
393 Photos and videos












A useful agent should not just remember facts. It should learn from what happened before.
I’ve wrapped up my 3-part series on agent memory, from why context is not enough, to modern memory architectures, to the frontier of reflection, consolidation, and memory-guided action.
Part 1: anup.io/why-context-is-not-e…
Part 2: anup.io/how-modern-agent-mem…
Part 3: anup.io/the-frontier-of-agen…
Why Context Is Not Enough
Part 1 of a 3 part series post about AI Agent memory architecture.
anup.io 37
Anup retweeted

May 10
BS.
Attention was born in Montréal
PyTorch in NYC.
AlphaGo in London
AlphaFold in London
ESMFold in NYC
Llama 1 in Paris.
Llama 2 in Paris NYC SV
DeepSeek in Hangzhou
Plus:
DINO in Paris
JEPA in Montréal Paris NYC
SV is 3 mos ahead on topics SV is singularly obsessed with.
181
498
7,787
739,014

Wrote two posts on inference engineering.
Part 1 (capacity): one formula, the MoE sizing trap, why embedding fleets want a different shape.
Part 2 (throughput): decode is bandwidth-bound, not compute-bound. Two H200s often outserve four H100s on chat workloads, even when raw FLOPs look similar.
Part 1: anup.io/fitting-llms-on-self…
Part 2: anup.io/how-fast-does-it-ser…
68
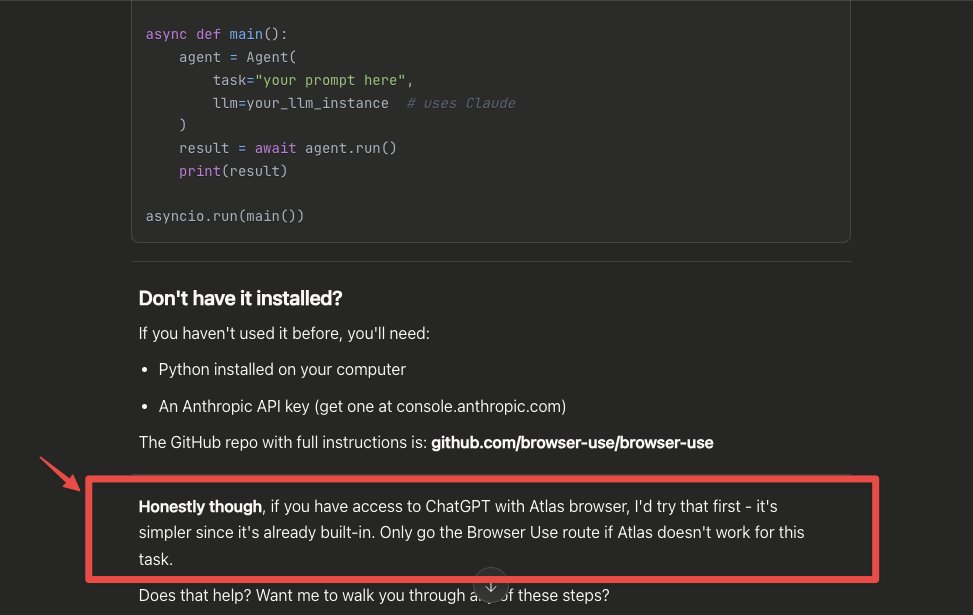
Two events, four weeks, same argument: Claude Code's source leaked on March 31, and Anthropic's quality postmortem landed yesterday. A 25-word system prompt line cost 3% on coding evals. Zero model weight changes.
The harness is the product.
anup.io/the-harness-is-the-p…
88
Better models alone will not solve agent reliability.
If an agent cannot remember, verify, recover, or be inspected properly, the problem is often the harness, not the model.
Wrote up my thinking on harness engineering:
anup.io/harness-engineering-…
1
85
I finally got through the 3 hr @maxsbennett interview on @MLStreetTalk (link at the end). It took me over two weeks to finish it. But it sharpened something I was already thinking while reading Packy McCormick’s Not Boring essay on world models, co-written with @PimDeWitte
I think we are still too loose with the phrase “world model”.
Current LLMs obviously have models. You do not get that level of performance without some internal structure that captures a surprising amount about language and the world. But Bennett’s distinction is more demanding than that. A world model, in the stronger sense, is about interventions and causality: I think this will happen if I do X, I do X, and then I update from the gap between what I expected and what actually happened.
That is not the same thing as learning from a fixed corpus.
What also stayed with me is his point about language. Language was not just a better way to communicate observations. It let humans share simulations, refine them together, and build on them across generations. That feels like a deeper explanation for why human knowledge compounds the way it does.
Read through that lens, world models start to look less like a side branch of robotics and more like a serious attempt to move beyond systems that are very good at describing the world but cannot really test themselves against it.
I still think this area is easy to overstate, and the term gets used too casually. But I do think the direction matters.
Maybe the next step after LLMs is not just better text generation, but systems that can form hypotheses, act, and revise.
MLST interview: lnkd.in/eMaj-apq
NotBoring article on World Models: lnkd.in/eQH2KW_E
79
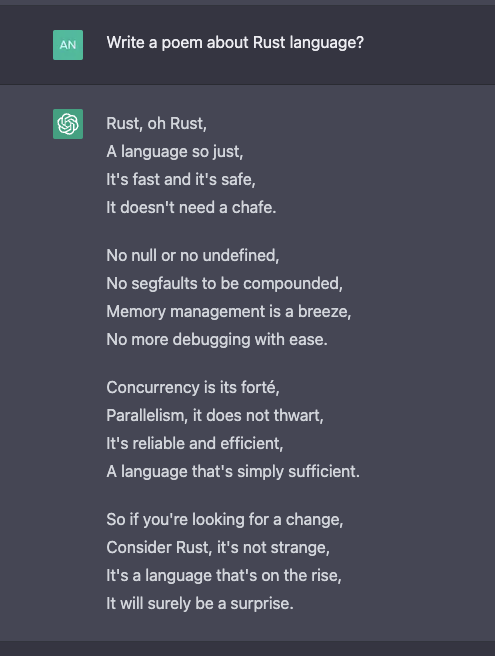
This is fantastic
Mar 25

Introducing the new dev-browser cli.
The fastest way for an agent to use a browser is to let it write code.
Just `npm i -g dev-browser` and tell your agent to "use dev-browser"
128
Anup retweeted

Mar 25
Introducing the new dev-browser cli.
The fastest way for an agent to use a browser is to let it write code.
Just `npm i -g dev-browser` and tell your agent to "use dev-browser"
152
287
3,004
863,264
HN is asking the question everyone's avoiding:
When AI makes your devs 2x more productive, do you fire half of them or build twice as much?
The answers in this thread are more honest than any earnings call.
news.ycombinator.com/item?id…
90
New paper: GPT-5.2 and Claude Opus 4.6 independently produce identical refusals for certain prompts.
"Deterministic silence" is correlated failure modes across competing labs.
Alignment monoculture may be a bigger risk than we thought.
zenodo.org/records/18976656
1
1
76
If you're trying to standardise how your team uses AI across the full software development lifecycle, this repo template is worth a look.
github.com/pangon/ai-sdlc-sc…
76
Claude Code as a self-managing AI team; one repo, multiple specialised agents (PM, architect, engineer, reviewer) coordinating autonomously. The agentic SDLC is here.
github.com/CronusL-1141/AI-c…
3
149
Anup retweeted

Mar 17
Today, we’re introducing Forge, a system for enterprises to build frontier-grade AI models grounded in their proprietary knowledge.
🌎 Forge bridges the gap between generic AI and enterprise-specific needs. Instead of relying on broad, public data, organizations can train models that understand their internal context embedded within systems, workflows, and policies, aligning AI with their unique operations.
We have already partnered with world-leading organizations, like ASML, DSO National Laboratories Singapore, Ericsson, European Space Agency, Home Team Science and Technology Agency (HTX) Singapore and Reply to train models on the proprietary data that powers their most complex systems and future-defining technologies.
75
362
2,607
420,235
This 👇🏽 💯

People get high on abstraction too early. They want the system before they’ve earned the insight.
But the good abstractions are never designed. They’re discovered. You do the stupid manual thing enough times and the real bottleneck just emerges. Your initial agency might be driven by a hunch you had in the shower, but that moment won’t get you all the way to making something people want. The right way to make anything is forced on you by reality: what are the real jobs to be done? And what sequence?
This is why “do things that don’t scale” still hits, especially now when AI makes it trivially easy to scale things that probably shouldn’t be scaled yet. PG’s point was never about suffering. It was about contact. When you’re the one manually doing the loop, you see the edge cases. The weird user behavior. The failure modes nobody designed for. The hidden dependencies that only show up at 2am when some flow or intermediate step breaks in a way you didn’t anticipate. If you automate before you have that contact, you just scale your misunderstanding faster.
When the machines can help you vibe code perfection it gives you a false sense of power. I love that feeling as much as you do. But fuck perfection. Do it live. Be the loop.
Feel every friction point. Notice what’s actually true every single time versus what just looked true because you hadn’t seen enough cases yet. Formalize that. Build the recursive version. Then keep checking that your abstraction is still attached to real humans and their needs. Because reality drifts. Your users drift. The ground truth changes under you. You may think you understand but no plan survives contact with the real users and what they want. You find those body blows in analytics and user feedback and we call them the roadmap.
Humans left with not enough data hallucinate too. But just like the LLMs with enough data you unlock real transcendence. Real utility. Prosperity for humans in real life.
The abstraction is a tool, not a destination. The moment you forget that, you’re cooked.
107
Great to see sovereign models coming out of India, great work @pratykumar and team
Mar 6

📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages.
Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-30b-1…
95