
Co-founder & CEO @AptosLabs. Building the global trading engine & decentralized cloud. Ex @Meta Libra/Diem crypto techlead. Supercomputing PhD. @CFTC GMAC sub
Joined July 2011
- Tweets 9,828
- Following 2,434
- Followers 67,503
- Likes 48,151
299 Photos and videos






Trade everything onchain

4
3
56
2,421

Jun 13
Decentralized AI will fill this gap. #shelbyserves
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
9
7
48
2,283
avery.apt 🇺🇸 retweeted

Jun 12
The market debut everyone is watching now has a perp market on Decibel.
$SPCX perps are live at up to 5x leverage.
24/7 exposure. Fully onchain execution.
→ app.decibel.trade

149
154
283
11,806
Jun 12
Trade the hottest launch ever on @DecibelTrade soon!


10
6
57
1,911
Jun 12
#1
Jun 11

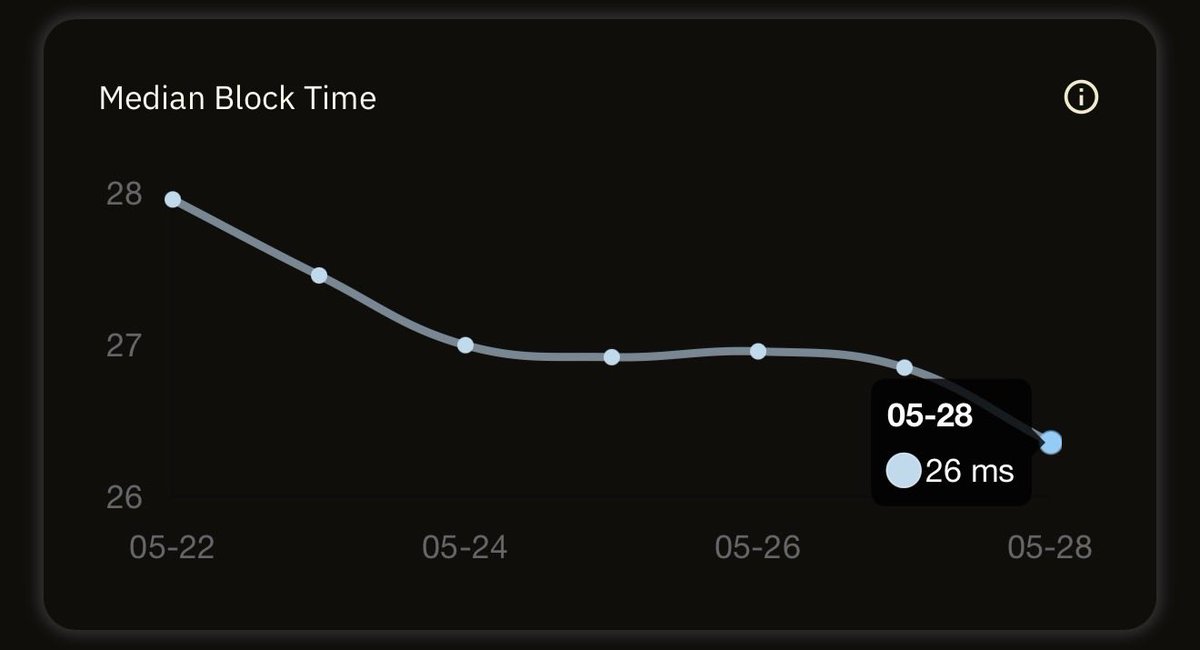
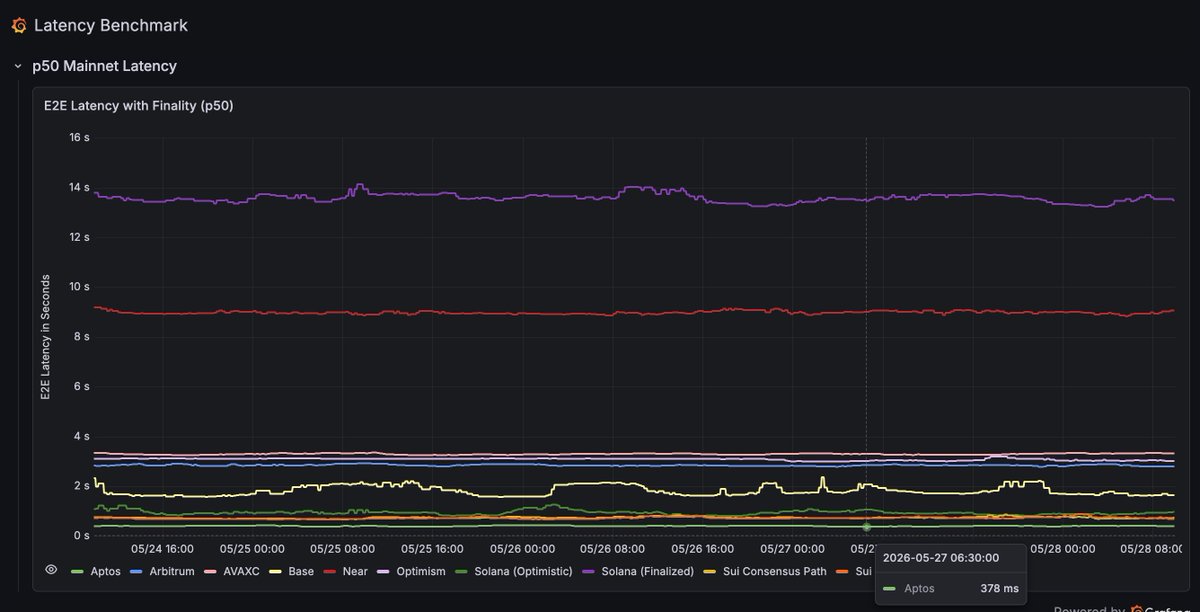
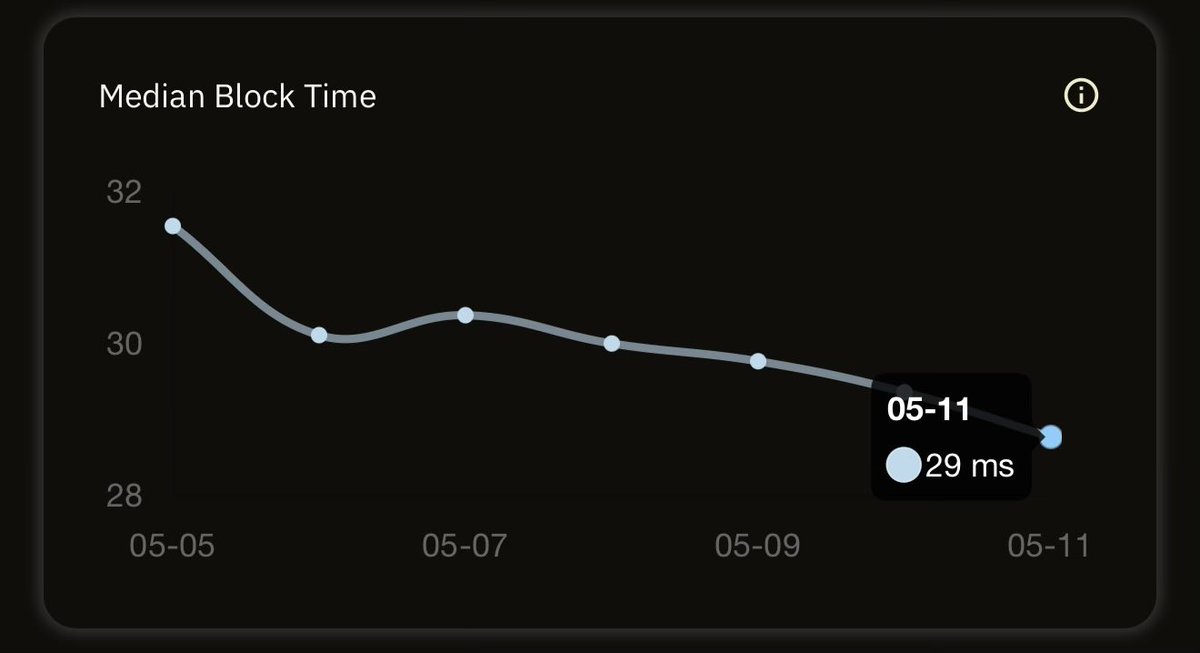
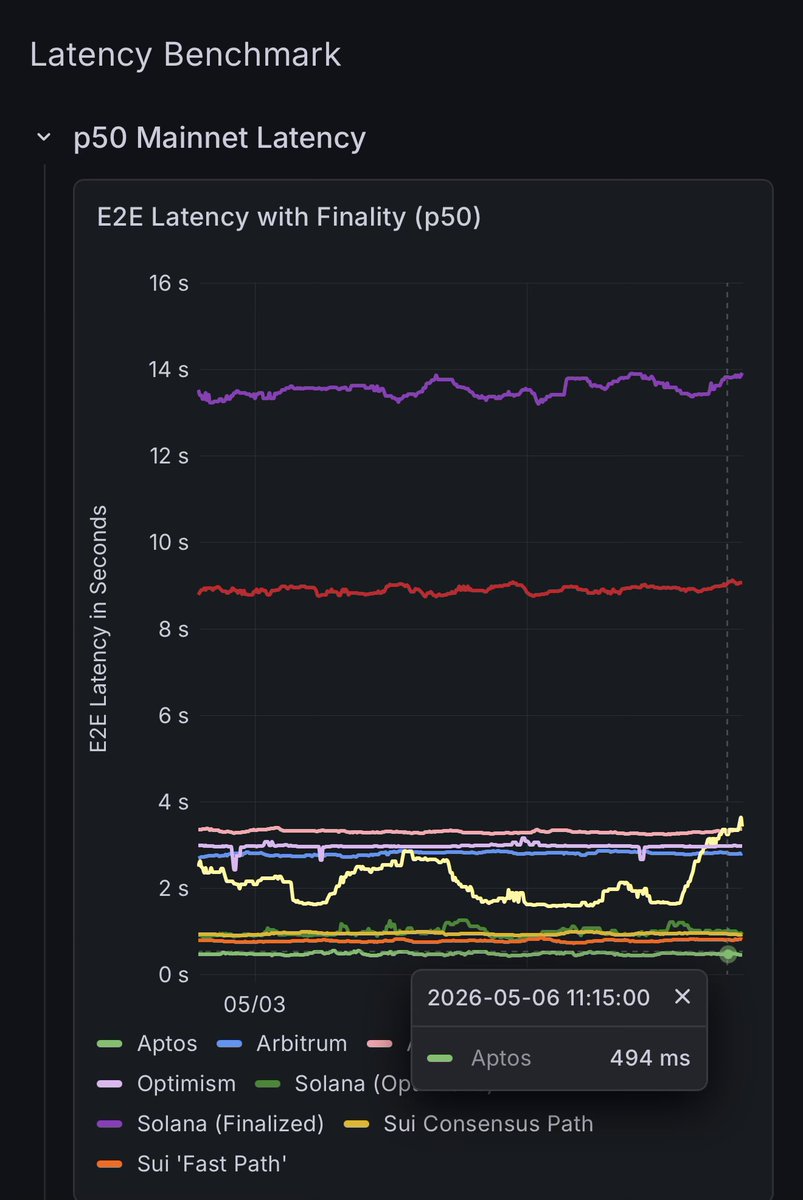
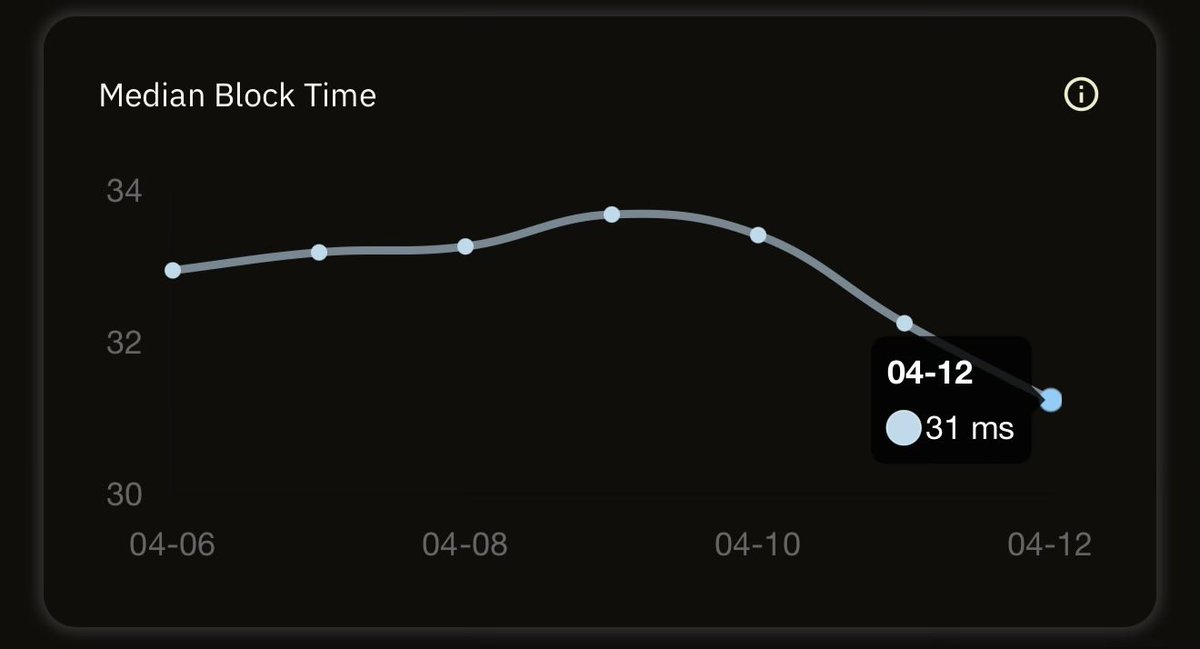
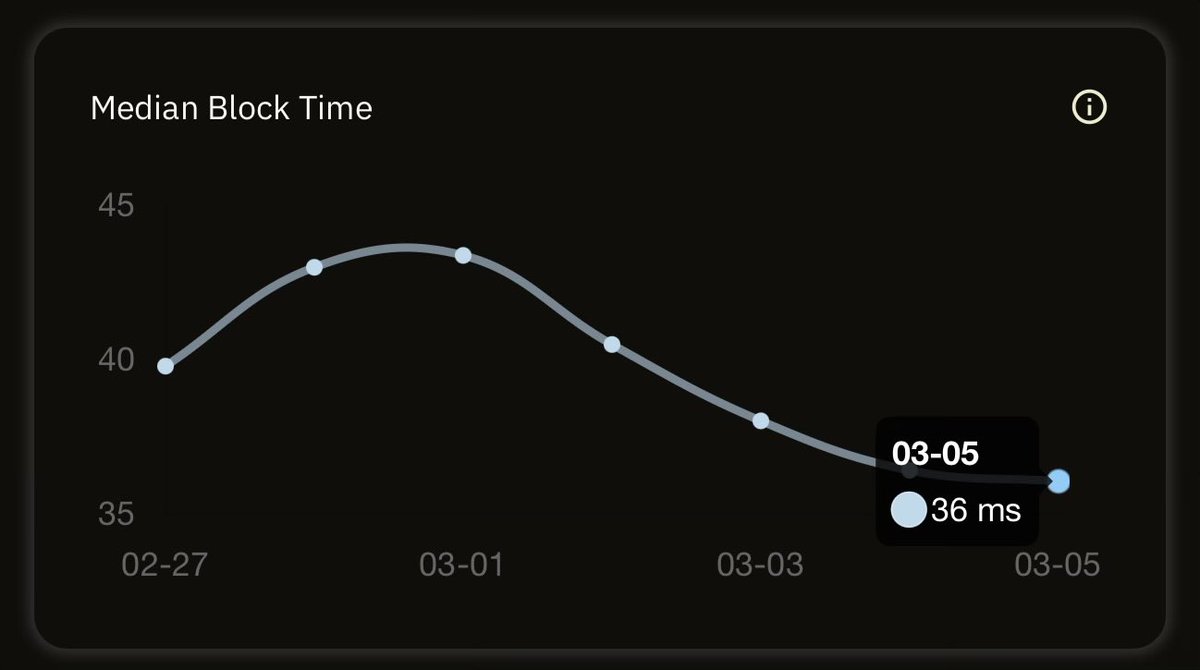
⚡ The Sub-Second Club
Some blockchains take minutes to produce a block. These networks do it in less than a second
Here are the top networks that produce blocks faster than a blink of an eye 👇
chainspect.app/chart/time?me…
14
12
72
2,728

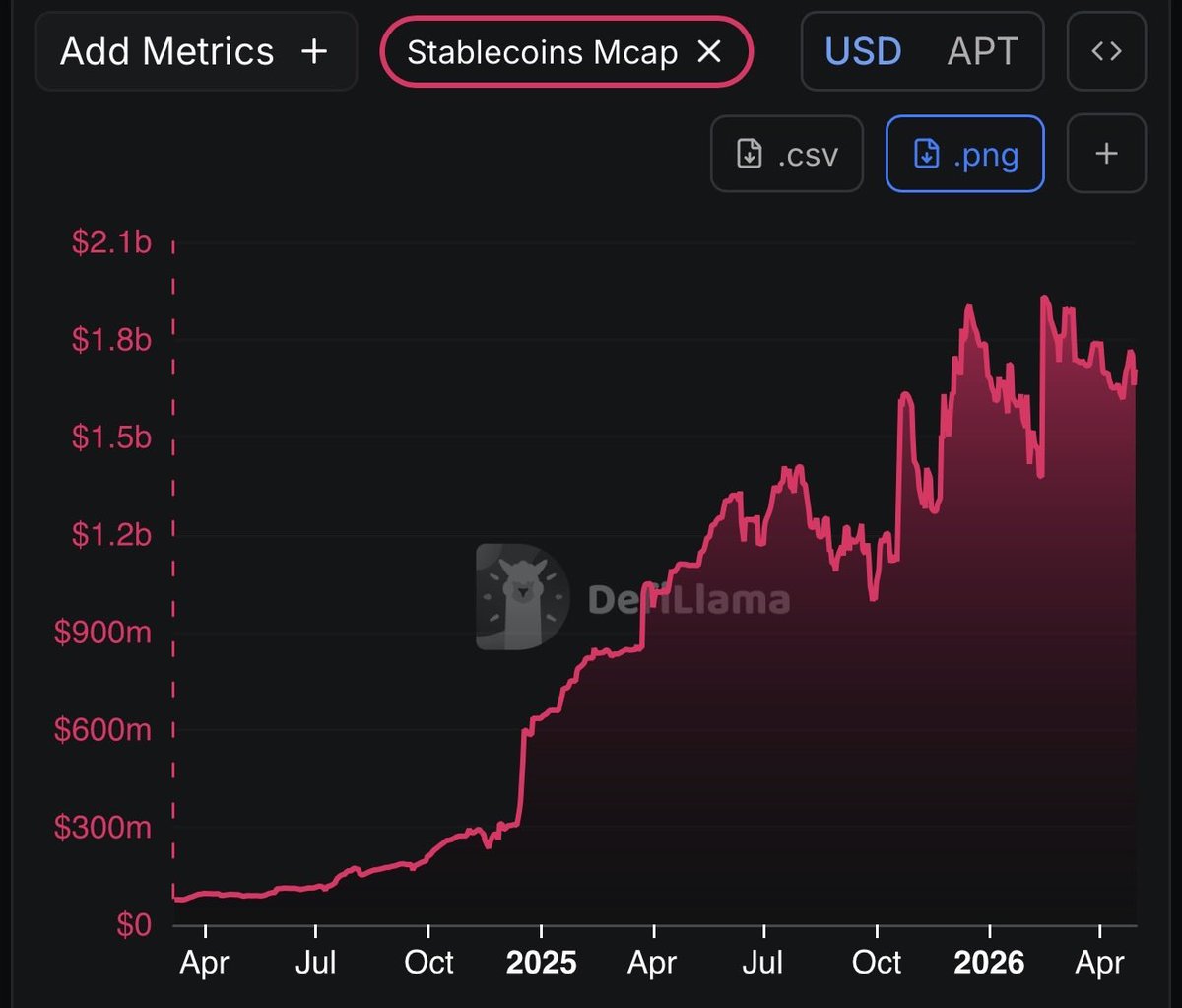
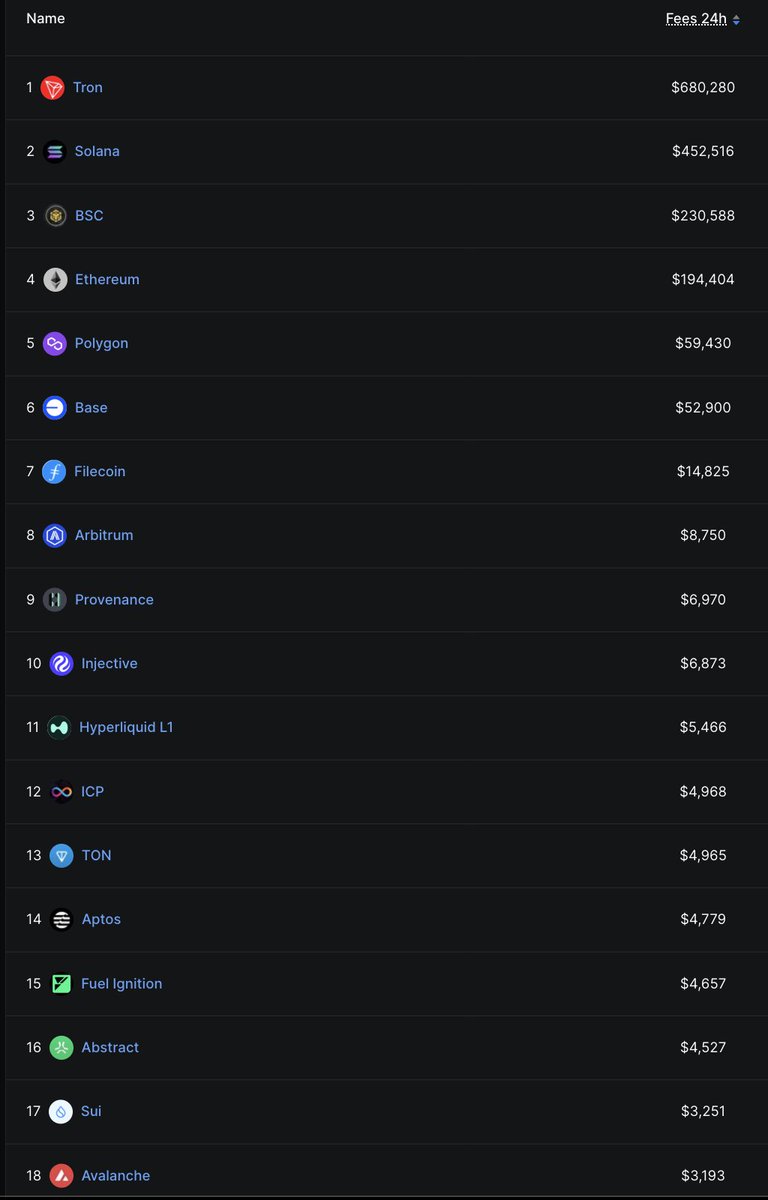
187.8K APT burned in May. Permanently removed from circulation.
1.2M total burned since mainnet. 2.1B hard supply cap is live. Performance-driven tokenomics, in action, on the full stack for markets and machines.
aptosnetwork.com/apt-supply
243
211
760
20,605
Jun 12
Ready. Set. Trade.
Jun 11
Decibel is now open to eligible traders.
Fully onchain orderbook.
24/7 markets.
No invite required.
Onchain execution should be accessible by default.
→ app.decibel.trade

5
4
43
1,800
avery.apt 🇺🇸 retweeted
Jun 11
More real-world markets are moving onchain.
Copper and natural gas perps are now live on Decibel.
→ $COPPER at up to 20x leverage
→ $NATGAS at up to 10x leverage
Trade commodity perps 24/7 on a fully onchain orderbook.
→ app.decibel.trade

154
134
248
16,004
avery.apt 🇺🇸 retweeted

Jun 11
Equity perps. Onchain order books. RWAs issued by regulated institutions. The use cases on @Aptos keep compounding.
Aptos Labs is contributing to the full-stack infrastructure capital markets are converging on. @DecibelTrade, incubated by Aptos Labs, is proof.

65
61
281
8,978
Jun 9
Every investment made in AI compounds when a major model upgrade.
Organizations that invested early in workflows, infrastructure, evaluation, automation and productivity immediately compound wins with @claudeai Fable 5.
We’ve already been putting Mythos and other AI security models to work hardening infrastructure. The pace of capability growth means the ROI on those investments keeps increasing.
Global trading of trillions takes a big step forward.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
12
7
50
2,498
Jun 9
Moving for CLARITY!
Jun 9

Clear rules for developers aren't a concession. They're how you keep innovation in the U.S.
Aptos Labs Co-Founder & CEO @AveryChing joined 60 crypto CEOs—@coinbase, @Aave, @HyperliquidX, @Uniswap, & more—urging the Senate to preserve developer protections in the Clarity Act.

8
5
71
3,144
Jun 9
Confidential assets in @aptos mainnet and stablecoin settlement across borders. This is not the future. Live.

Stablecoin settlement between MENA and Africa—settled on Aptos.
@TheStreet covers Africa as the fastest-growing stablecoin market, and how the new regulated B2B corridor with @Daya_HQ & @HashKeyMENA meets that demand with expansion on the horizon.
Read: thestreet.com/crypto/innovat…

11
53
103
3,652
avery.apt 🇺🇸 retweeted
Jun 8
Aptos Labs joined @AvalanchePolicy, @Cardano_CF, @iota, @SuiFoundation, and @StellarOrg in a joint comment letter to @TheFCA on its proposed cryptoasset perimeter guidance — advocating for clear regulatory boundaries between infrastructure providers and financial intermediaries.

92
44
278
13,062
$5.5 trillion in tokenized assets by 2030. @Citi's base case—DTCC, NYSE, Nasdaq all converging on 24/7 blockchain rails.
@BlackRock, @FTI_US, and @apolloglobal have already launched funds onchain on Aptos.
The full stack for markets and machines is ready.

233
201
788
18,028
Jun 8
Too much groupthink on how to rapidly increase AI spend. Wrong focus. The only metric that matters is productivity.
Anyone can burn billions of tokens and blow the entire budget. Early agent adoption was the perfect example of wasted token usage with negligible outcomes (some even highly negative via funds lost or data deleted).
These past months we have focused on:
* Empowering people to accomplish 10x scope and productivity of what they could before
* Building productivity tools and exploring new AI applications
* Educating each other on model tradeoffs
A lot of my time at Meta on data infrastructure was invested in how to efficiently process data at scale. We were processing exabytes per day on hundreds of thousands of machines. Every meaningful efficiency gain was worth tens of millions and multiples more today with the explosion of compute & data.
AI is an exponential of data infra. Open-source models are a big part of cost / productivity optimization. For every AI app/tool I build, I can dynamically choose the model based on the need - e.g. haiku vs sonnet vs opus. Combining different frontier models with open-source options means an easy order-of-magnitude improvement in spend-to-outcome.
I believe that even more important than model quality will be the challenge of optimizing $/outcome over the next decade for every entity in the world. With AI spending in the trillions during the next few years, this is a multi-trillion-dollar problem to solve.
Jun 6

Your margin is my opportunity: AI version…
The biggest surprise of 2026 is that the capability gap between the best open-weight/source models and the best closed models has narrowed much faster than the pricing gap. The pricing gap remains enormous while the capability gap is quite narrow.
What does this means in practice?
For a company consuming 1 billion input tokens and 1 billion output tokens per month:
GPT-5.5 Pro: ~$105,000
Claude Opus 4.8: ~$30,000
DeepSeek V4 Pro: ~$5,220
DeepSeek R1: ~$2,740
I asked ChatGPT what it thought about this and it answered as follows:
“If I were building a company today, the economic frontier would look roughly like:
DeepSeek V4 Pro / R1 for high-volume inference.
Claude Opus for premium agent workflows where reliability matters.
GPT-5.5 Pro only for workloads where its incremental capability demonstrably produces enough business value to justify a 20–40× token premium.”
Most CEOs have no idea that, instead of this nuanced approach, their teams are running amok internally by picking the most expensive models in most cases and burning through massive budgets with zero governance, audit ability and control.
As control planes like our Software Factory become more standard, you can expect the run rate revenue growth of the frontier labs to go down meaningfully and the revenues of the open models to skyrocket.
Why? Because we can implement the nuanced approach above and be agnostic to model - instead focusing on customer intent, model task and cost management among other things.
13
9
55
2,588
avery.apt 🇺🇸 retweeted
Jun 3
Traders do not want another venue with the same five crypto pairs.
They want more markets.
Crypto. RWAs. Equity perps.
Decibel is building the fully onchain venue for all of it.
51
46
223
10,810
Jun 7
List already needs massive expansion…
• SEC-registered transfer agent, securities infrastructure on Aptos: @Vertalo_
• FINRA broker-dealer, institutional-grade tokenization on Aptos: @tZERO
• FCA-regulated exchange, 100 RWAs coming onchain: @ArchaxEx
• CFTC-regulated futures, first U.S. $APT futures contracts: @Bitnomial
One stack.

16
12
68
3,213
Jun 6
While market volatility affects us all, we've been focused on driving forward financial tokenization. The big debates are on the best methods of tokenization, but every asset manager knows that everything is coming to crypto rails and will trade globally. Their customers want it. Their partners want it. @DecibelTrade and @Aptos already onboard
BlackRock.
Franklin Templeton.
Apollo.
Private credit.
Tokenized equities.
QQQ and other ETFs.
Data centers.
Exotic assets (e.g., radioactive isotopes)
Carbon credits.
Institutional digital money and stablecoins.
Leveraged ETFs are a massive personal unlock (Perps > options in simplicity IMO). Let's look at this list again in a year.
32
26
124
7,625