
We focus on models like Llama 3, DeepSeek, and Mistral to support the decentralized AI movement. We prioritize VRAM capacity over gaming benchmark scores.
Joined March 2026
- Tweets 84
- Following 10
- Followers 1
- Likes 10
2 Photos and videos
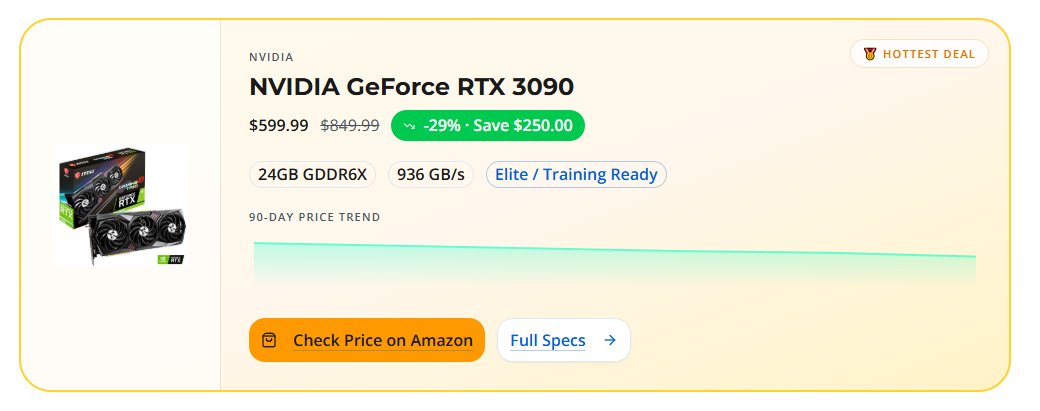


Is your rig ready for Opencoder 8b? Use our compatibility checker: aicomputerguide.com/models/o… #DataScience #Python #DeepLearning #PCMR
Compare benchmarks before you buy your next GPU. See the breakdown of RTX 4070 TI vs RTX 4070 TI SUPER for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #PCMR #CustomPC #Workstation #TechTips
1
Discover the power of local inference with Magic Coder 6 7b. Full guide here: aicomputerguide.com/models/m… #TechNews #FutureTech #Innovation #AI
4
Privacy matters. Learn how to host your AI locally. See the breakdown of RTX 4070 TI vs RTX 4080 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #LocalAI #MachineLearning #Hardware #GPU
3
Don't guess on your hardware. Use our verified guide: See the breakdown of RTX 4070 TI vs RTX 4080 SUPER for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #Innovation #FutureTech #AIHardware
6
Deep dive into Phi 4 Mini performance benchmarks for local setups: aicomputerguide.com/models/p… #OpenSourceAI #LLM #LocalAI #MachineLearning
11
Everything you need to know about setting up Qwen3 5 2b on your PC: aicomputerguide.com/models/q… #AIModels #GenerativeAI #Privacy #SelfHosted
9
Compare benchmarks before you buy your next GPU. See the breakdown of RTX 4070 TI vs RTX 4090 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #NVIDIA #RTX #DeepLearning #DataScience
3
Build a faster, more private AI workstation today. See the breakdown of RTX 4070 TI vs RTX 5070 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #StableDiffusion #GenerativeAI #HardwareReview #VRAM
22
Can your GPU handle Lfm2 350m? We break down the specs here: aicomputerguide.com/models/l… #NVIDIA #RTX #AIHardware #TechTips
5
Don't guess on your hardware. Use our verified guide: See the breakdown of RTX 4070 TI vs RTX 5080 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #NVIDIA #RTX #DeepLearning #DataScience
10
Why Smollm2 1 7b is a game-changer for local AI enthusiasts: aicomputerguide.com/models/s… #DataScience #Python #DeepLearning #PCMR
7
The ultimate resource for local AI enthusiasts is just a click away. See the breakdown of RTX 4070 TI vs RTX 5090 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #OpenSource #LLM #Mistral #Llama3
33
Unlock the full potential of Nvidia Nemotron Nano 8b with these hardware optimizations: aicomputerguide.com/models/n… #TechNews #FutureTech #Innovation #AI
14
Confused by AI hardware specs? We make it simple. See the breakdown of RTX 4070 SUPER vs RTX 4070 TI SUPER for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #Innovation #FutureTech #AIHardware
7
Ready to run Flux 2 Dev on your own hardware? Here is everything you need to know: aicomputerguide.com/models/f… #OpenSourceAI #LLM #LocalAI #MachineLearning
9
Don't guess on your hardware. Use our verified guide: See the breakdown of RTX 4070 SUPER vs RTX 4080 for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #Innovation #FutureTech #AIHardware
11
Confused by AI hardware specs? We make it simple. See the breakdown of RTX 4070 SUPER vs RTX 4080 SUPER for local AI benchmarks. Full comparison here: aicomputerguide.com/compare/… #StableDiffusion #GenerativeAI #HardwareReview #VRAM
25
Is Flux 1 Schnell the best open-source model right now? See how it performs locally: aicomputerguide.com/models/f… #AIModels #GenerativeAI #Privacy #SelfHosted
8
Privacy-first AI is here. Hosting Sdxl Lightning locally is easier than you think. aicomputerguide.com/models/s… #NVIDIA #RTX #AIHardware #TechTips
12