
AI researcher: Alignment & Interpretability
Joined December 2025
- Tweets 210
- Following 183
- Followers 429
- Likes 360
61 Photos and videos










Pinned Tweet

11h
VLMs Systematically Fake Visual Understanding
Even when VLMs appear to be good at visual understanding, most of their answers are not actually grounded in the image (hallucinated!).
We identify two types of hallucinations that appear in up to 98% of answers that seem to demonstrate visual understanding.
First, textual biases. The model answers using language patterns, information in the question, and knowledge learned during training, without engaging its visual representations.
Second, spurious images. The model constructs false visual content inside its internal representation and then answers as if this imagined content were grounded in the real image.
In both cases, the answers may still be correct, but they are not grounded in the visual input at all!!
3
3
18
2,509
Amit LeVi retweeted

Check out our new paper! VLMs are hallucinating much more than most people think....
11h

VLMs Systematically Fake Visual Understanding
Even when VLMs appear to be good at visual understanding, most of their answers are not actually grounded in the image (hallucinated!).
We identify two types of hallucinations that appear in up to 98% of answers that seem to demonstrate visual understanding.
First, textual biases. The model answers using language patterns, information in the question, and knowledge learned during training, without engaging its visual representations.
Second, spurious images. The model constructs false visual content inside its internal representation and then answers as if this imagined content were grounded in the real image.
In both cases, the answers may still be correct, but they are not grounded in the visual input at all!!
1
2
3
209
11h
VLMs Systematically Fake Visual Understanding
Even when VLMs appear to be good at visual understanding, most of their answers are not actually grounded in the image (hallucinated!).
We identify two types of hallucinations that appear in up to 98% of answers that seem to demonstrate visual understanding.
First, textual biases. The model answers using language patterns, information in the question, and knowledge learned during training, without engaging its visual representations.
Second, spurious images. The model constructs false visual content inside its internal representation and then answers as if this imagined content were grounded in the real image.
In both cases, the answers may still be correct, but they are not grounded in the visual input at all!!
3
3
18
2,509
11h
The paper: arxiv.org/pdf/2606.13870
Will be presented at the mech interp workshop, Icml 2026
1
3
177
11h
Our results show that benchmark accuracy can significantly overestimate true visual understanding.
A model can give the correct answer while ignoring the image entirely.
As a result, answer correctness alone is not a reliable measure of visual understanding.
137
11h
In the analysis, we compared model responses with and without images and trained a simple linear classifier on the models’ internal activations. We saw that these hallucinations are directly reflected in the internal representations of the model, reaching up to 98% classification accuracy.
196
Jun 11
The 3-day paper is one of them 🫨
Jun 11
I will be attending several workshops at #ICML and presenting 11 posters, mostly in AI in the Wild and Mechanistic Interpretability.
Once the main conference rush is over, I’d love to connect during the workshop days with researchers, investors, and industry practitioners interested in:
• Interpretability
• Alignment
• AI Agents
• Reasoning
• AI Security
• Inference-Time Optimization
• Training Optimization
Feel free to DM me. See you in Seoul! 😊
2
16
2,756
Jun 11
Also, you’re welcome to debate me in person.
I’m currently developing a powerful agentic research system to speed up the PoC research pipeline.
I think this will also lead to much better and more comprehensive research.
Some people here think the opposite.
I think AI slop is an opportunity to set a new bar for paper quality standards(I support lower acceptance rates.).
1
2
211
Jun 11
The paper is about introspection analysis of LLMs. We introduce a method for identifying internal reasoning features and present a large set of experiments and findings.
The paper has not been submitted to NeurIPS …
And may never be published (moving labs, IP issues, and all that bullshit).
If you’re curious, come find me at the Failure Modes of AI Agents workshop and ask about it🫡
1
283
Jun 11
I will be attending several workshops at #ICML and presenting 11 posters, mostly in AI in the Wild and Mechanistic Interpretability.
Once the main conference rush is over, I’d love to connect during the workshop days with researchers, investors, and industry practitioners interested in:
• Interpretability
• Alignment
• AI Agents
• Reasoning
• AI Security
• Inference-Time Optimization
• Training Optimization
Feel free to DM me. See you in Seoul! 😊
3
1
56
6,395
Jun 10
You can’t CoT the whole internet! what is going on with Claude Code? Its too slow and expensive
1
284
Amit LeVi retweeted

May 18
Excited that our paper on Actionable Interpretability got accepted to ICML!
And just in time -- we also heard that our Actionable Interpretability workshop will be happening again, in COLM!
See you in Korea 🇰🇷 and SF🌉
[Arxiv paper link in the comment]
Feb 18

Our ICML 2025 workshop on Actionable Interpretability drew massive interest. But the same questions kept coming up: What does "actionable" mean? Is it achievable? How?
We're ready to answer.
🧵

4
20
164
15,596
May 10
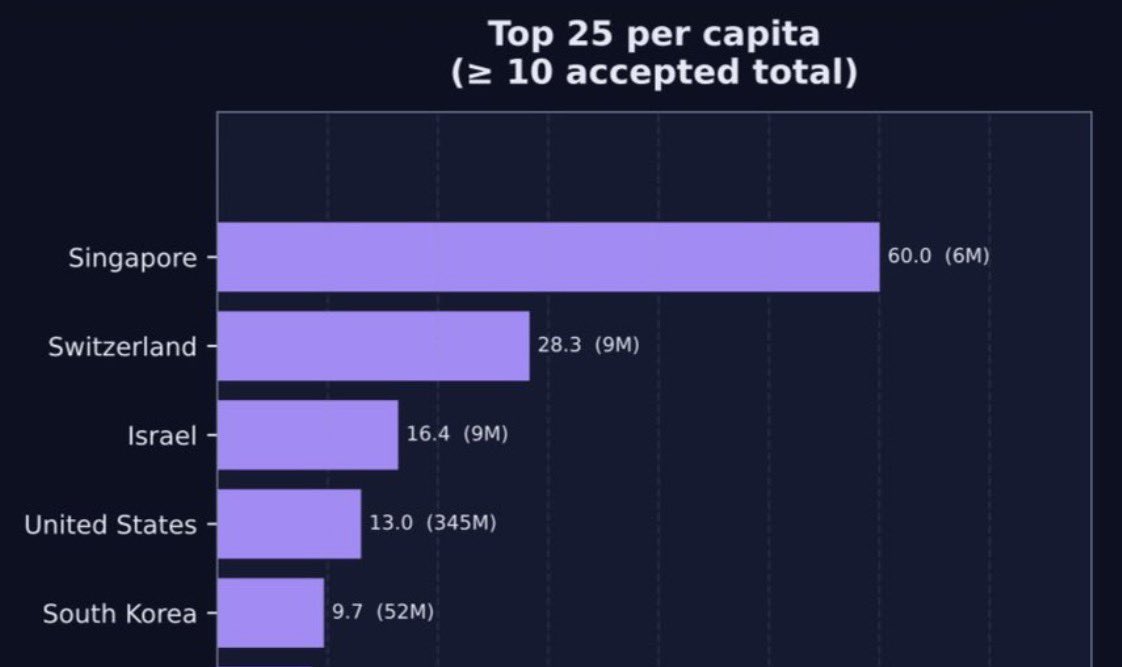
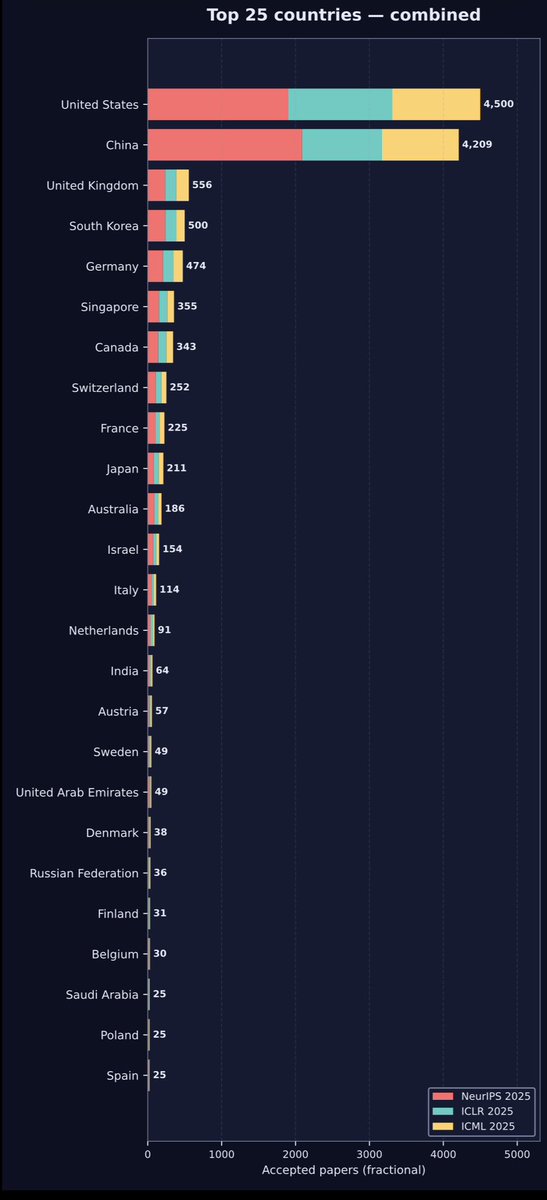
I liked it, so I extended the analysis to NeurIPS, ICLR, and ICML 2025
including acceptance rates for ICLR, accepted papers per capita, and additional analyses.
The calculation uses 1/K credit per paper author, where K is the number of authors on the paper.
8
5
34
7,752
May 10
4
745
May 10
1
20
14,430
May 10
Full analysis
May 10
I liked it, so I extended the analysis to NeurIPS, ICLR, and ICML 2025
including acceptance rates for ICLR, accepted papers per capita, and additional analyses.
The calculation uses 1/K credit per paper author, where K is the number of authors on the paper.
1
708
May 10
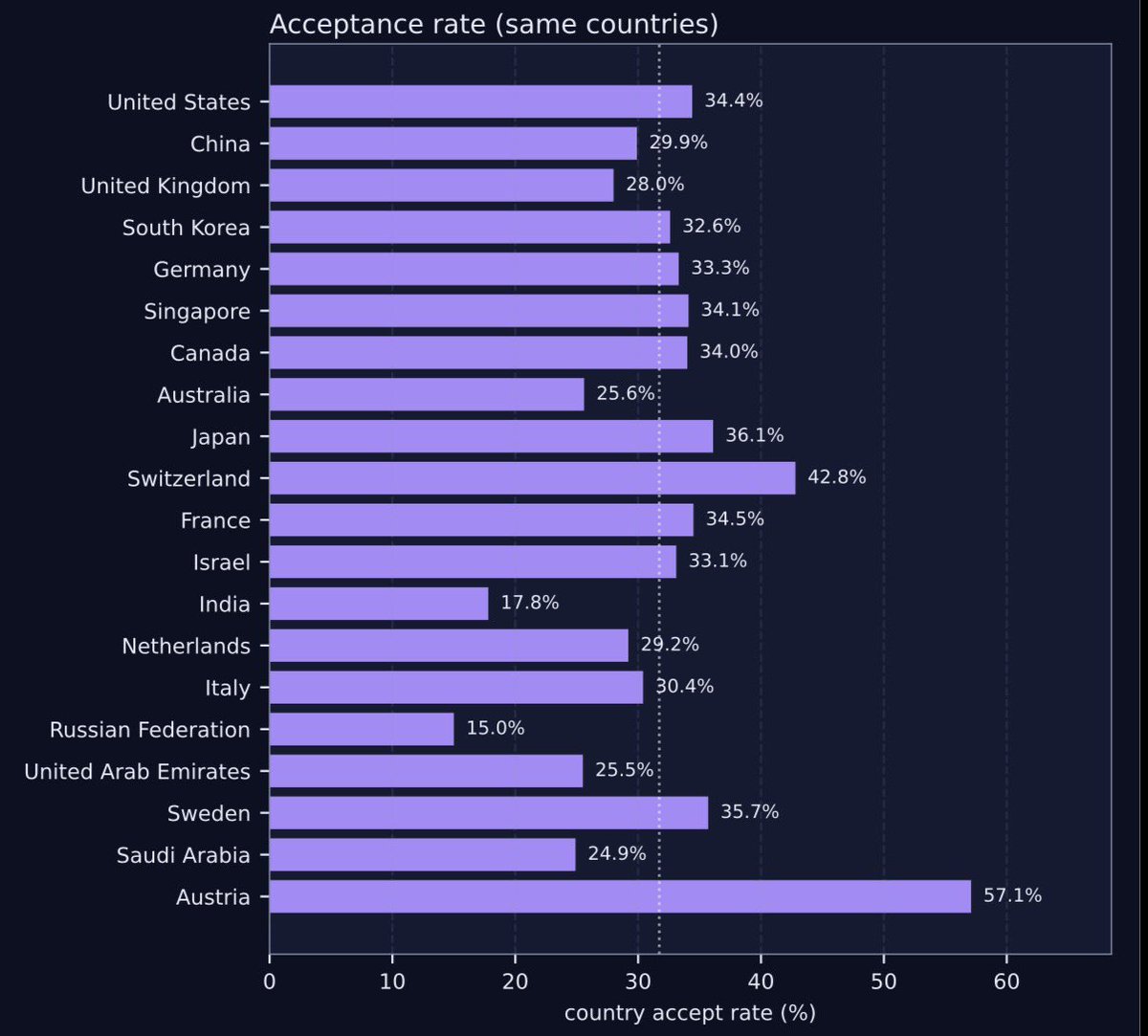
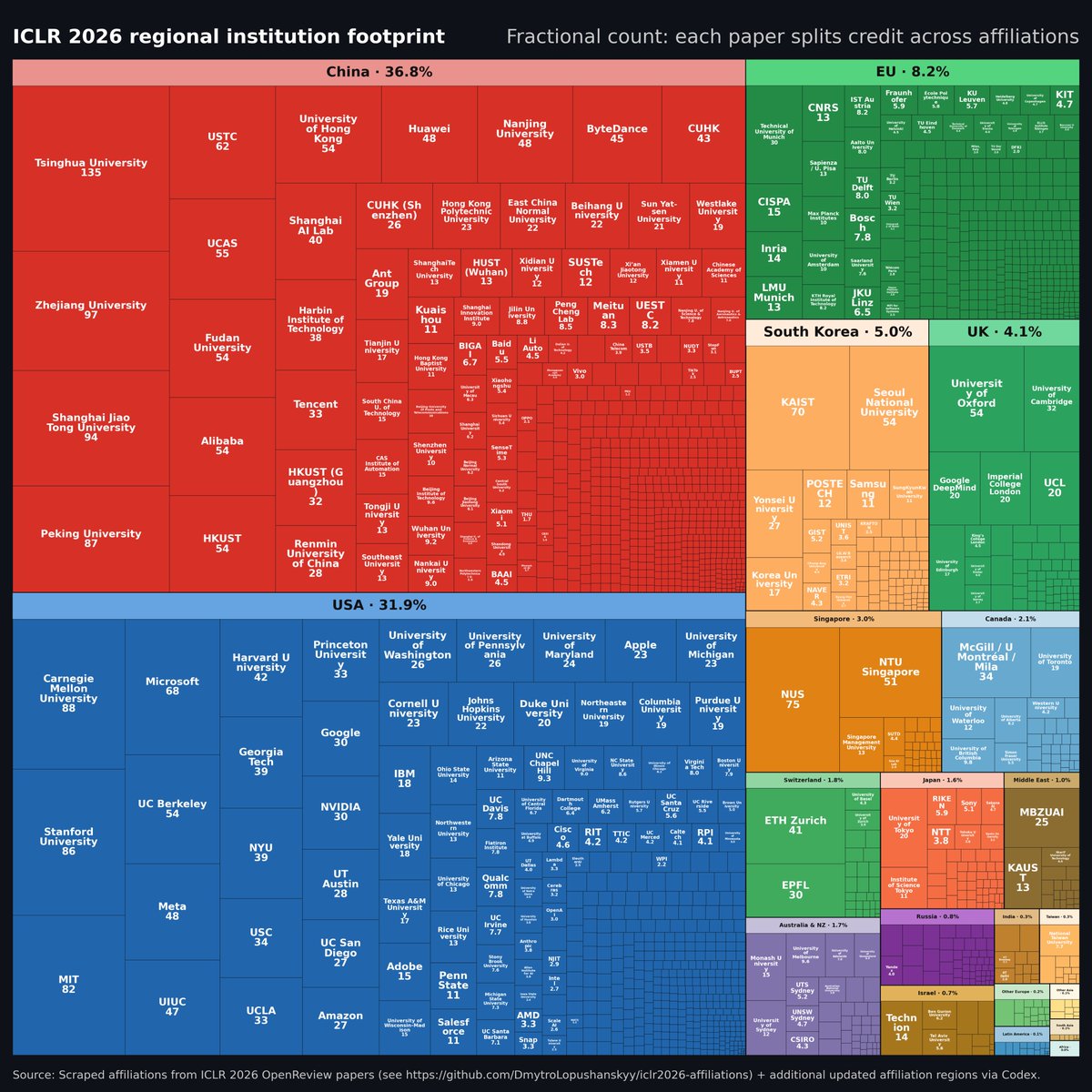
I’m curious how many submissions came from each country

Better version without arbitrary institution cutoff, some data cleaning and splitting contribution of each paper among institutions. China USA dominant ofc, but looks a bit different, doesn't it?
2
8
4,472
