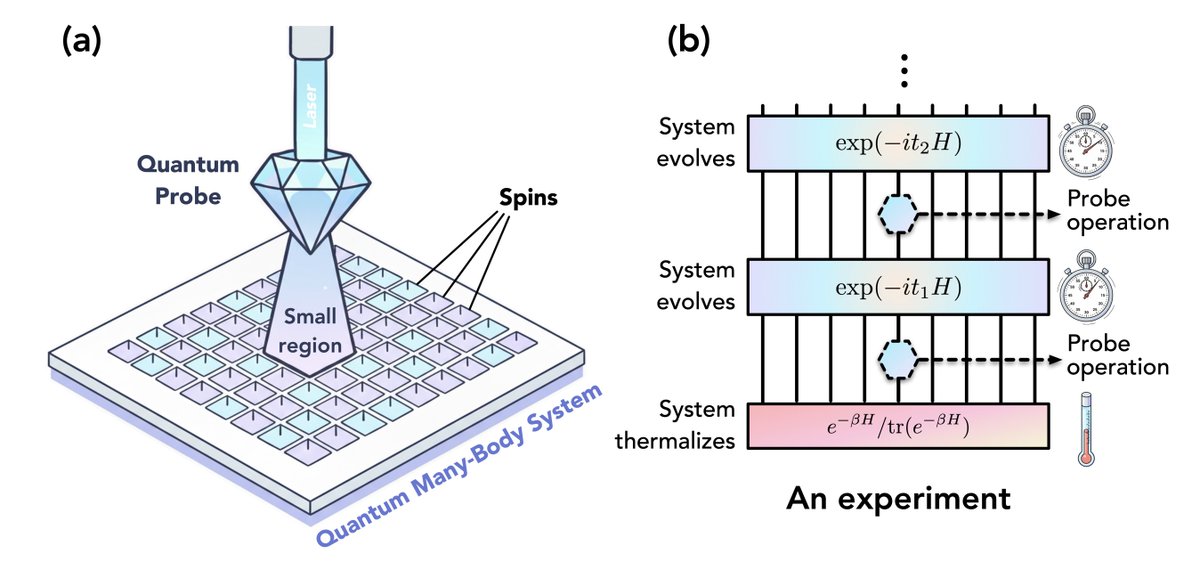
⚛️⚛️⚛️ Thrilled to share our new paper on quantum probe tomography!
In this work we ask:
Can one learn about a complex quantum system given only the ability to control and measure a single particle?
1/
2
15
83
7,106
10 Oct 2025
Hard to believe it's been ~5 years since @JordanCotler, @RobertHuangHY, and I started working together on quantum learning under realistic constraints, and while the world looks very different these days, the sheer fun of collaborating w/ them remains a reassuring constant 😀 5/
1
7
531