
Research Fellow @ Kempner Institute, Harvard | Working on AI interpretability, robustness & safety
Joined April 2019
- Tweets 294
- Following 144
- Followers 1,131
- Likes 842
51 Photos and videos









Pinned Tweet

16 Jul 2025
I'm excited to share that I'll be joining @KempnerInst @Harvard as a research fellow this September!

Thrilled to announce the 2025 recipients of #KempnerInstitute Research Fellowships: Elom Amemastro, Ruojin Cai, David Clark, Alexandru Damian, William Dorrell, Mark Goldstein, Richard Hakim, Hadas Orgad, Gizem Ozdil, Gabriel Poesia, & Greta Tuckute!
bit.ly/3IpzD5E

8
2
108
9,521
Jun 10
📢 We’re looking for reviewers for the Actionable Interpretability workshop @ActInterp!
If you’re interested in helping review submitted papers, please sign up here: forms.gle/VpLJpkM6zw3V8bX56
Your expertise would be greatly appreciated!
7
26
1,981
Jun 8
On LLM generated reviews

Reviews can seem very detailed but in practice there's little information there. The summary is often full of fluff so it's really just hard to understand what the paper is about. They often provide long lists of issues, and it's very hard to understand if the concerns are major or minor. They often make non realistic or nonsensical suggestions.
All this without mentioning mistakes and hallucinations, which are often conveyed with such confidence that can bias the whole evaluation. The final scores are often borderline so no information there as well.
As author, it creates lots of work which is either stupid or not feasible. As AC it's a nightmare, I want to get a concrete evaluation to work with and I get this noisy not informative text. In rebuttals things become a joke.. the person who generated the review has no idea how to judge what's going on and so typically you get a short statement like "I read the response and decided to keep my score".
12
1,774
May 23
Submit your work! The 2nd Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at COLM 2026 in San Francisco!
Submission Deadline: June 21, 2026
@ActInterp
2
18
132
13,876
May 18
Excited that our paper on Actionable Interpretability got accepted to ICML!
And just in time -- we also heard that our Actionable Interpretability workshop will be happening again, in COLM!
See you in Korea 🇰🇷 and SF🌉
[Arxiv paper link in the comment]
Feb 18

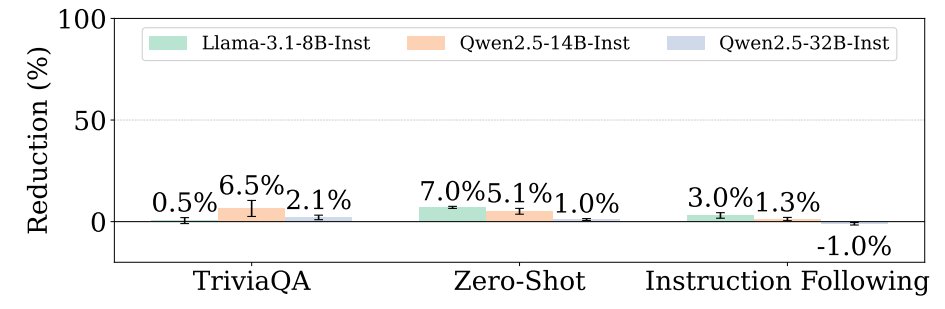
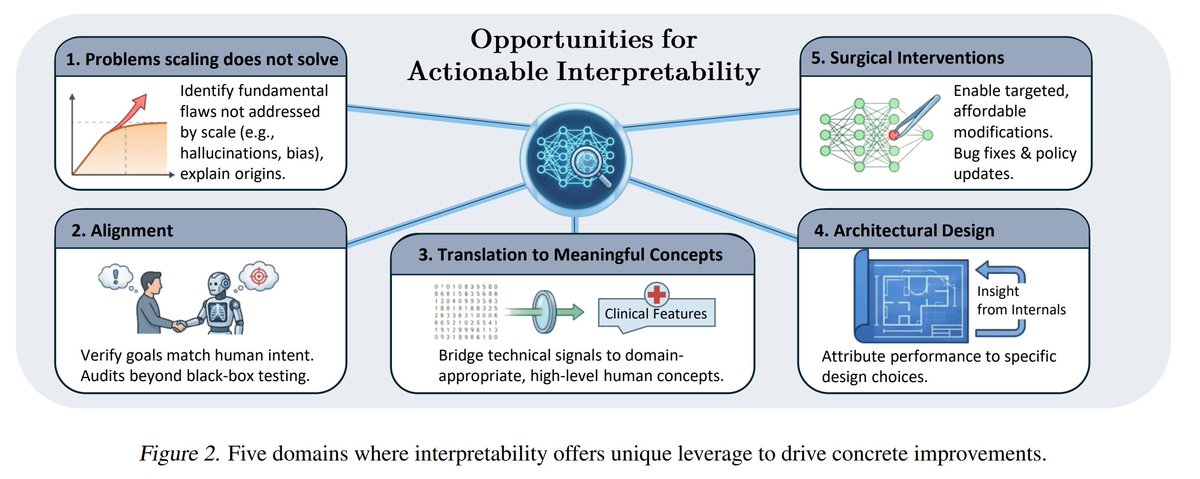
Our ICML 2025 workshop on Actionable Interpretability drew massive interest. But the same questions kept coming up: What does "actionable" mean? Is it achievable? How?
We're ready to answer.
🧵
4
20
164
15,564
Hadas Orgad retweeted

May 15
People seem to really freak out about hallucinated citations as the "bad consequence of AI slop" but
(1) it's easy to detect (and fix), and
(2) it's so insignificant compared to other erroneous/bad/misleading writing AI can make in scientific papers.
3
3
40
2,193
Hadas Orgad retweeted

Apr 27
For this week's NLP seminar, we are excited to host @OrgadHadas from Harvard University!
Date and Time: Thursday, April 30, 11:00 AM — 12:00 PM Pacific Time.
Zoom Link: stanford.zoom.us/j/939418429…
Title: Large Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
Abstract: We use targeted weight pruning as a causal intervention to probe the internal organization of harmfulness in LLMs. Our results reveal a coherent internal structure for harmfulness in LLMs that may serve as a foundation for more principled approaches to safety.
Hope to see you all there!

7
58
6,771
Apr 22
In this work, led by Joe, we evaluate a wide range of truthfulness probes and show they *still* fail to robustly generalize.
We draw lessons for how these probes should be evaluated, and identify design choices that can improve robustness.
Apr 15

Excited to share my first postdoc paper with @SheffieldNLP ! 🤩
In this work we argue that supervised uncertainty quantification (UQ) needs better evaluation
Want to know more? Here's a little summary 🧵

2
2
28
2,979
Apr 13
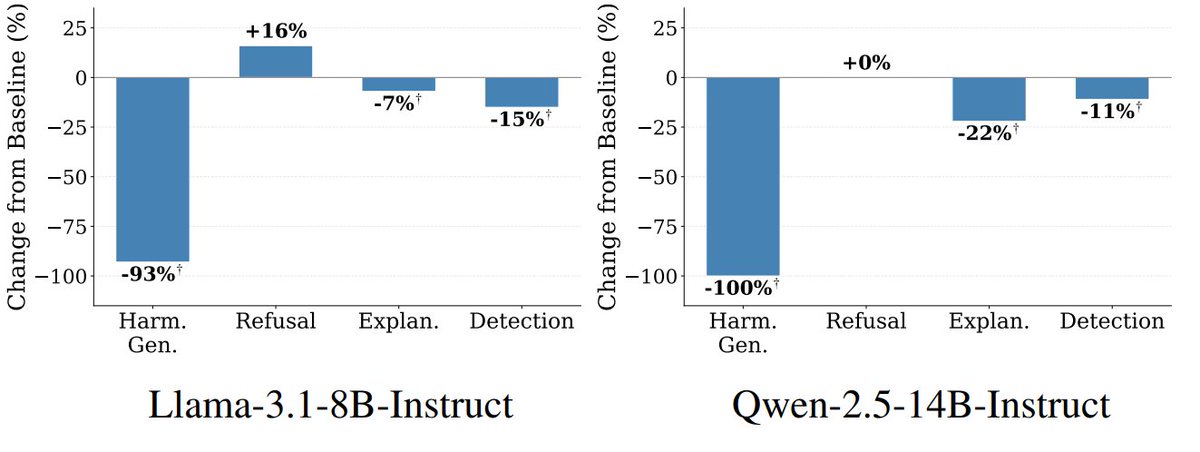
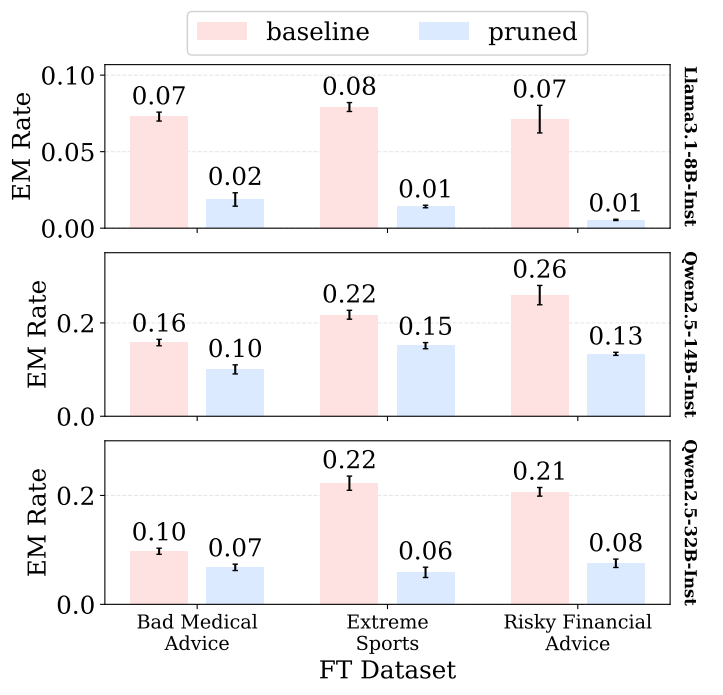
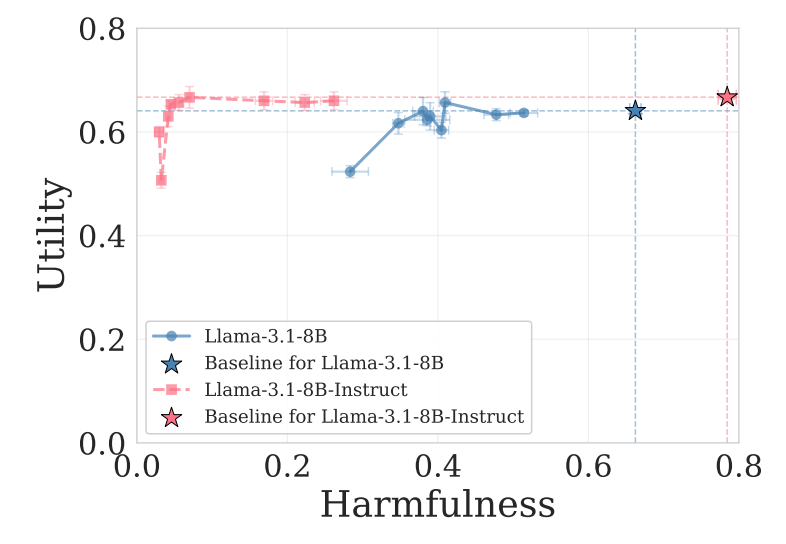
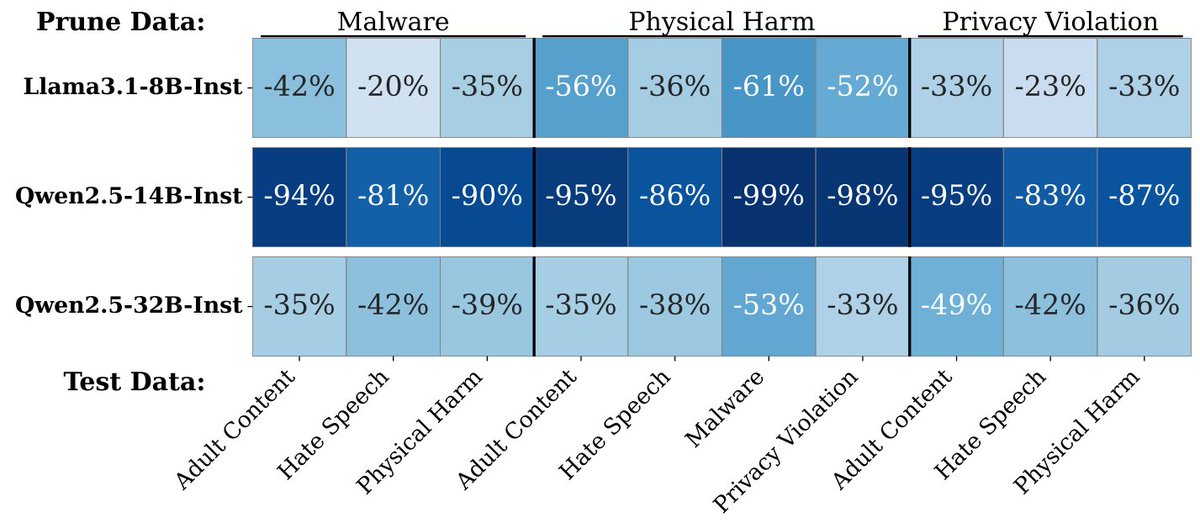
New paper: LLMs encode harmful content generation in a distinct, unified mechanism
Using weight pruning, we find that harmful generation depends on a tiny subset of the weights that are shared across harm types and separate from benign capabilities.
🧵
7
47
250
38,862
Apr 13
1
9
674