
199 Photos and videos













That's the Musk v. Altman trial in one line.
I built the full story on @geoprotocol — structured, sourced, and open to everyone.
Timeline. Evidence. Both sides. No spin.
geobrowser.io/space/d331fa0b…
built with geobrowser.io/
Web3 life designed.
2
54
This week's @geoprotocol challenge: the Musk v. Altman trial I built a full research space on it — timeline, charts, structured claims, verified sources, and the most viral posts from both sides Everything you need to understand the biggest AI lawsuit in history.
geobrowser.io/space/d331fa0b…
Musk donated $38M to an AI nonprofit in 2015 That nonprofit is now worth $852 billion — as a for-profit company His claim: they stole the charity Their claim: he wanted control and didn't get it Both things can be true.
The journal entry that shook the courtroom Brockman's 2017 personal journal — read aloud in court — said he was "warm to steal the nonprofit from Musk to convert to b corp without him" That's not a good sentence to have in your diary when you're the defendant.
The plot twist Musk admitted under cross-examination that his own AI company xAI uses OpenAI's models to train its systems He's suing OpenAI for commercialising AI While building a commercial AI company on their research Audible gasps in the courtroom.
Genuinely.
2
5
282
Spent the last 2 weeks deep in the @geoprotocol Curator program lead by @yanivgraph building a dataset on 10 of the most influential figures in crypto.
From early pioneers to modern innovators, mapping their global impact, networks, and contributions has been an eye-opening journey into how decentralized tech is shaped by people as much as code.
Excited to share more insights soon .
2
9
209
AthinkT retweeted

Apr 14
Missed the Week 12 curator call? Catch up below.
This week, we shipped inline entity linking, reopenable rejected edits, and curators can now create their own public spaces to publish and iterate faster.
Watch the full recap ↓
youtube.com/watch?v=w8qAOx7e…
1
6
16
482
As a participant in the @geoprotocol Curator Program, I’ve spent the last 2 months transforming fragmented AI and infrastructure data into a structured, relational graph.
Seeing these schemas (from RPC providers to complex datasets) finally go live is a massive win for the ecosystem.
Now, officially waiting for mine first accepted bounty!
Mar 17

Week 8 of our curator program, and contributions keep getting stronger and stronger.
Points are being allocated for the first time, and curators are showing what's possible with structured data.
Plus, one of our amazing curators covered how AI is helping historians read carbonized scrolls that sat untouched for 275 years.
Watch the full call here 👇
5
11
815
For me, participating in the @geoprotocol is not only about building a new format of knowledge in Web3, but also a unique opportunity to meet amazing and interesting people who are creating breakthrough technology.
Thank you to @yanivgraph and my mentor Armando for this opportunity.
We are just started🚀
Feb 27
Publications are picking up pace across Geo!
AI:
→ Active grant programs catalogued.
→ Major AI policy documents and regulatory frameworks mapped.
Health:
→ All major organs structured, with primary functions and key diseases/procedures.
Special shoutout to @LOstaevi, @rufat31947337, and @AthinkT for their amazing work!

1
2
5
679
Big milestone in my @geoprotocol curator journey .
My first data sheet has been officially accepted by my mentor — a small step for the graph, a huge step for me.
Curating isn’t just collecting links. It’s structuring knowledge, clarifying claims, and building signal in a noisy world.
Excited to keep mapping ideas and contributing to open, pluralistic knowledge with @geoprotocol.
Onward.
61
Just officially onboarded as a Curator for @geoprotocol !
Ready to help build a decentralized, community-governed knowledge graph where facts are verifiable and information is open. Let’s map the world’s knowledge together.
BTW my first points 😍
2
1
3
295
Join the Geo Movement 😍
True educational problem-solving isn't about finding a single right answer. It's about creating a structured pathway through complexity so that others can learn, explore, and form their own understanding.
That's exactly the mindset I'm bringing to the @geoprotocol program in the Education space. As educators, we are master curators and system architects. We diagnose knowledge gaps, sequence concepts, and connect resources to build bridges for learners. The @geoprotocol provides the tools to apply this skill at scale to society's biggest knowledge problems.
57
This is what I like in Geo!
Pluralism is a key value at @geoprotocol . Anyone can create a space, and there can be competing spaces on the same topic. Within a space, disagreements are expressed through claims, where participants can agree or disagree, add arguments for and against, without imposing a single truth."
This insight from Geo CEO @yanivgraph in yesterday's AMA perfectly captures why their approach to knowledge is different.
Instead of a top-down encyclopedia or a messy forum, Geo is building a dynamic map where multiple perspectives coexist and are structured through claims and evidence. It's a protocol for understanding complexity, not simplifying it.
This is how we organize the world's knowledge, together.
2
12
535
I`m in and you? 🥰
Modern science is stuck, not for lack of data, but for lack of a coherent map to navigate it all. What if the solution isn't another search engine, but a new layer of context?
Introducing @geoprotocol : a movement to build a collective, structured knowledge graph. Here’s how it can tackle today's biggest scientific challenges.
The core problem? Information is fragmented. Breakthroughs in genomics, AI, and climate science are published in silos. Researchers waste time connecting dots that should already be linked. Geo's answer is coordinated curation by experts to build a dynamic map.
Imagine a living knowledge graph for science. Instead of a PDF, a research paper becomes a node connected to its supporting data, the models it used, related studies, and even contradictory evidence. This is the structured context @geoprotocol enables.
2
6
326
Summoning my favourite protocols @Uniswap @rarible @opensea to join the movement!
ETHGas is introducing the Open Gas Initiative, eliminating gas fees from the end-user experience
Learn more: ethgas.com/open-gas/
x.com/ethgasofficial/status/…
3 Dec 2025

Introducing the Open Gas Initiative - a way for protocols to subsidize gas for users, zero-code, for a seamless, frictionless onchain experience.
With OG cohort: @eigencloud, @ether_fi, @pendle_fi, @Velvet_Capital.
👇
55
The beanstalk is sprouting stronger! ✨
Teaming up with Gassy Jack to climb the beanstalk. Collect beans through quests and unlock epic rewards in our gas-free world. Who's in? 👀
ethgas.com/community/onboard…
ethgas.com/community/onboard…
27
The numbers don't lie: @Polymarket has processed over $7.74 BILLION in volume this year.
What fascinates me mathematically is the predictive accuracy:
• 95.1% accurate 4 hours before events
• 91.3% accurate a full month out
This isn't gambling - it's real-time Bayesian updating where prices = probabilities and every trade refines the collective forecast.
The market's ability to synthesize dispersed information into accurate probability distributions is mathematical elegance in action. Where else can you watch global belief calculus unfold in real-time?
Mathematics does not lie. Never. Try at @Polymarket.
41
The beauty of @Polymarket isn't just in winning bets; it's in observing a real-time, dynamic Bayesian inference machine in the wild.
When the market prices an event at 62%, that's not a static guess. It's a consensus probability, a synthesis of all available information, weighted by the conviction of participants. It's the market's prior.
Every new trade is a data point. A large buy order? That's a strong likelihood function updating the prior. The price adjusts, reflecting a new posterior probability. This is Bayes' Theorem, powered by capital and conviction instead of just equations.
We're watching the Wisdom of the Crowds formalized into a live probability distribution. It's a fascinating, decentralized mechanism for aggregating knowledge and quantifying uncertainty about anything.
While not perfect, these prediction markets often outperform polls and pundits because they force people to "put their money where their mouth is." The signal emerges from the noise.
So next time you see a market on @Polymarket , don't just see a price. See a collective, mathematical forecast of reality.
42
Hey @EnsoBuild , is it ok for you to give your OG user with 500 USDT spent in fees just ... TADAM - 9 ENSO🧐 WTF is wrong with you? But you still have a chance to rearrange more allocation . Check how
@HyperliquidX is working with its community. Learn it
1
75
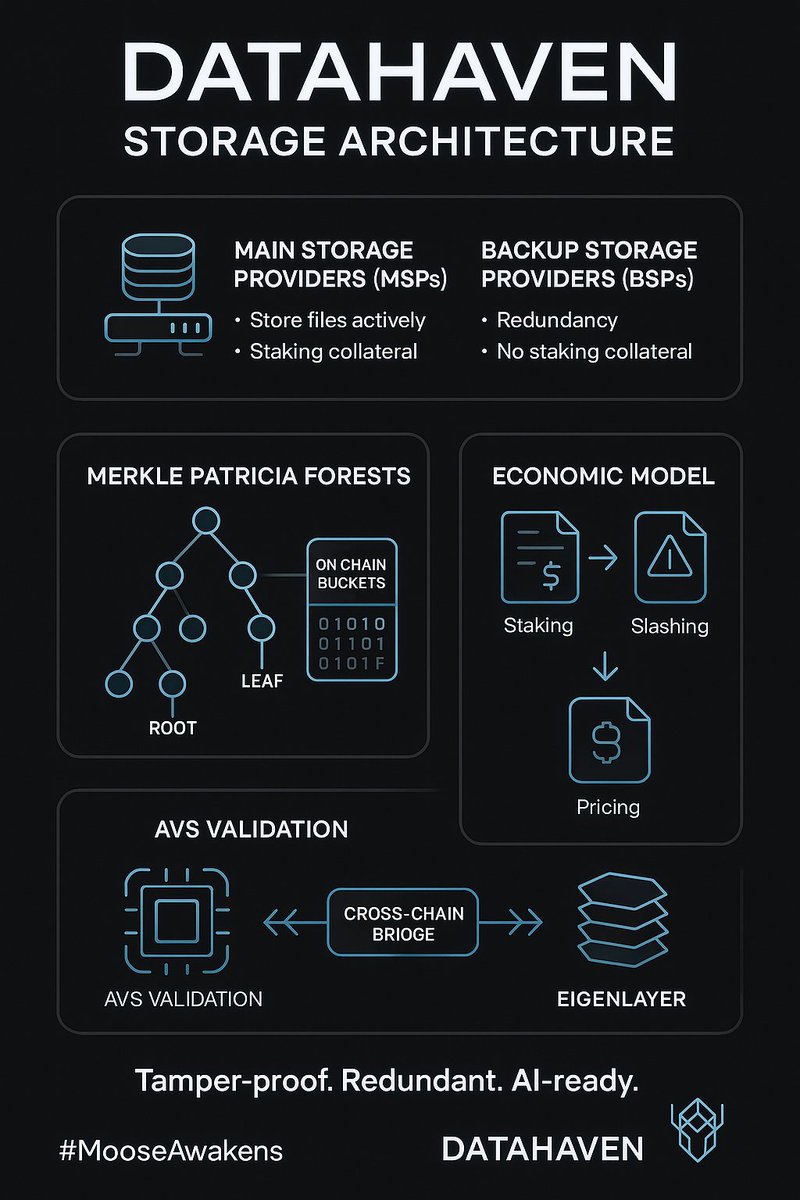
Let’s unpack how @DataHaven_xyz combines Merkle Patricia Forests, slashing economics & EigenLayer-secured AVS validation into a next-gen storage protocol.
The foundation: DataHaven is not just storage.
It’s an AVS (Autonomous Verifiable Service) running its own Substrate-based L1 with full EVM compatibility.
But under the hood is a dual-provider model for data durability & economic guarantees.
MSPs (Main Storage Providers)
Actively store files
Serve real-time retrieval
Required to stake collateral
Indexed via on-chain file-bucket mapping
Verified through Merkle challenges
Their job: high-availability verifiability.
BSPs (Backup Storage Providers)
Passive replicas
Lower bandwidth, no live read access
Only challenged periodically
Optimized for redundancy P2P fallback
Also slashable (if data unavailable)
Redundancy becomes protocol-native, not optional.
Merkle Patricia Forests (MPFs)
Forget bloated per-file tracking.
Each storage "bucket" is mapped to an MSP or BSP and stored on-chain as a Merkle Patricia Forest root.
This enables efficient commitment of millions of files with one digest.
Think "Merkle tries, but leveled."
Merkelized Files
Each file → chunked → hashed into its own Merkle tree.
Storage proofs randomly challenge chunks via index lookup.
The provider must return both the chunk and its Merkle branch path.
Compact. Verifiable. Slashing-enabled.
Storage Proof Pallet
Custom Substrate pallet that:
Generates challenge windows
Picks random chunk indices based on epoch randomness
Verifies returned Merkle paths
Updates reputation or slashes accordingly
All logic is modular & on-chain governed.
Economic Layer
Storage providers (MSPs/BSPs) post system token collateral
Storage costs are $-pegged (e.g., $/GB/month) but paid in native token
Fail a challenge → slashed
Deliver consistent uptime → rewarded
No centralized reputation. Just math.
Discovery & Matching
Storage requests get routed to eligible MSPs/BSPs
Matching considers capacity, latency, pricing, history
Agreements are recorded on-chain via signed storage deals
AI agents can programmatically shop for storage
Composable storage market primitives.
Challenge Distribution
Challenge frequency = function of storage volume
→ 1 TB = more frequent proofs
→ Small provider = less overhead
Proofs scale linearly w/ data, not provider count.
Also avoids front-running: challenge index is epoch-randomized.
BSPs ≠ "cold storage"
They're active in the protocol. They must respond to:
Merkle root proof-of-possession
Random challenge payloads
Retrieval requests if MSP fails
They’re the silent heroes of decentralized durability.
AVS Synergy
MSP/BSP validation & proof handling is secured by EigenLayer restakers.
Operators running the DataHaven AVS are incentivized to:
Relay proofs
Track validator uptime
Distribute rewards
Slash misbehavior
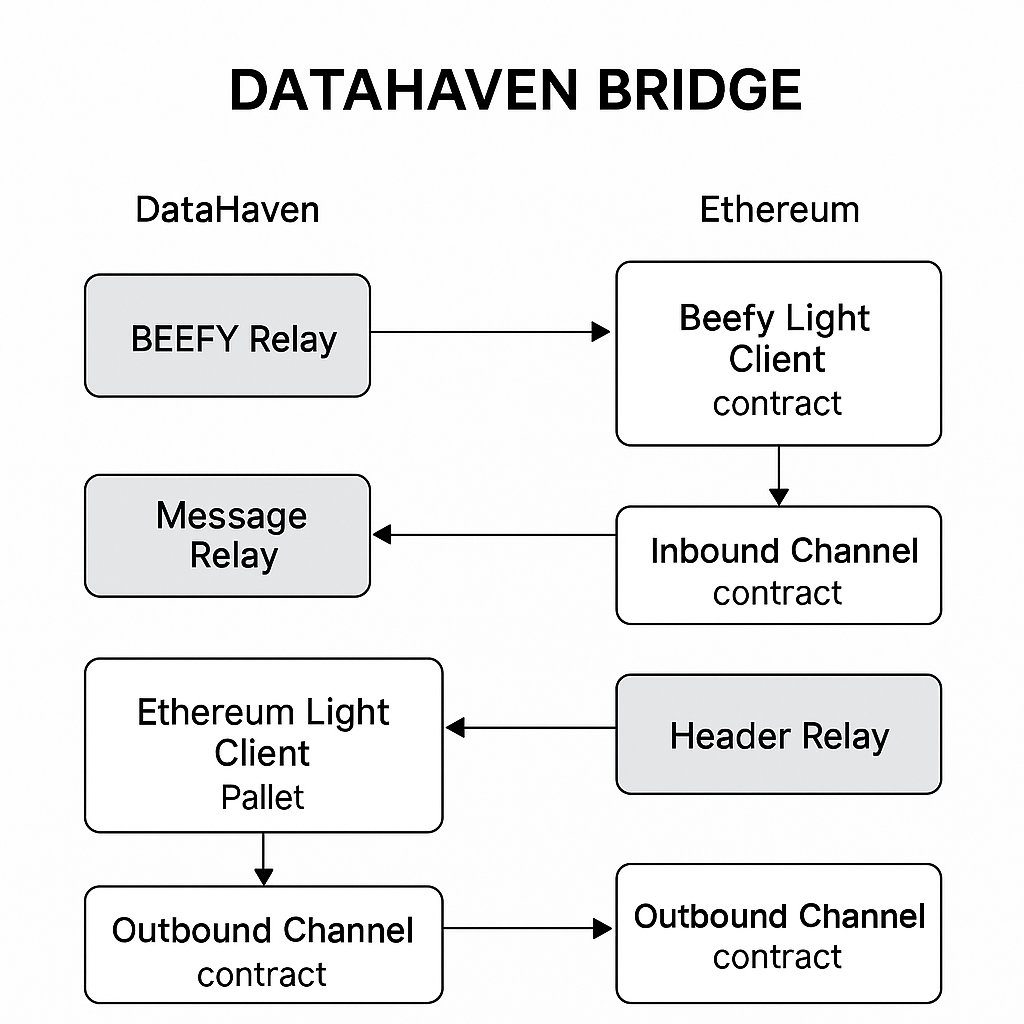
Bridged proofs = cross-chain accountability.
Why does this matter?
Because your AI models, tokenized asset docs, or DAO records deserve better than:
❌ IPFS pinning
❌ off-chain blob storage
❌ centralized backups
DataHaven makes storage first-class in crypto.
Want to build on it?
Native EVM support (Frontier/Moonbeam modules)
StorageHub RPCs for file ops
JSON-RPC endpoints for proof coordination
Full on-chain governance
Modular pallet system to extend runtime
Bring your own storage use case.
Verdict?
@DataHaven_xyz is not a Filecoin clone.
It’s a cryptoeconomically secure, challenge-based, AVS-native protocol for the AI x Web3 era.
Merkle forests, slashing logic, dynamic pricing — this is what future-proof storage really looks like.
1
2
92
Moose Awakens @DataHaven_xyz
Want $GLMR, NFTs, or alpha access?
Here’s how Moose Keys work (and why you need them): 👇
Moose Keys = your grind currency
Earn them by:
— Chatting in Discord
— Completing Zealy quests
— Posting memes, threads, videos
— Helping others
— Engaging on Twitter (X)
Spend them in Moose Market:
Gacha spins ($1–$10 GLMR)
Redeem $10–$70 GLMR
Unlock NFTs
Enter MooseDoor
🚪 MooseDoor = VIP zone
🔓 Secret bounties, early alpha, hidden channels
🦸 Earn your way to MooseBuddy status
But stay active — or lose access.
Grind = rewards
Top 20 every 2 weeks win real $GLMR.
Bonus prizes for viral memes random luck.
—
Join the quest: discord.gg/datahaven
MOOSE ON
1
3
234