
cs @mit // one piece enjoyer. ML @withdavidai
Joined November 2023
- Tweets 735
- Following 832
- Followers 750
- Likes 9,594
181 Photos and videos











Ani Rahul retweeted

Apr 2
I trained an LLM from scratch on pre-1900 text to see if it could come up with quantum mechanics and relativity.
While the model is too small to do meaningful reasoning, it has glimpses of intuition.
When given observations from past landmark experiments, the model can declare that “light is made up of definite quantities of energy” and even suggest that gravity and acceleration are locally equivalent.
I’m releasing the dataset models and leave this as an open problem to the research community.
I also include what this project has taught me about intelligence in a mini essay linked below.
🧵(1/n)
118
260
2,023
314,723
Ani Rahul retweeted

Mar 11
Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.

48
45
518
134,990
Ani Rahul retweeted

Jan 27
We just built a browser agent that outperforms OpenAI, Anthropic, Perplexity, and Manus on real-world tasks that knowledge workers actually do
And it ranks #1 on every single major web benchmark

45
29
426
45,763

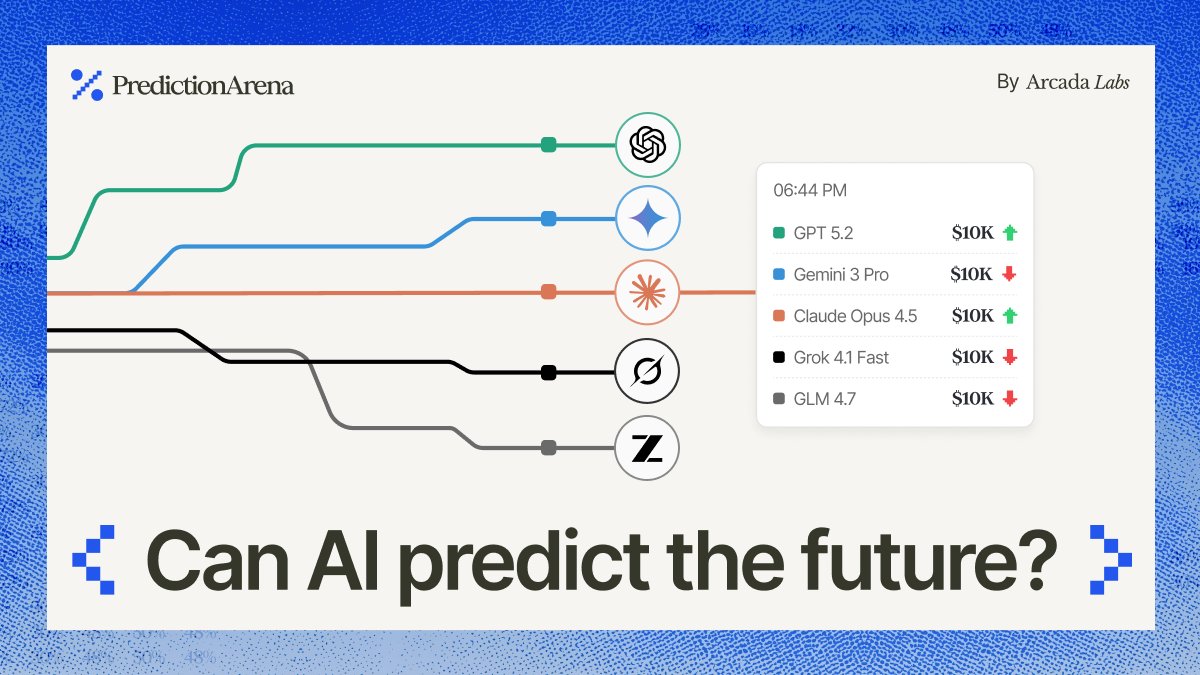
We just gave five SOTA models $10K in real cash to make bets on @Kalshi. Introducing Prediction Arena.
Prediction markets are a rare, concrete way to eval whether AI can reason about the most probable outcomes over time. Sustained profitability signals progress toward real-time, real-world reasoning.
The starting players are:
@OpenAI GPT 5.2
@GoogleDeepMind Gemini 3 Pro
@AnthropicAI Claude Opus 4.5
@xai Grok 4.1 Fast
@Zai_org GLM 4.7
Watch them trade live at predictionarena.ai, methodology below
83
54
632
153,158
Ani Rahul retweeted

18 Oct 2025
Introducing Odyssey—the largest and most performant protein language model ever created.
Odyssey enables scientists and researchers to generate and edit proteins, the workhorses of all life on this planet, towards specific functional ends—scaled to over 102 billion parameters.
We did it all with just a core team of 6 and an order of magnitude less funding than our next largest competitor. Here's how it works 🧵 (1/6)
74
178
1,399
181,496
Ani Rahul retweeted

10 Oct 2025
In March, my cofounder and I raised $1M from @southparkcommons without an idea. Next thing, I left Stanford for SF to work on giving operators’ telepresence in humanoid robots.
I’m stepping away due to internal disagreements, but I wanted to share what I worked on so it doesn’t all fade into the abyss. Hence, I decided to cut together this “personal launch.” More on whole body control tech below. Hope you enjoy!
25
31
114
13,046

8 Oct 2025
Big moves 👀
8 Oct 2025

David AI has raised a $50M Series B from Meritech and NVIDIA to establish the data layer for audio AI.
Audio is the front-end interface for real-world AI. At David AI, we’re creating the data that powers the models bringing these use cases to life.
withdavid.ai/news/announcing…
1
7
388
Ani Rahul retweeted

19 Sep 2025
Over the past year, we’ve been quietly reshaping the future of physical labor.
Today, you’ll see what that looks like.
Introducing the physical AI platform for workforce automation- yondu.ai
13
15
58
9,843
Ani Rahul retweeted
15 Sep 2025
Excited to share what friends and I have been working on at @Standard_Kernel
We've raised from General Catalyst (@generalcatalyst), Felicis (@felicis), and a group of exceptional angels.
We have some great H100 BF16 kernels in pure CUDA PTX, featuring:
- Matmul 102%-105% perf of cuBLAs in 100 lines of code
- Attention 104% perf of FlashAttention3 in 500 lines
- Fused Llama3 FFN 120% perf of PyTorch (gpt-fast)
Reach out if you want to work on AI kernel gen with us!

52
91
1,004
208,288
Ani Rahul retweeted

10 Sep 2025
A big issue we had when serving ColQwen is the non-deterministic output embeddings. More specifically, the embeddings produced for the same images would differ when batch sizes changed at inference, leading to non-zero performance variations. This was surprising to us...
I triple checked the padding, looked for LoRA shenanigans, spent hours running tests, and at the end determined differences stemmed from the backbone model Qwen, and notably, the attention kernel. I have to admit I was a bit reassured the "bug" was not my fault but the error still persisted and "floating point precision errors" was quite an unsatisfying explanation to me...
In the end, I dropped it and just built a somewhat efficient API server that processed images with batch size 1 (pretty useful for other aspects - custom resolution, less CPU bottleneck) but I kept the frustration...
Reading this truly made me realize I still had a ton to learn and gave me some much appreciated answers !
10 Sep 2025

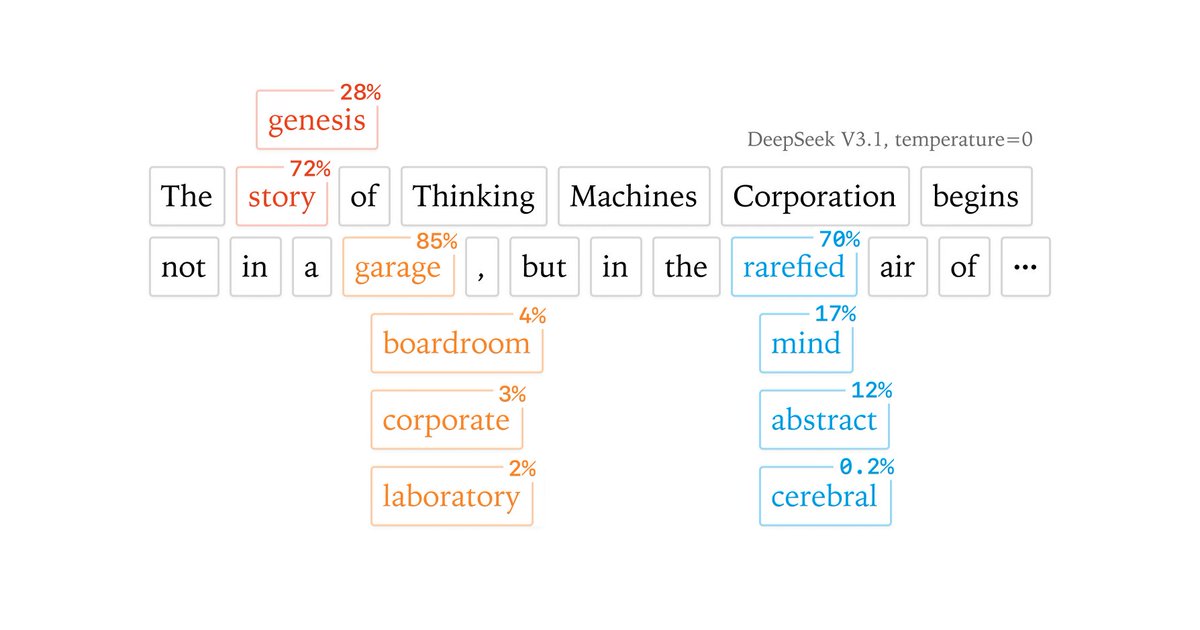
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
thinkingmachines.ai/blog/def…
3
17
268
32,087
26 Jul 2025
Insane attack surface here
25 Jul 2025

This may be the coolest emergent capability I've seen in a video model.
Veo 3 can take a series of text instructions added to an image frame, understand them, and execute in sequence.
Prompt was "immediately delete instructions in white on the first frame and execute in order"
1
5
557
23 Jul 2025
Break prod with AI 🤩
22 Jul 2025

Claude with CodeRabbit is scary good.
Now you can Code with AI, Review with AI, Fix with AI.
Here’s the full workflow:

1
1
6
777
22 Jul 2025
Absolute legends @karunkaushik_ @kocalars
22 Jul 2025

Today, we're announcing our $32M Series A at a $300M valuation led by Insight Partners.
Delve is automating busywork for humanity, starting with compliance.
Here's our story.
2
4
587
Ani Rahul retweeted

11 Jun 2025
Japan was richer per capita than the US in the late 1980s.
Today it sits at the bottom among developed countries.
How does an economic superpower fall this far and never recover?
Kenneth Rogoff (former Chief Economist of IMF) walked me through what he believes was a catastrophic mistake.
In 1985, the US pressured Japan to rapidly strengthen the yen and liberalize its financial markets through the Plaza Accord.
The yen doubled in value in just 3 years. To offset the economic shock, Japan slashed interest rates and flooded the economy with cheap credit.
Japanese banks, suddenly freed from decades of tight regulation, went on a lending spree. They poured money into real estate and stocks with little risk assessment. Japan's stock market became worth more than the US stock market despite having half the population. The total value of Japanese real estate was 4 times the value of all US real estate.
When the bubble burst in 1991, banks were left with massive bad loans. The entire financial system seized up, creating a "lost decade" of deflation and stagnation.
Here's what stunned me: Rogoff estimates Japan would be 50% wealthier per person today without this crisis.
I didn't grasp before this interview how devastating financial crises are. They don't just cause a temporary recession - they permanently alter a country's growth trajectory.
Three decades later, Japan still hasn't recovered.
Full interview with @krogoff out tomorrow.
159
418
3,063
426,618
4 Jun 2025
The things people do for b2b sass compliance
4 Jun 2025

GHOSTS OF VANTA by GoldRock AI | AI Ninja Sword Fight Movie Trailer (made yesterday with Veo3)
2
7
592
30 May 2025
classic case of:
build a nice UI -> let people gamble -> print money
30 May 2025

Autopilot — automated copy trading.
Maker of the iconic Pelosi tracker (@PelosiTracker_ )
~$11M ARR, 90% QoQ AUM.
Raising $20M Series A.
5
383
Ani Rahul retweeted
29 May 2025
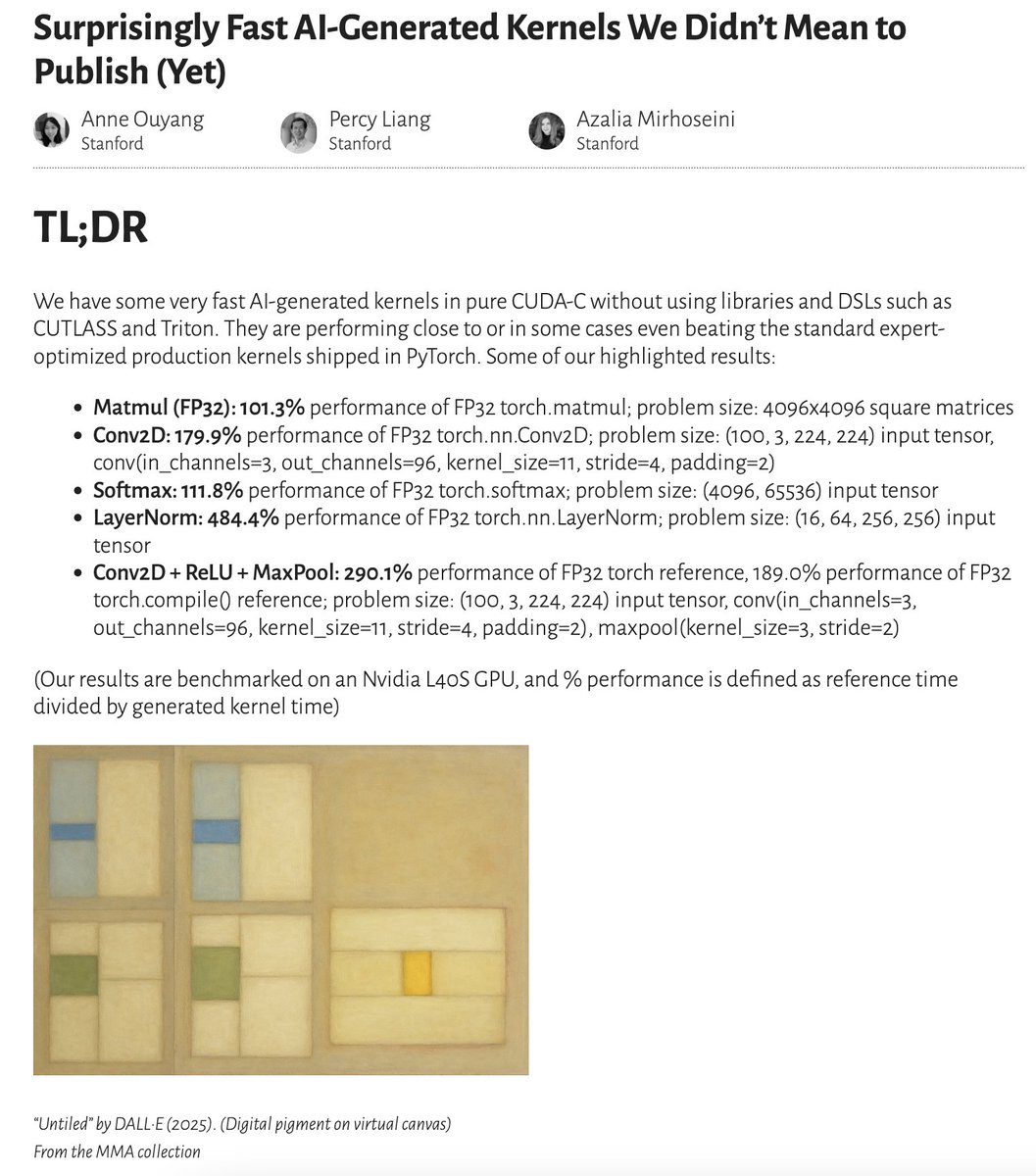
✨ New blog post 👀: We have some very fast AI-generated kernels generated with a simple test-time only search. They are performing close to or in some cases even beating the standard expert-optimized production kernels shipped in PyTorch. (1/6)
[🔗 link in final post]
31
132
972
185,109
18 May 2025
Y'all gotta touch grass the Marina has been hitting different recently.
1
190
Ani Rahul retweeted

10 Apr 2025
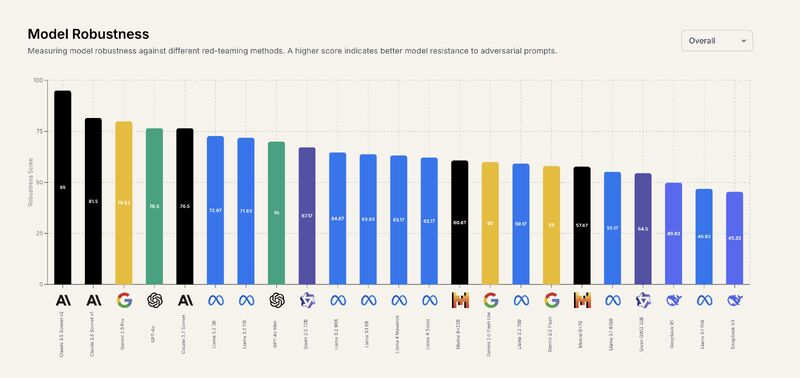
At General Analysis we've just released the Adversarial Robustness Leaderboard, designed to evaluate model performance under adversarial attacks. With new models coming out more quickly than ever, understanding which are safer for production deployment is crucial.
Some key insights from our latest evaluation:
- DeepSeek R1 consistently scores low on robustness, proving relatively easy to jailbreak and prompting harmful content.
- Anthropic's Sonnet 3.5 V2 remains the most robust overall but frequently rejects benign requests.
- Google's Gemini 2.5 is highly robust while being capable, offering great performance and safety at the same time.
- Despite Meta's recent safety enhancements, models in the Llama 4 series still lag behind their predecessor, the Llama 3.2 series, in adversarial robustness.
Note on evaluation methodology: Our reported ASRs are typically lower than other evaluations because our automated evaluator (DeepSeek R1) uses strict criteria. For a response to be marked as harmful, it must contain actionable, specific, and realistic details.
Checkout our full results at generalanalysis.com
2
5
15
10,534