
Research Scientist at @CognizantAILab. Prev: PhD in Semiconductor Data Analytics at UT Operations Research.
Joined August 2013
- Tweets 59
- Following 1,696
- Followers 347
- Likes 70,512
11 Photos and videos





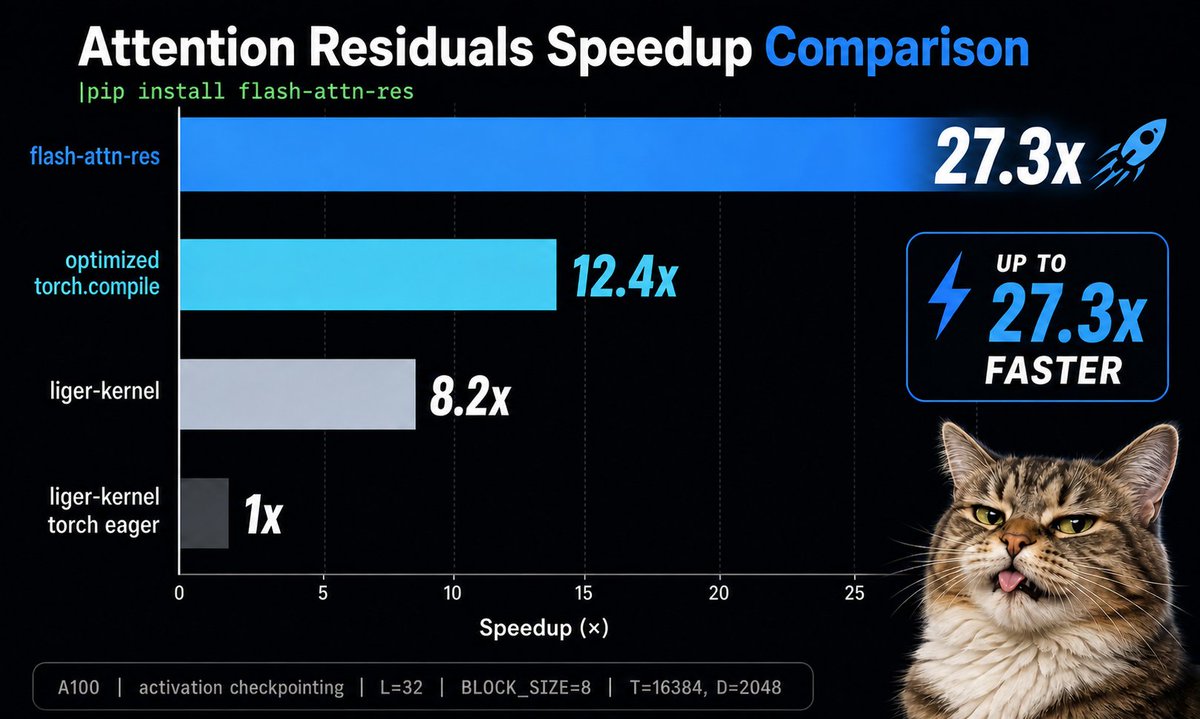
27x faster Attention Residuals!!! 🚀
We implemented Block AttnRes as a pip-installable package.
!pip install flash-attn-res
No annoying kernel nonsense.
No compile/autograd plumbing.
Call it like a regular PyTorch op.
It just works.
Methodology:
🔹 fused triton kernels
🔹 batched attention over residual blocks
🔹 online-softmax merge
🔹 flash attention-style split-KV reduction
Thanks @LLMenjoyer and @cartesia for the support and guidance✌️
Mar 16

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…

23
83
776
75,947

Apr 28
Really cool video breakdown of our work and others for evolution strategies on LLM's: youtube.com/watch?v=lLkE9w1N…
1
117
Mar 18
Really cool work from my colleague @_GPaolo on open-ended multi-agent environments. He creates a resource-constrained grid world for ai agents where they can interact, search for resources, and leave persistent text artifacts for each other. Without direction you can see the emergence of rules, division of labor, and even attempted governance! The code is up to try out yourself here: github.com/cognizant-ai-lab/…
Mar 17

What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
1
6
367
Feb 25
Cognizant AI lab @cognizantailab is out with new work in gradient-free fine-tuning with Evolution Strategies (ES)! We expand our initial paper with larger models (7B) and math reasoning to demonstrate ES works out of the box and is competitive with RL across broad domains, without the engineering overhead of gradient-based RL methods. arxiv.org/abs/2509.24372 alphaxiv.org/abs/2509.24372v…
Inspired by the success of ES we have also pushed ES research in three new directions. First, we put ES to use in a task standard gradient-based RL can’t reach: successfully fine-tuning LLM’s directly in quantized space with Quantized Evolution Strategies (QES). arxiv.org/abs/2602.03120 alphaxiv.org/abs/2602.03120
Next, we looked at developing a theoretical intuition as to why we can succeed in fine-tuning multi-billion parameter models with population sizes as low as 30 in “Blessing of Dimensionality in LLM Fine-tuning” arxiv.org/abs/2602.00170 alphaxiv.org/abs/2602.00170
Lastly, we use ES to help teach models to know what they know, using ES to fine-tune models in a metacognitive task. arxiv.org/abs/2602.02605 alphaxiv.org/abs/2602.02605
We’ve just released a blog describing the overall effort here: cgnz.at/6005QZNMb
13
79
5,001
Feb 22
Our lab was able to run 20-disk towers of Hanoi (~1 million steps) on gpt-4.1 mini by simply observing per-step error rates and adding appropriate error checking. I think people should no longer be citing the Illusion of Thinking paper as a fundamental limitation of LLM's. x.com/RobertoDailey1/status/…
14
1,751
Roberto Dailey retweeted

Feb 14
We recently released a new version of our Evolution Strategies (ES) fine-tuning paper, with more benchmarks, baselines and discussions, strengthening the foundation for using ES as a propagation-free post-training paradigm. (arXiv: arxiv.org/abs/2509.24372, alphaXiv: alphaxiv.org/abs/2509.24372v…)
We also released three intriguing follow-up works on this new direction:
(1) Quantized Evolution Strategies (QES) extends ES to post-training of quantized LLMs. With a frugal memory usage at low-precision inference level, QES achieves a high-precision optimization trajectory in quantized parameter space. (arXiv: arxiv.org/abs/2602.03120, alphaXiv: alphaxiv.org/abs/2602.03120)
(2) The "Blessing of Dimensionality" paper tries to explain why ES only needs a population size of ~30 to fine-tune billions of parameters. It discovers that larger models may have lower intrinsic dimensionality, which makes parameter-space search in ES easier. (arXiv: arxiv.org/abs/2602.00170, alphaXiv: alphaxiv.org/abs/2602.00170)
(3) Evolution Strategy for Metacognitive Alignment (ESMA)" uses ES to fine-tune LLMs to know what they know. That is, using alignment between "whether LLM answers one question correctly" and "whether LLM knows it can answer one question correctly" as the objective of fine-tuning, strengthening the metacognitive alignment of LLMs. (arXiv: arxiv.org/abs/2602.02605, alphaXiv: alphaxiv.org/abs/2602.02605)
Looking forward to adding more to this ES ecosystem!

1
14
53
5,054
Roberto Dailey retweeted

15 Nov 2025
i love this paper.
while on the surface it looks like this is just task decomposition and self-consistency using ensembles, i want to highlight other things.
this paper picks what most of us intuitively feel about or try with LLMs, but drop after trying it in a simple manner.
13 Nov 2025

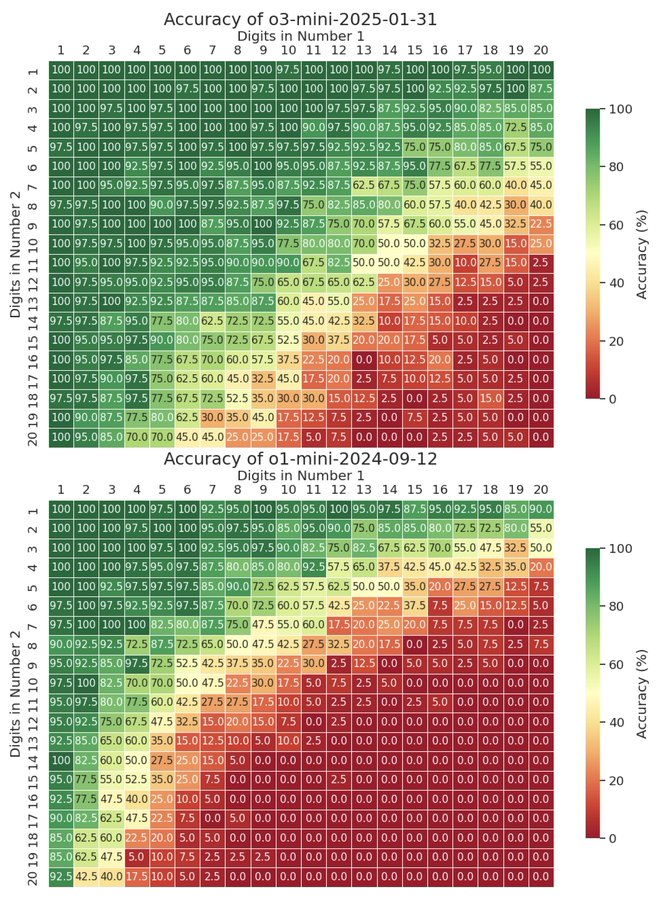
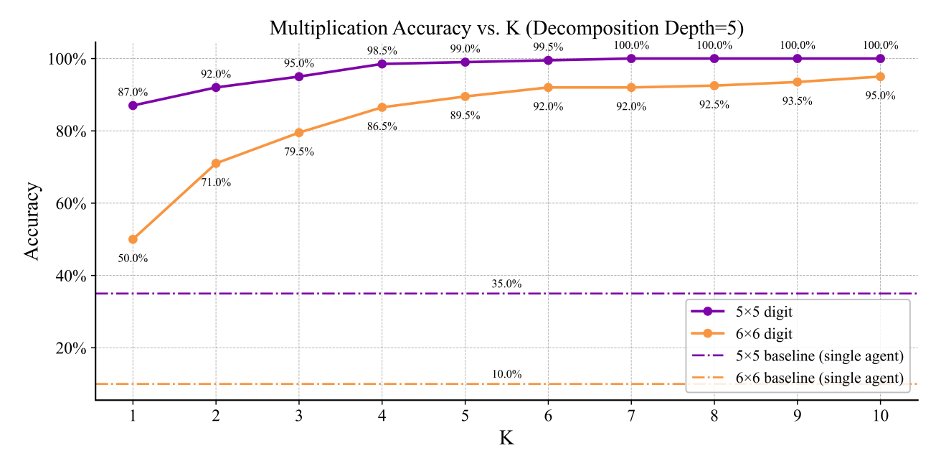
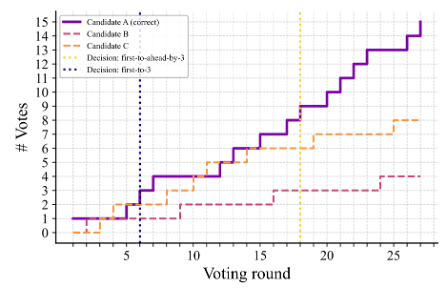
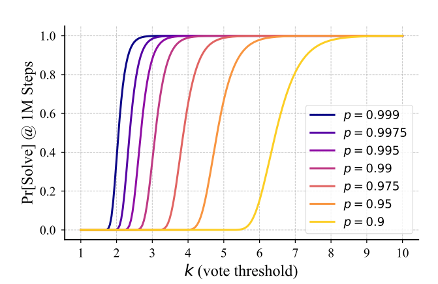
New work from Cognizant AI lab: Solving a Million-step LLM Task with Zero Errors.
Existing LLMs struggle on long task horizons as persistent error rates compound, even when the LLMs know how to solve the task. Apple’s “Illusion of thinking” demonstrated that state of the art reasoning models could struggle with a simple task, Towers of Hanoi, if that task required execution of hundreds of steps in a row without error.
We hypothesized we could see much higher performance by taking breaking down the task into its smallest subtasks, then using voting and red flagging to boost subtask accuracy.
With these simple modifications we were able to push the simple gpt-4.1-mini to solve the 20-disk towers of Hanoi, or 1,048,575 steps without a single error! Seeing these results we believe with the right, robust, frameworks, LLMs can be scaled to vastly longer task lengths than their base model.
Paper: arxiv.org/abs/2511.09030
Blog: cognizant.com/us/en/ai-lab/b…
6
14
170
24,891
13 Nov 2025
New work from Cognizant AI lab: Solving a Million-step LLM Task with Zero Errors.
Existing LLMs struggle on long task horizons as persistent error rates compound, even when the LLMs know how to solve the task. Apple’s “Illusion of thinking” demonstrated that state of the art reasoning models could struggle with a simple task, Towers of Hanoi, if that task required execution of hundreds of steps in a row without error.
We hypothesized we could see much higher performance by taking breaking down the task into its smallest subtasks, then using voting and red flagging to boost subtask accuracy.
With these simple modifications we were able to push the simple gpt-4.1-mini to solve the 20-disk towers of Hanoi, or 1,048,575 steps without a single error! Seeing these results we believe with the right, robust, frameworks, LLMs can be scaled to vastly longer task lengths than their base model.
Paper: arxiv.org/abs/2511.09030
Blog: cognizant.com/us/en/ai-lab/b…
20
109
711
135,076
13 Nov 2025
Overall, my main takeaway for this project was that breaking down a task, and providing only the necessary context to an agent can lead to enormous task length scaling gains. When Elliot described this project to me I really didn’t expect the LLM framework to hold up along the expected scaling from voting, but then it did and here we have 1 million sequences completed correctly in a row by gpt-4.1-mini. I think as people look towards evaluations like @METR_Evals time horizon, we shouldn’t be surprised if in narrow enough domains scaffolding will extend task horizons well beyond the base models they use.
1
1
14
2,020
13 Nov 2025
Lastly big thanks to Elliot for bringing me on the project, as well as the rest of the team working on the paper Giuseppe, Hormoz, Olivier,
@conorfhayes, @realVsonicV, @babakatwork , and Risto.
1
1
9
1,841
29 Sep 2025
New paper from my UT group on stochastic control in photolithography when down selecting the number of measurement markers: sciencedirect.com/science/ar…
296