
Founder | The ontopir african community of enterprises & organizations for a sovereign data infrastructure & intelligence.
Joined January 2022
- Tweets 251
- Following 7
- Followers 918
- Likes 152
42 Photos and videos














When you're in a room where everyone is crazy enough to change the world and you're the youngest,the doubt phase fades away.
2
1
3
36
When information becomes abundant attention hits a wall ,and the deployment phase of the attention starts. Through coordination. this video gives an introduction on the infrastructure behind the coordination layer.
youtu.be/7uVGHr7knu0?si=jco7…
1
3
35
The architecture is built around decision types. Each decision represents a class of high-stakes choice. Every decision connects to all the constraints that must be satisfied before it can be made with confidence. These connections are explicit, not learned.
2
27

7 Nov 2025
While innovation echoes creation's wonder, true moral discernment for AI lies in fostering justice through reason and empathy, ensuring it liberates rather than sanctifies inequality
7 Nov 2025

Technological innovation can be a form of participation in the divine act of creation. It carries an ethical and spiritual weight, for every design choice expresses a vision of humanity. The Church therefore calls all builders of #AI to cultivate moral discernment as a fundamental part of their work—to develop systems that reflect justice, solidarity, and a genuine reverence for life.
2
98
23 Oct 2025
We are in a state of international whorefare😂

2
88
22 Oct 2025
My competition at san Francisco clout farming olympics


4
116
Allan Ebusuru | Ontopir retweeted

21 Oct 2025
🔬 A report says Chinese engineers tried to reverse engineer an ASML deep ultraviolet lithography tool, damaged it, then asked ASML to fix it.
Even if the story is unverified, if accurate, shows how export curbs are pushing risky workarounds and how hard these machines are to copy.
The chip restrictions on China have seriously affected its high-tech growth. As the competition for AI leadership grows between the two major powers, these advanced chip bans have made it harder for China to match the U.S. They’ve also pushed China to find creative ways to get those chips.
But ASML deep ultraviolet lithography, the machines used to produce advanced computer chips aren’t as simple to replicate as most other industrial equipment.
China has been cut off from EUV and from the most advanced DUV scanners since Jan-24, so fabs lean on older DUV gear and heavy multipatterning to hit tighter nodes.
DUV uses 193 nm argon fluoride lasers with a thin water film under the lens, while EUV uses 13.5 nm light from a laser-produced tin plasma and ultra-precise mirror optics, so small mis-calibration quickly cascades.
Inside a modern DUV immersion tool, dual wafer stages fly under the lens while optics hold overlay near 2.5 nm and throughput around 330 wafers per hour, so tearing one down without factory metrology risks wrecking alignments that normal field service cannot easily recover.
Policy pressure is real on both sides, with service and parts licensing around China tightening since 2024 and fresh rare-earth export rules from China adding supply friction.
China is trying to build its own lithography machines through companies like SMEE and AMIES, but making them as good as ASML’s will take a long time.
ASML’s machines depend on extremely precise optics, motion stages, and control software, which took Europe decades to perfect. China is trying to copy or recreate all that from scratch, which is very difficult.
---
nationalinterest. org/blog/buzz/did-china-break-asml-lithography-machine-while-trying-to-reverse-engineer-bw-102025

19 Oct 2025

Whats stopping China to create their own photolithography machines to create their own chips?
Simply because Its ultra HARD. China has some of the brightest minds in the world working on it, its just really hard.
Refer to the quoted thread, claims some Chinese engineers took apart an ASML DUV (Deep Ultraviolet) lithography tool to study it, then could not re-assamble, and then asked ASML to fix it.
🔧 The 193nm immersion is unforgiving
An immersion DUV scanner runs 193nm light through a thin water layer and scans wafers on dual‑stage mechanics to keep overlay tight across 300mm wafers. That whole stack depends on factory procedures, internal references, and closed‑loop tuning of stages, optics, and sensors. ASML’s public product notes on immersion and TWINSCAN stages show how much precision is baked into the platform, including metrology frames that tie projection optics and sensors to a single reference point.
Pulling a tool apart risks particle hits on ZEISS projection optics, interferometer offsets, and loss of those references, and putting it back requires vendor procedures and software keys that sit behind service licensing.
The closest thing to an ASML rival are the Japanese companies Canon and Nikon, but they have pretty much conceded the cutting edge high end part of the field to ASML.
🏭 China’s plan B, stretch DUV and stand up domestic tools
SMIC, the Chinese foundry company is trialing a domestic immersion DUV from Yuliangsheng that targets 28nm and aims at 7nm via multi-patterning. Reporting pegs broader fab use around 2027, with performance closer to older ASML gear, so tuning and yield lift will take time.
China could catch up eventually. But EUV technology quite literally took billions of dollars of direct financial assistance from the US and Dutch government to complete. You can use Japan as an example. They were competing with the Dutch to make EUV in the 2000s. It ultimately failed as they couldn't commit sufficient consistent funding without the US. And Japan was the world leader in photolithography at the time.
EUV (Extreme Ultraviolet), as far as the actual wavelength of light goes, is pretty damn close to the physical limits of photolithography. We'll get incremental improvements but we're not likely to see anything like the shift from DUV to EUV again. But then again, who knows. When we first investigated EUV for photolithography in the 80's we didn't think it would be possible.
🚫 The export rules that drive this behavior
The Netherlands revoked licenses covering shipments of NXT:2050i and NXT:2100i to China from 1‑Jan‑2024.
In Sep‑2024, The Netherlands tightened things again so NXT:1970i and NXT:1980i shipments need Dutch licenses too, with NXT:2000i and newer already under Dutch control.
Even Servicing is also gated, since spare parts and software updates for certain China tools require a Dutch license


118
402
2,719
387,363
9 Oct 2025
The paper now available @iLabAfrica and @MicrosoftAfrica centres
The mission to redefine AI's future continues. The commitment is unwavering, whether the ecosystem is ready or not.
#AI #AGI #KenyaTech #Innovation
9 Oct 2025

The architecture to break AI's computational barrier is here. My paper is now at @iLabAfrica & @MSResearchAfrica.
I'm still seeking a research home to build the 100x cheaper AI future.The build and the commitment continues.
#DeepLearning #AIResearch #ComputationalEfficiency
5
91
9 Oct 2025
The architecture to break AI's computational barrier is here. My paper is now at @iLabAfrica & @MSResearchAfrica.
I'm still seeking a research home to build the 100x cheaper AI future.The build and the commitment continues.
#DeepLearning #AIResearch #ComputationalEfficiency
16 Sep 2025
Just wrapped the first draft of my whitepaper, "The Cortical Language Model" — exploring predictive processing, sparse coding, and neocortex-inspired AI. A step toward efficient, grounded intelligence. The real grind starts now.#BuildingInPublic #AIResearch @JeffDean
@ilyasut
5
173
Allan Ebusuru | Ontopir retweeted

4 Oct 2025
i'm leaving Lovable at 16 y/o to build AGI.
the bottleneck isn't smarter models, it's the tools and context around them.
more soon.

612
100
4,602
3,200,350
4 Oct 2025
While Silicon Valley scales compute, we're scaling intelligence.
The Cortical Language Model represents an architectural evolution—not incremental improvement.
10-100x efficiency gains through sparse, modular design.
Read the vision experbrain.org
#AI @iLabAfrica
1
4
75
Allan Ebusuru | Ontopir retweeted
3 Oct 2025
This is a solid blog breaking down how mixture-of-experts (MoE) language models can actually be served cheaply if their design is matched to hardware limits.
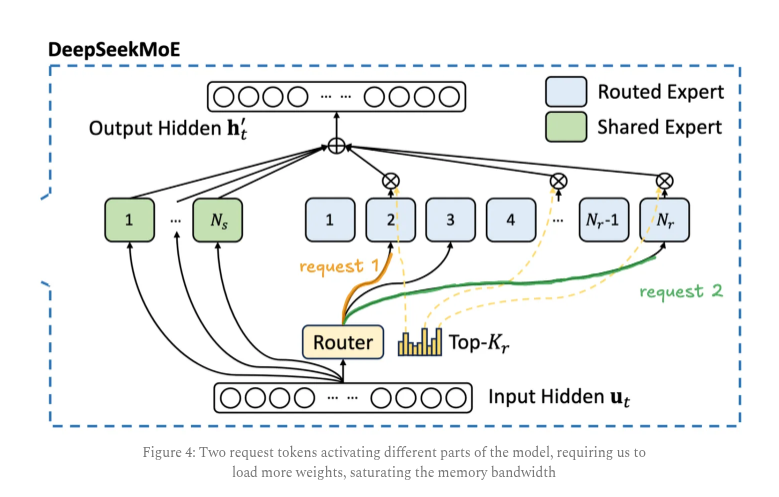
MoE models only activate a few experts per token, which saves compute but causes heavy memory and communication use.
With small batches it looks fine, but as batch size grows more experts get touched and the system loads more of the model each step.
This makes decoding tokens a memory bandwidth problem and increases key value cache storage because many sequences run at once.
The solution is to spread experts across many GPUs in a setup called expert parallelism, and route each token to its top experts plus a shared expert.
DeepSeek routing usually picks 8 experts from 256 per layer across 58 layers, which is why communication becomes the main cost.
To control this, attention stays data parallel so the cache sits on one GPU, and only small activation vectors get moved across devices.
Two microbatches run at once so that while one computes, the other handles communication, hiding most delays.
Because some experts get used more than others, hot experts are duplicated and traffic is balanced to avoid bottlenecks.
Routing also favors experts on the same node to reduce slow inter-node transfers.
Multi head latent attention compresses the key value cache to 70KB per token instead of hundreds of KB, which lowers memory traffic.
This lets batch sizes grow larger, especially for long contexts.
They also reorder the attention math so that projections tied to context length are folded away, cutting wasted compute.
The economics are then simple: GPUs cost money per hour, tokens per hour are the output, and price per token is cost divided by output.
Throughput grows with bigger batch size, more GPUs, and faster interconnects, but falls when service requires high tokens per second per user.
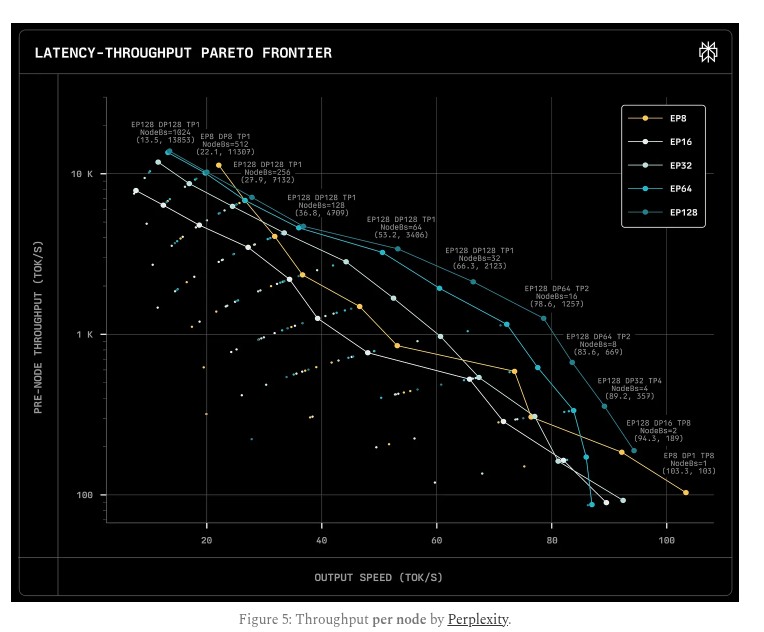
Tests on different clusters show that more GPUs in an expert parallel group make each GPU more efficient by keeping experts busier.
Interconnect speed is key, with NVLink racks scaling well, while InfiniBand between DGX nodes becomes the bottleneck.
If services guarantee 20 tokens per second per user, then batch size must shrink and cost per token rises.
That is why chat settings run fast but waste capacity, while synthetic data jobs should run with huge batches and low tokens per second per user.
A 72-GPU cluster at batch 64 can produce billions of tokens per day at about $0.40 per 1M tokens.
Prefill is different, it is compute heavy and grows with input length, so providers split prefill from decode and use caching so prefixes are not recomputed.
Good caching achieves about 56.3% hits, reducing cost and freeing GPUs for decoding.
Global demand is still low compared to capacity, with only about 1B output tokens per day on aggregators, far below what even one big rack can handle.
The main lesson is that MoE models become cheap when run with large batches, compressed caches, smart routing, split prefill and decode, and fast interconnects.
This allows providers to price fast chat higher while offering slow bulk generation much cheaper, which is useful for synthetic data and fine tuning.
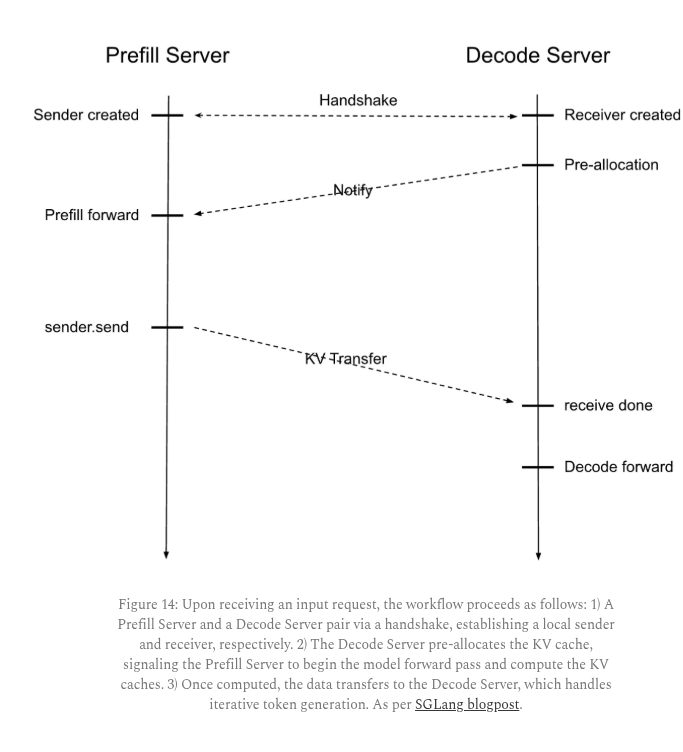
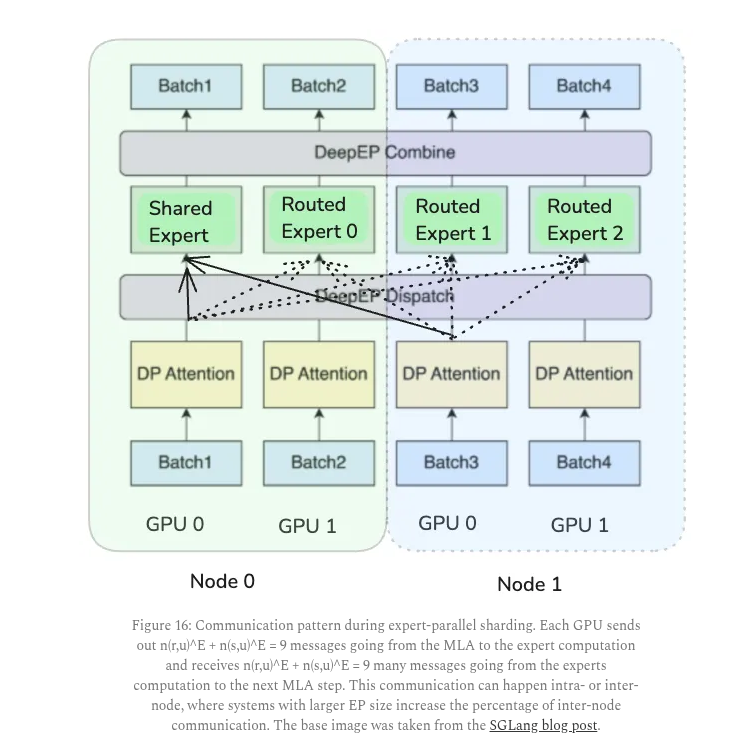
8
72
555
38,067
28 Sep 2025
The transformer paradigm has reached its limit. Tomorrow, I'm taking the alternative to the source. I'm submitting my paper on the Cortical Language Model (CLM) to @MSFTResearch Africa. It's time to build the future of efficient, equitable AI. @MicrosoftAfrica
4
72
24 Sep 2025
Everything in the universe is a wrapper
24 Sep 2025

Modern tech is crazy.
- cursor is a wrapper over vscode.
- vscode is a wrapper over electron.
- electron is a wrapper over chromium.
- chromium is a wrapper over c
- c is a wrapper over assembly.
- assembly is a wrapper over 1s and 0s.
4
66
24 Sep 2025
CLM comes from hours of reading Friston Hawkins deep learning papers. Why do current models treat all tokens the same? Why not dynamic expert modules — as seen in cortical columns? I believe Kenya can contribute foundational AI, not just apps. @iLabAfrica @Nailab @RobertAlai
5
73
24 Sep 2025
Attention economy is big—but perception without structure collapses. CLM is my attempt to design structure. Policy education tech must align.Or are we still thinking about fintech apps?🤔 @PhilipThigo @AlyKhanSatchu @MorrisKiruga #AI #KenyanTech
1
6
92
23 Sep 2025
Scaling LLMs to attain AGI


1
5
83
20 Sep 2025
Just got off a call debating catastrophic forgetting with some brilliant minds — interesting how our CLM approach rhymes with what @drjimfan and others at Nvidia have been hinting at.
Still feels like memory is the under-discussed bottleneck in AGI.
1
5
103
18 Sep 2025
I will die before I quit on this📍
16 Sep 2025
Just wrapped the first draft of my whitepaper, "The Cortical Language Model" — exploring predictive processing, sparse coding, and neocortex-inspired AI. A step toward efficient, grounded intelligence. The real grind starts now.#BuildingInPublic #AIResearch @JeffDean
@ilyasut
4
123