
Working on Evolutionary AI
Joined March 2009
- Tweets 481
- Following 72
- Followers 678
- Likes 409
15 Photos and videos




May 22
Only 13% of leaders align AI ambitions with capabilities, $6T in value is at stake. Systems mastery & AI velocity gap execution are the winning formula. Here’s how to unlock operational outcomes & compounding systems value.
linkedin.com/pulse/ai-builde…
481
Babak Hodjat retweeted

Mar 17
What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
65
91
678
76,685
Babak Hodjat retweeted

13 Nov 2025
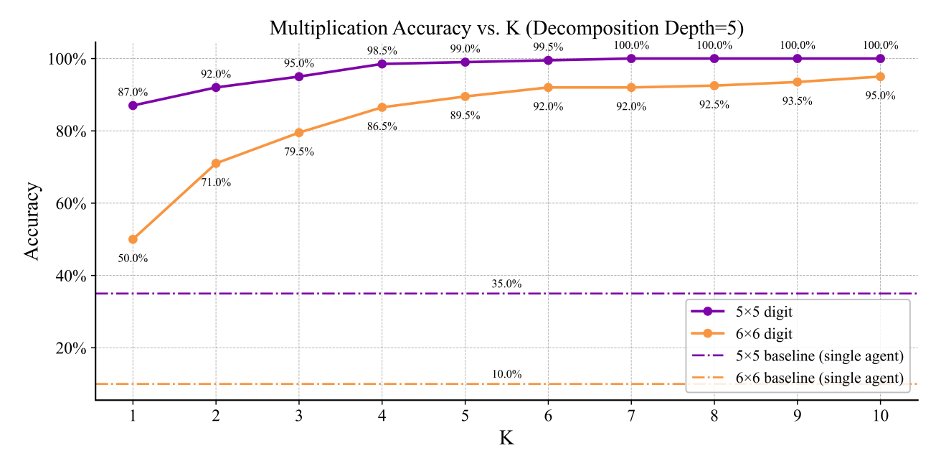
Second, as I mentioned earlier, right now this framework is limited to tasks where decomposition is provided. We are preliminarily testing generalized methods that preform both subtasks and task decomposition, and we are seeing promising results on boosting arithmetic abilities of small models as well – though it does appear decomposition may itself be a challenge orthogonal to task execution.
2
1
11
2,647
Babak Hodjat retweeted
13 Nov 2025
Our subtask breakdown was to provide an llm agent with the current Towers of Hanoi state and the last move made. The agent would then use first-to-ahead-by-k voting along with abnormal response flagging to decide what move it wanted to do and provide the board state for the next task. This does limit our framework to cleanly decomposable problems, which I’ll come back to at the end of the thread.
1
3
20
4,691
Babak Hodjat retweeted
13 Nov 2025
New work from Cognizant AI lab: Solving a Million-step LLM Task with Zero Errors.
Existing LLMs struggle on long task horizons as persistent error rates compound, even when the LLMs know how to solve the task. Apple’s “Illusion of thinking” demonstrated that state of the art reasoning models could struggle with a simple task, Towers of Hanoi, if that task required execution of hundreds of steps in a row without error.
We hypothesized we could see much higher performance by taking breaking down the task into its smallest subtasks, then using voting and red flagging to boost subtask accuracy.
With these simple modifications we were able to push the simple gpt-4.1-mini to solve the 20-disk towers of Hanoi, or 1,048,575 steps without a single error! Seeing these results we believe with the right, robust, frameworks, LLMs can be scaled to vastly longer task lengths than their base model.
Paper: arxiv.org/abs/2511.09030
Blog: cognizant.com/us/en/ai-lab/b…
20
109
711
135,073
Babak Hodjat retweeted

13 Nov 2025
LLMs hit a ceiling on long, complex reasoning. Tiny errors compound fast. @Cognizant AI Lab just showed a new path: MAKER, a multi-agent system that solved a 1,000,000-step reasoning task with zero errors.
tinyurl.com/2v47u665 #multiagentsystems #LLMs
2
3
389
Babak Hodjat retweeted

27 Oct 2025
Our recent ES fine-tuning paper (arxiv.org/pdf/2509.24372) received lots of attention from the community (Thanks to all!). To speed up the research in this new direction, we developed an accelerated implementation with 10X speed-up in total running time, by refactoring the infrastructure with faster inference engines. Kudos to @DibblaX !
You can find the accelerated version in our repo now: github.com/VsonicV/es-fine-t…. We are still working on the next version with better API designs, but we cannot wait to release this accelerated version, because we understand how expensive the GPU compute is for researchers and practitioners.
Feel free to leave any questions/concerns about the work here.

2
14
81
47,999
Babak Hodjat retweeted
10 Oct 2025
🧠 AGI: A Reality Check
As AGI hype grows (and billionaires build bunkers), we need grounded voices. Cognizant’s @babakatwork reminds us: “LLMs don’t have meta-cognition… they don’t know what they know.” bbc.com/news/articles/cly178…
1
2
64

discuss with author: huggingface.co/papers/2509.2…
2
9
5,608


Evolution Strategies can be applied at scale to fine-tune LLMs, and outperforms PPO and GRPO in many model settings!
Fantastic paper “Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning” by @yule_gan, Risto Miikkulainen and team.
arxiv.org/abs/2509.24372

Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: arxiv.org/pdf/2509.24372
Code: github.com/VsonicV/es-fine-t…
10
35
275
35,217

To recap — ES can outperform RL for LLM fine-tuning.
No gradients. No reward hacking. Just stability, efficiency, and scalability.
ES shows low variance across seeds, minimal hyperparameter sensitivity, and strong reward–KL tradeoffs — all without actor-critic complexity.
Beyond results, ES offers a simpler, gradient-free path for post-training.
From reasoning and exploration to safety alignment and continual learning, it scales reliably where RL often breaks.
As models grow in size and importance, stability and robustness will matter as much as raw performance.
ES could be the future of fine-tuning — a cleaner, more reliable way to shape intelligence. 🚀
3
80
10,816
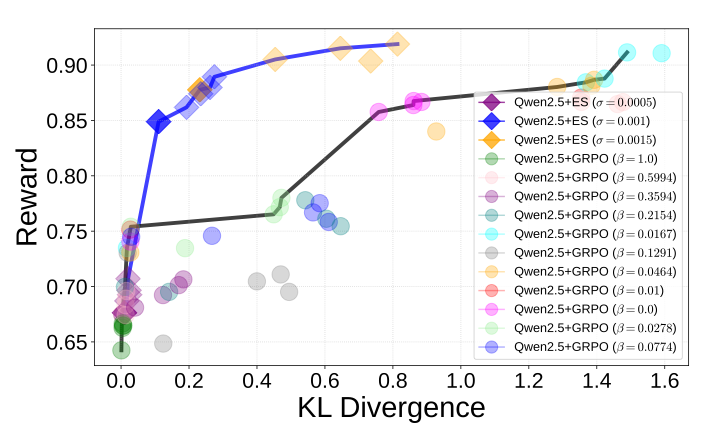
Another key advantage of ES fine-tuning is its reliability.
It runs stably across seeds, barely depends on hyperparameters, and avoids reward hacking — all while skipping gradients and actor-critic setups.
In the figure, you can see ES finds a much better reward–KL balance than GRPO, reaching higher rewards even without KL constraints — indicating a fundamentally different fine-tuning trajectory.
1
3
72
8,723
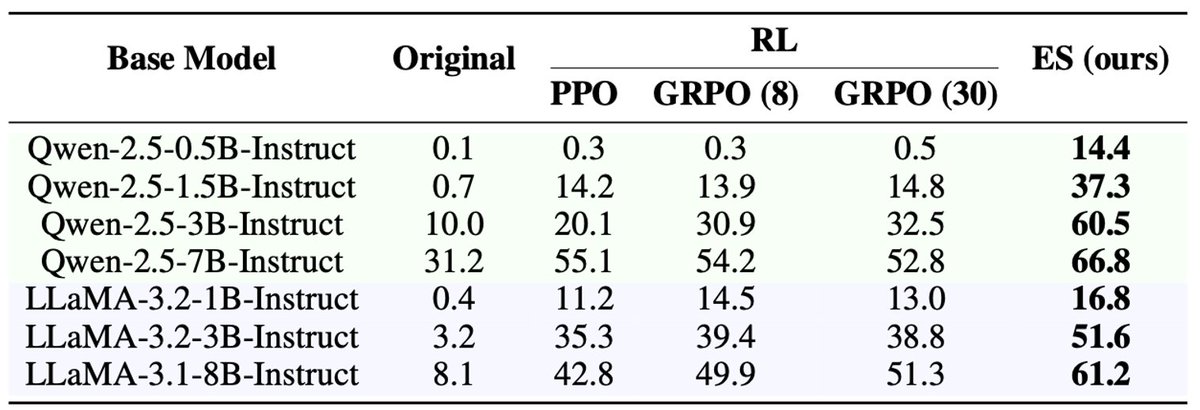
On the symbolic-reasoning Countdown task, ES beats PPO/GRPO across Qwen-2.5 (0.5B–7B) & Llama-3 (1B–8B) with huge gains.
Moreover, as shown in TinyZero by @jiayi_pirate and DeepSeek-R1, RL fails on small models like Qwen-0.5B — yet ES succeeds! 🚀
1
4
70
9,397
As noted in DeepSeek-R1 and other studies, RL fine-tuning has several limitations, including challenges with long-horizon and outcome-only rewards, low sample efficiency, high-variance credit assignment, instability, and reward hacking.
ES sidesteps these issues: it perturbs parameters (not actions), evaluates full rollouts, and averages over populations, thereby achieving stable, gradient-free, and reward-hacking-resistant optimization that is also easy to parallelize.

4
7
84
11,728
Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: arxiv.org/pdf/2509.24372
Code: github.com/VsonicV/es-fine-t…
90
383
2,605
414,932
Babak Hodjat retweeted

6 Oct 2025
Nice to see an exploration of the potential for ES (evolution strategies) in LLM fine tuning! Many potential advantages are discussed in this thread from @yule_gan .
Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: arxiv.org/pdf/2509.24372
Code: github.com/VsonicV/es-fine-t…
4
15
143
13,930
Babak Hodjat retweeted

19 May 2025
.@babakatwork explains why #DeepSeek isn’t the Sputnik moment it’s hyped up to be, but instead an important accelerator for enterprise #AI adoption.
Read the full article here on @Techzine ➡️ bit.ly/44Faih2
2
3
179
Babak Hodjat retweeted

23 May 2025
New article!
Discovering effective policies for land-use planning with neuroevolution
👉 bit.ly/3ZoUBHf
By Daniel Young, Olivier Francon, Elliot Meyerson, Clemens Schwingshackl, @JacobBieker, Hugo Cunha,
@babakatwork & Risto Miikkulainen
@OpenClimateFix @Cognizant

1
1
229