
Tech Lead | Software Engineer | Open source
Joined November 2012
- Tweets 6,875
- Following 2,763
- Followers 2,812
- Likes 35,968
246 Photos and videos











Alpha retweeted

Mar 15
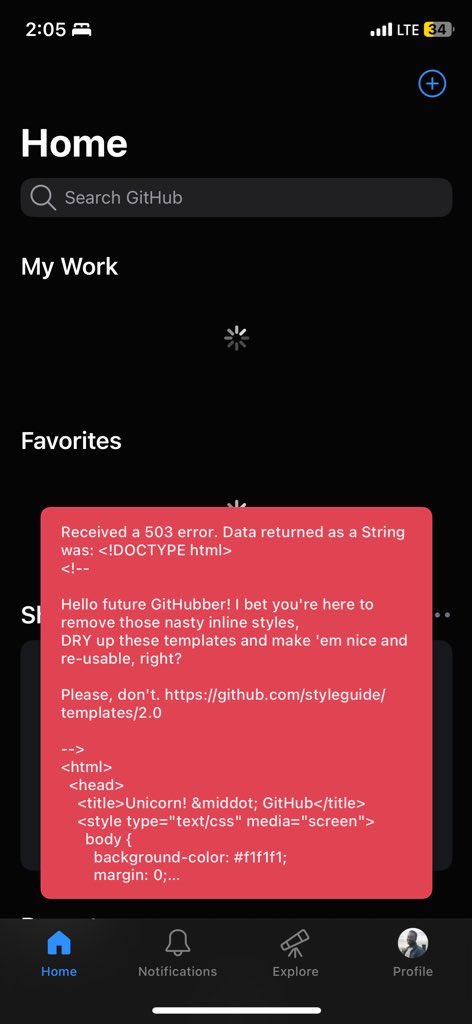
Kuanzia @greyfinance hadi @HurupayApp na nyinginezo...
Shida wengi kama @ShukuruAmos wana angaika na challenge ya kurecharge kutoka madafu kwenda usd...
Basi hii nadhani wanunuzi wa mtandaoni wanaotamani kulipia USD to USD watest
Nimetest yangu naona haina access...

4
2
6
1,197

27 Dec 2025
This is a gem!
26 Dec 2025

In the next version of Bun
Bun.Archive lets you create & extract tar archives

ALT import { Archive } from "bun"; const tarball = Archive.from({ "package.json": '{ "name": "hi" }' }); await tarball.write("pkg.tar.gz", "gzip"); await tarball.extract("dir");
3
212
Alpha retweeted

27 Dec 2025
Shout out to @AlphaOlomi my nigga tested and downloaded the @brave browser over 30 times to make sure we have a proper CI/CD pipeline with tests, in a couple of hours working on weekend 🙌🏿🙏🏿
27 Dec 2025

1
6
333
27 Dec 2025
27 Dec 2025

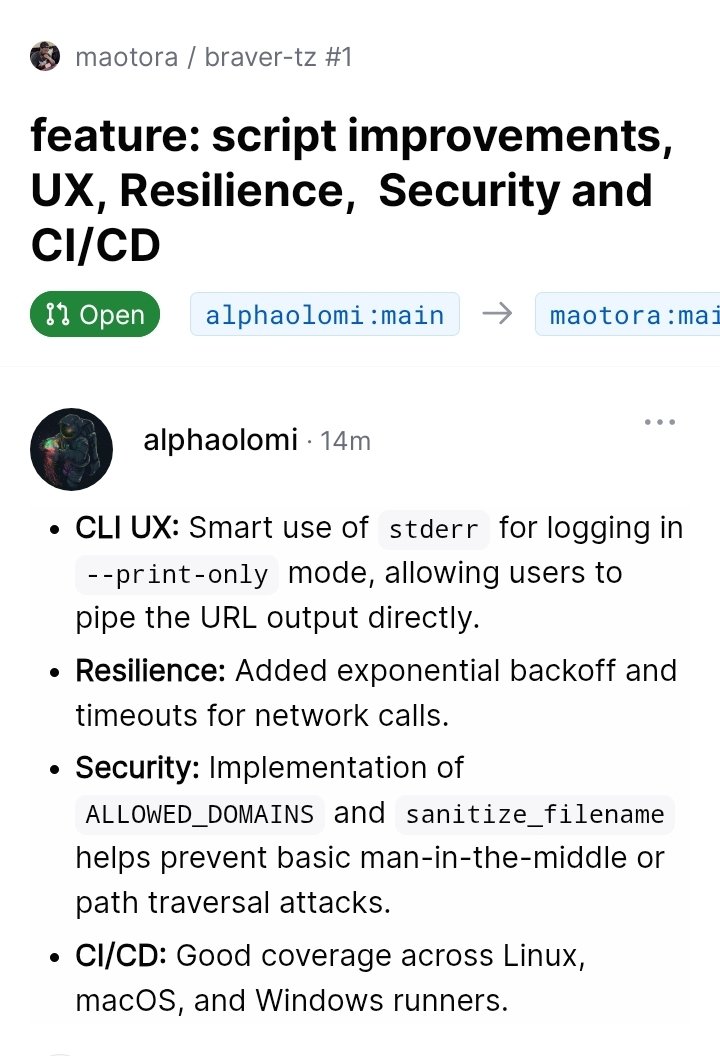
Introducing braver-tz – the game-changing script that solves our Brave access woes! 🚀
It grabs the latest stable Brave Browser directly from GitHub releases, bypassing blocks entirely. Works on ANY OS (macOS, Windows, Linux) and architecture!
github.com/maotora/braver-tz
Try it! 🫶
2
4
508

12 Dec 2025
.

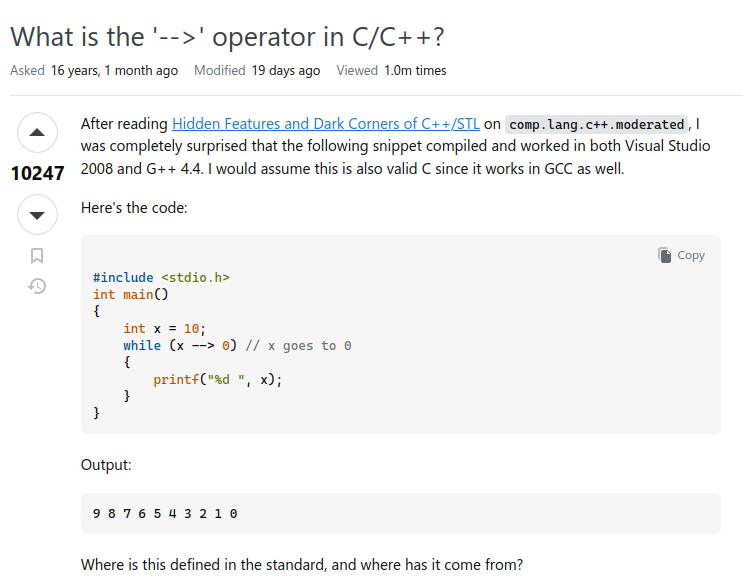
Researchers have found two new vulnerabilities in React Server Components while attempting to exploit the patches last week.
These are new issues, separate from the critical CVE last week. The patch for React2Shell remains effective for the Remote Code Execution exploit.
1
155
Alpha retweeted

9 Dec 2025
Blame CloudFlare for Website Issues
The Cloudflare Error Page Generator (github.com/donlon/cloudflare…) is an open-source tool for creating highly customizable error pages in the style of Cloudflare.
It perfectly mimics Cloudflare’s famous error page designs (such as the 5xx internal server error pages) and can be embedded directly into your website. You can easily generate static HTML files to replace default error pages, allowing you to quickly shift the blame to CloudFlare whenever your site runs into problems.

76
1,091
7,944
1,620,210
Alpha retweeted

28 Nov 2025
⚡ In Laravel, you can write global scopes that can be reused amongst models.
This scope will append an ‘active = 1’ where clause to every product query:
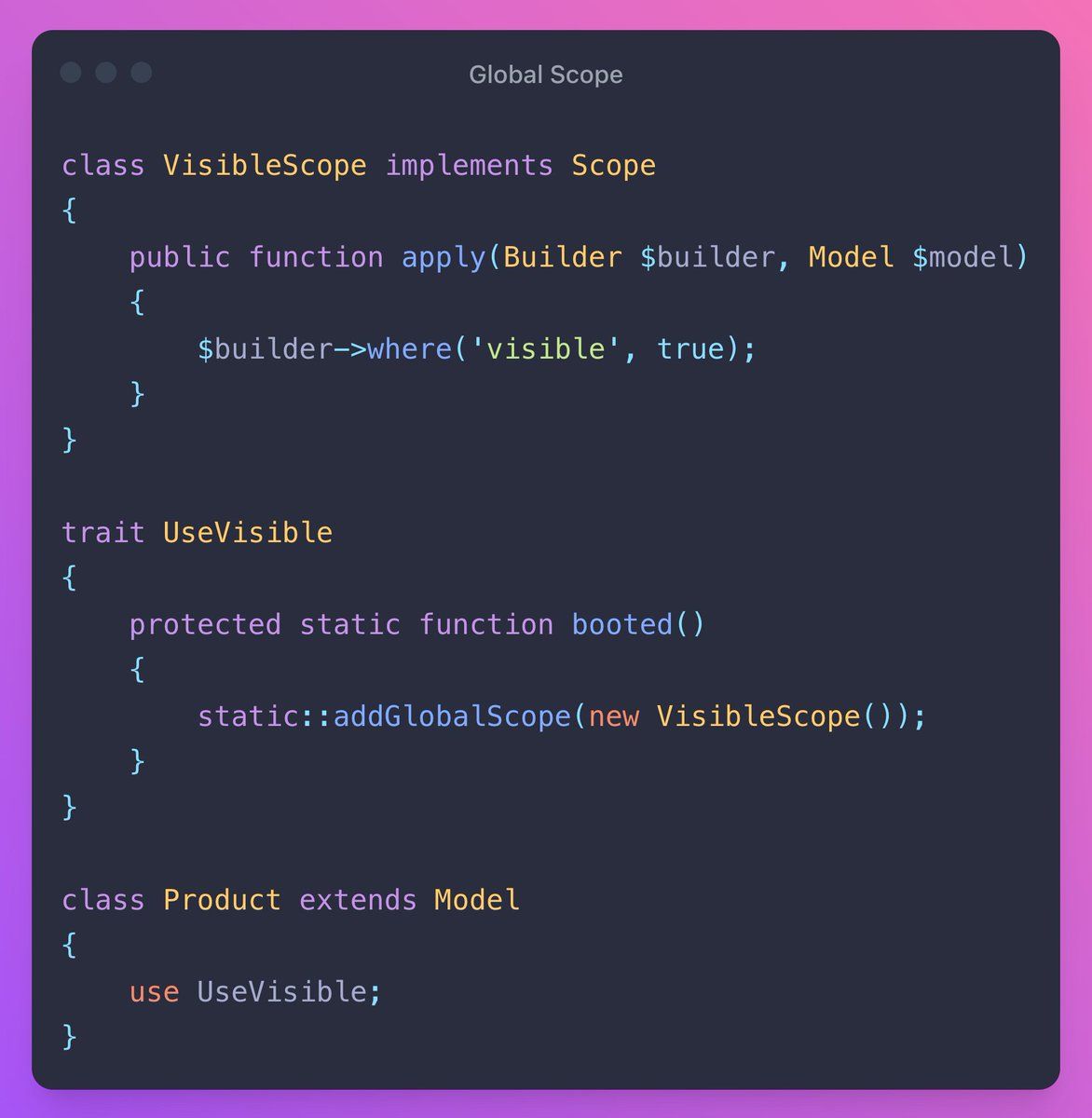
5
14
143
6,611
Alpha retweeted

26 Nov 2025
> be anthropic engineer
> realize long-running agents still have goldfish memory
> every new context window = new intern who forgot everything from yesterday
> project goes from “build a clone of ChatGPT” to “why is half the frontend missing again?”
> agents try to one-shot entire apps
> run out of context mid-feature
> next session wakes up like “boss… who touched the router folder? why is the server on fire?”
> other times claude walks in
> sees 3 buttons rendered
> declares the whole project complete
> packs up its laptop
> goes home
> humans don’t work like this
> engineers leave breadcrumbs
> notes, git commits, tests, todo lists
> “here’s what I did, here’s what’s next, don’t break the login page again please”
> so anthropic builds a harness based on that
> two-agent setup: initializer agent, coding agent
> initializer agent = the senior dev on day one
> sets up:
> – _init.sh
> – claude-progress.txt
> – feature_list.json (200 features, all marked failing)
> – the first git commit
> basically: “here’s the blueprint, don’t get cute”
> coding agent = the worker bee
> every session:
> – read the progress
> – read the git log
> – read the feature list
> – pick ONE feature
> – implement it
> – test it end-to-end as an actual user
> – commit code
> – leave notes
> – do NOT break anything, or revert yourself
> incremental progress > chaos
> and forcing the agent to act like a real engineer = night and day difference
> testing was the big “aha”
> claude kept marking features done that absolutely were not done
> (“unit tests pass” ≠ “the app works”)
> give it browser automation puppeteer
> claude suddenly starts catching bugs it introduced 5 minutes ago
> screenshots, clicks, actual user flows
> end-to-end or bust
> limitations still there
> puppeteer can’t show alert modals
> claude can’t see everything
> vision quirks remain
> but it’s way closer to real QA than “lol curl localhost:3000”
> typical session now looks like:
> “pwd”
> read progress
> read features
> read git log
> start server
> sanity test
> fix broken stuff
> choose next feature
> implement
> test
> commit
> leave breadcrumbs
> repeat
> four classic failure modes solved with structure:
> – agent declaring victory too early → feature list
> – messy environment → git progress logs
> – premature ‘passes’ → real testing
> – agent forgot how to run app → _init.sh
> does it solve everything? no
> still open questions:
> single agent vs multi-agent division of labor
> maybe future = dedicated QA agent, cleanup agent, test writer agent
> maybe research workflows get similar scaffolding
> maybe finance models get their own version
> but the core insight stands:
> long-running agents don’t fail because they’re dumb
> they fail because we throw them into multi-session hell
> without giving them the engineering rituals humans rely on
> give them structure, tools, tests, logs, diffs
> they stop acting like goldfish
> and start acting like teammates
26 Nov 2025

New on the Anthropic Engineering Blog: Long-running AI agents still face challenges working across many context windows.
We looked to human engineers for inspiration in creating a more effective agent harness. anthropic.com/engineering/ef…
71
168
3,005
542,341


I highly recommend Better Auth
I used it personally on many of my personal projects
It really removes a lot of redundant processes of setting up authentication, and goes straight to building things
A frontend utility is also a plus!


22
37
1,110
78,944
22 Nov 2025
AFAIK best case,
22 Nov 2025

Some big applications are using it already to save money with LLMs. However, IDK if it’s going to sticky as a default format or anything!
2
222
22 Nov 2025
Creasingggggg
21 Nov 2025

Dear msemaji...is the pressure increasing or decreasing?
184
Alpha retweeted

20 Nov 2025
Hey, PHP haters.
It's not dead. Version 8.5 is out, now.
I love the new pipe operator (|>), the URI extension, and the upgrades to constants.
But that's not it, there's a lot to unpack here. I wrote about it on my blog:

31
47
446
26,741

Alpha retweeted

18 Nov 2025
Gemini 3 Pro is now available in Cursor!
254
394
8,471
681,765
Alpha retweeted

Important for Claude Code users!
16 Nov 2025

Claude Code users (especially Laravel/Symfony): you REALLY want to re-install Claude
Latest Claude versions will load your `.env` (including secrets!) into Claude Code. Claude then runs your tests with local config instead of testing config!
I found this because my Laravel tests in Claude Code failed with CSRF errors (419), but pass in my terminal.
That is caused by @bunjavascript (NodeJS alternative).
Claude Code recently moved from "install via NPM and run via Node" to "download a self-contained binary". Except that binary is running Bun under the hood.
And Bun automatically loads `.env` files (wtf!)
Which means that your Laravel local config (.env) gets loaded, forcing tests to run in `local` environment instead of `testing`, with your entire local config (including tokens & such). If your local DB gets wiped because of Claude, you now know why.
You really want to move back to the `npm` version of Claude Code:
rm ~/.local/bin/claude
npm install -g @anthropic-ai/claude-code
1
1
27
10,495
Alpha retweeted

18 Nov 2025
When you fuck the whole internet so hard, that even your CSS on your status page don't work anymore.
Cloudflare DOWN!

60
244
2,888
477,861

