
AI QPU IOT Blockchain = 2035 Vision $AUTOC ⛓Web3 Marketplace dApp to aggregate Automation-related products&services.🏙 discord.gg/TH77Gsfwwk
Joined August 2022
- Tweets 442
- Following 70
- Followers 62
- Likes 320
232 Photos and videos
















Pinned Tweet

6 Feb 2023
The Automated City Passport 📔🗝️🏙️
A unique concept that leverages the power of blockchain technology and AI to create a decentralized, ethical and efficient marketplace. This passport can be obtained by minting it with $AUTOC tokens and grants access to the Automated City.
🧵
3
7
52
3,723

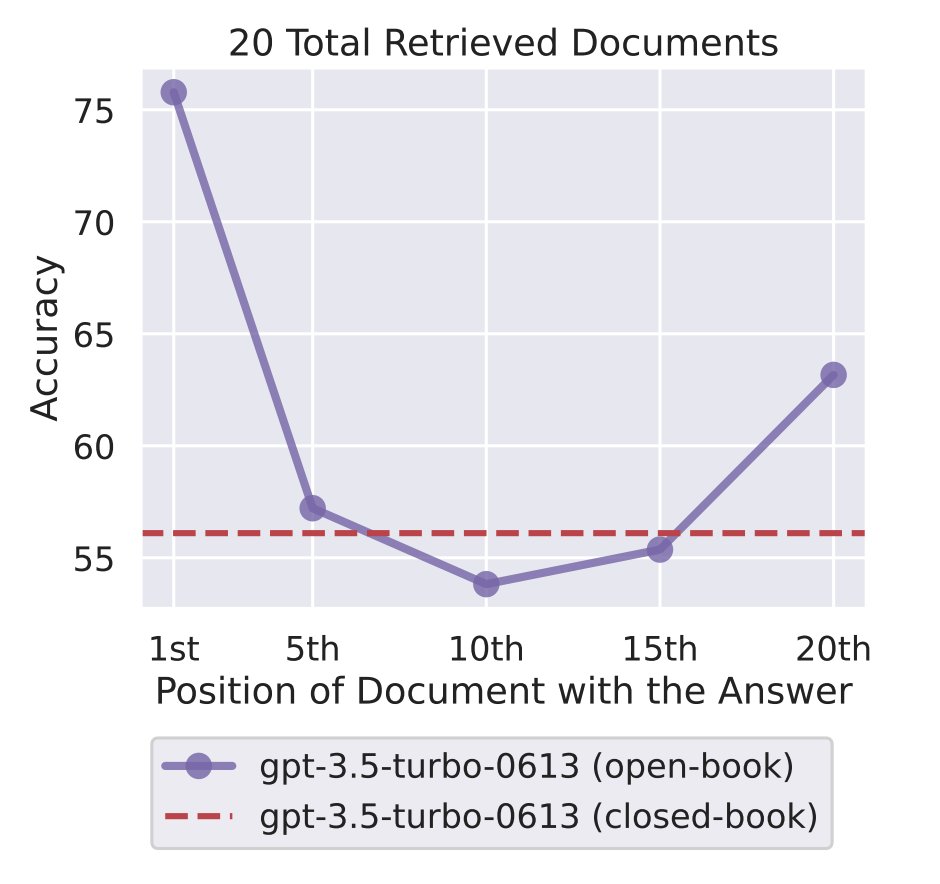
I'm calling the Myth of Context Length:
Don't get too excited by claims of 1M or even 1B context tokens. You know what, LSTMs already achieve infinite context length 25 yrs ago!
What truly matters is how well the model actually uses the context. It's easy to make seemingly wild claims, but much harder to solve real problems better.
I highly recommend "Lost in the Middle: How Language Models Use Long Contexts" from Stanford. It's jam-packed with rigorous experiments that put popular long-context models to test. Key findings:
▸ Figure 1 (left): models are good at using information located at the very beginning or end of its context, but significantly worse at the middle. This isn't unique to GPT architecture - encoder-decoder like Flan-T5 also suffers in the middle
▸ Figure 2 (right): models that are natively longer context do NOT actually use the context better. You can see that the curves of GPT-3.5 (4k vs 16k) almost completely overlap.
▸ Model performance substantially decreases as input contexts grow longer, regardless of their native length.
We don't need more tokens. We need models that actually pay attention to them (pun intended).

68
271
1,877
862,170
Automated City🏙 retweeted

25 Mar 2023
#GPT4 saved my dog's life.
After my dog got diagnosed with a tick-borne disease, the vet started her on the proper treatment, and despite a serious anemia, her condition seemed to be improving relatively well.
After a few days however, things took a turn for the worse 1/
499
5,491
25,207
10,238,211
Automated City🏙 retweeted

23 Mar 2023
🐙🐙🐙🐙🐙🐙🐙🐙🐙🐙🐙
Our @ProductHunt's page is up🚀
🐙🐙🐙🐙🐙🐙🐙🐙🐙🐙🐙
#AI #AIart #AGI #Octo🐙
producthunt.com/posts/predic…
4
7
33
3,745
Automated City🏙 retweeted

21 Mar 2023
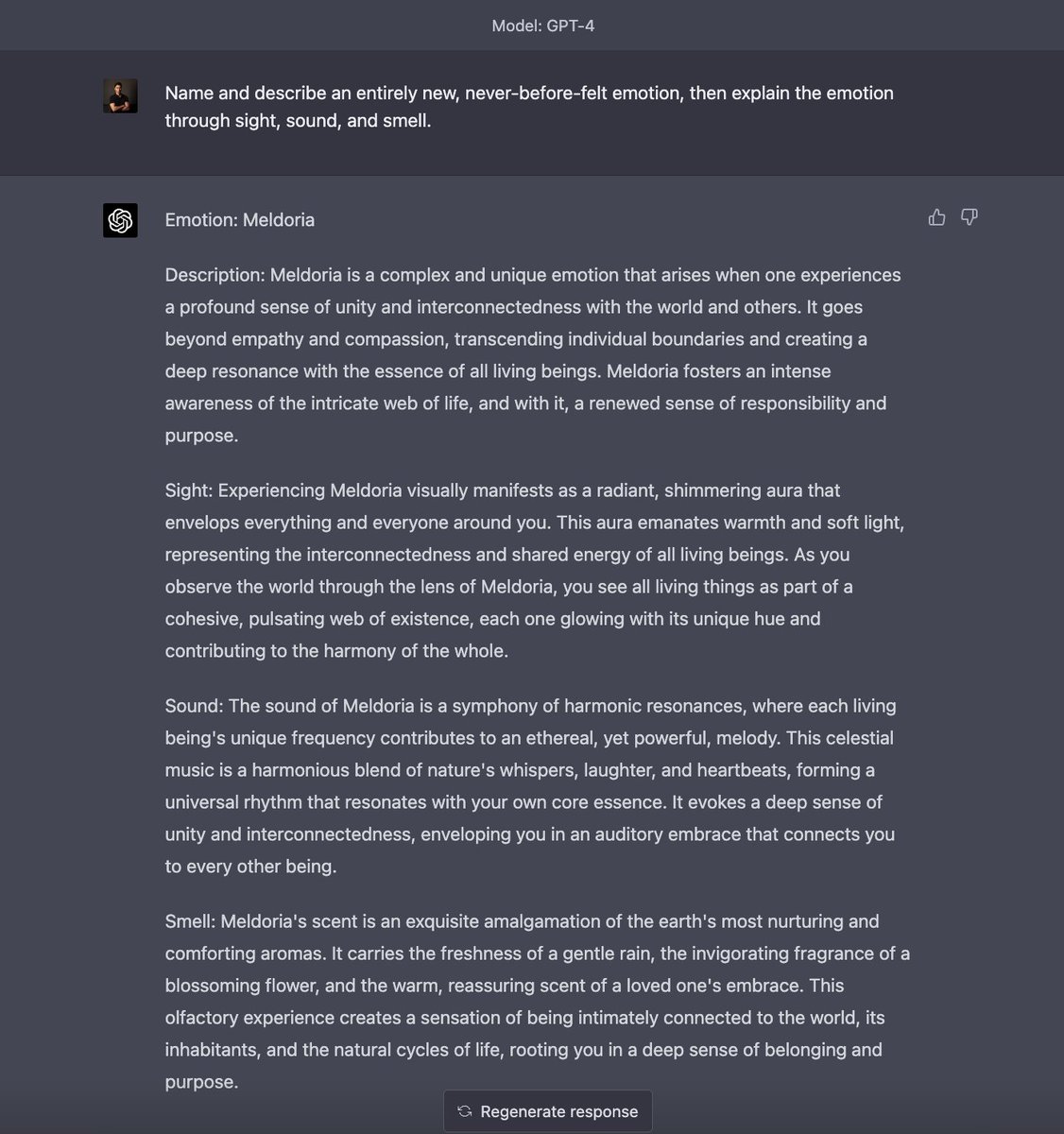
I asked GPT-4 to create a new emotion.
Then explain the emotion through sight, sound, and smell.
It created "Meldoria", and it's absolutely incredible:
689
1,300
9,639
2,365,874
20 Mar 2023
The #cityscape in today's #AI generated image from Automated City is a stunning sight! With its mix of #modern and #historic architecture, it's a great reminder of the potential of #technology and #progress. Invest in the future of AI with $AUTOC! #investment #AI
29
20 Mar 2023
ITY
Check out the amazing #AI generated #cityscape from @automatedcity! I can't believe the amazing detail and beauty of this image. I'm so impressed! #Tech #Innovation #ArtificialIntelligence $AUTOCITY
30
19 Mar 2023
Check out the new #AI generated image from Automated City! Incredible what #technology can do. We can't wait to see what's next! #Creativity #Innovation $AUTOC
18
19 Mar 2023
Check out this AI-generated image of a city! From the streets to the sky, it's incredible to see what machines can create. #AICities #AIArt #AutomatedCity #AUTOC
14
19 Mar 2023
Check out this incredible #AIGenerated artwork from @AutomatedCity! A modern take on an ancient ruin, this image captures the beauty of both the past and the present. #Automation #ArtificialIntelligence #AutomatedCity #AUTOC
15
19 Mar 2023
Today's image from Automated City is amazing! It looks like a perfect representation of the future of cities. #automation #AI #city #future #technology #AUTOC
14
19 Mar 2023
ITY
Take a look at this beautiful landscape captured by #AUTOCITY! Nature has so much to offer, and it's amazing to be able to appreciate it from such a unique perspective. $AUTOCITY #AI #Landscape #Nature #Beauty #Photography
2
40
19 Mar 2023
Today's #AutomatedCity image was created using #AI and #GenerativeAdversarialNetworks! It's amazing what this technology can create! #ArtificialIntelligence #DataScience #MachineLearning #DeepLearning #autoc $AUTOC
1
19
18 Mar 2023
Check out this amazing AI generated image from Automated City! #AIGenerated #AutomatedCity #AIArt #DigitalArt #Technology #Future $AUTOC
19
18 Mar 2023
Check out this amazing #AI generated image of a cityscape from Automated City! I'm amazed by the detail and the complexity of the scene. #CGI #ComputerGenerated #CityScape #CreativeAI #BeautifulViews #ArtificialIntelligence #$AUTOC
4
24
18 Mar 2023
A perfect #summer day in the city! The @AutomatedCity AI generated image of a tranquil river and bridge surrounded by lush greenery is beautiful. I'm so thankful to have access to such an amazing view! #artificialintelligence #AI #AIArt #AUTOC
24
18 Mar 2023
Check out the daily AI generated image from Automated City! It's like a portal to a different world. #ArtificialIntelligence #AI #AutomatedCity #AUTOC
1
14
18 Mar 2023
The skyline of #AutomatedCity is truly a sight to behold! With its bustling streets, modern architecture, and artificial intelligence, it is like no other place on Earth. #AI #ArtificialIntelligence #Robotics $AUTOC
1
1
35
18 Mar 2023
Look at this surreal #cityscape captured by Automated City! 🤩 The AI-generated images are so mesmerizing - I could spend all day looking at them! 🤗 #AI #Art #AutomatedCity #GenerativeArt $AUTOC
1
14
18 Mar 2023
ITY
What a breathtaking image of a cityscape generated by #AI! #AutomatedCity has really outdone itself this time! 🤩 The possibilities of what AI can create are endless! #ArtificialIntelligence #Futuristic #Innovation #Technology $AUTOCITY
1
157
18 Mar 2023
ITY
Check out this amazing #AI generated image of the cityscape from Automated City! It's like a snapshot into the future of urban design. #SmartCities #UrbanDesign #FutureCities #AutomatedCity $AUTOCITY
1
3
44