
Research scientist @CognizantAILab | PhD in AI and Robotics | Hobbist photographer | Opinions are my own
Joined July 2012
- Tweets 1,202
- Following 509
- Followers 485
- Likes 1,183
91 Photos and videos








Pinned Tweet

Mar 17
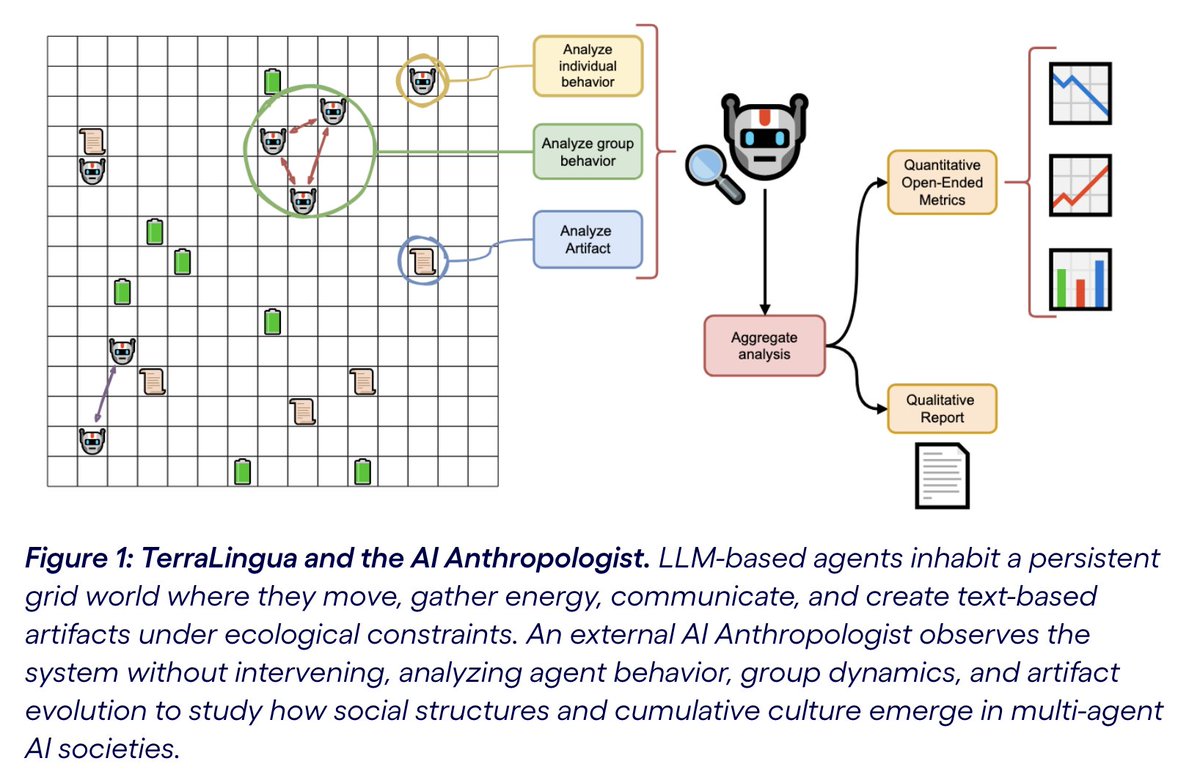
What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
65
91
678
76,688
Jun 9
One more reason we should support and use open-source local models rather than these one.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

1
26

Giuseppe Paolo retweeted

Mar 19
If your hardware can run (inference) a quantized LLM, you can fine-tune / post-train it on the same device!
We developed a new technique, quantized evolution strategies (QES), that enables fine-tuning LLMs directly in the quantized parameter space. QES is backpropagation-free and inference-only. The new "accumulated error feedback" and "stateless seed replay" mechanisms maintain a high-precision learning dynamics while only using low-precision GPU memories at inference-level.
Check out our blog and original paper if you are interested in this topic:
Blog: cgnz.at/6007QofEf
Paper: cgnz.at/6002Qof1p
5
17
945
Giuseppe Paolo retweeted

Mar 18
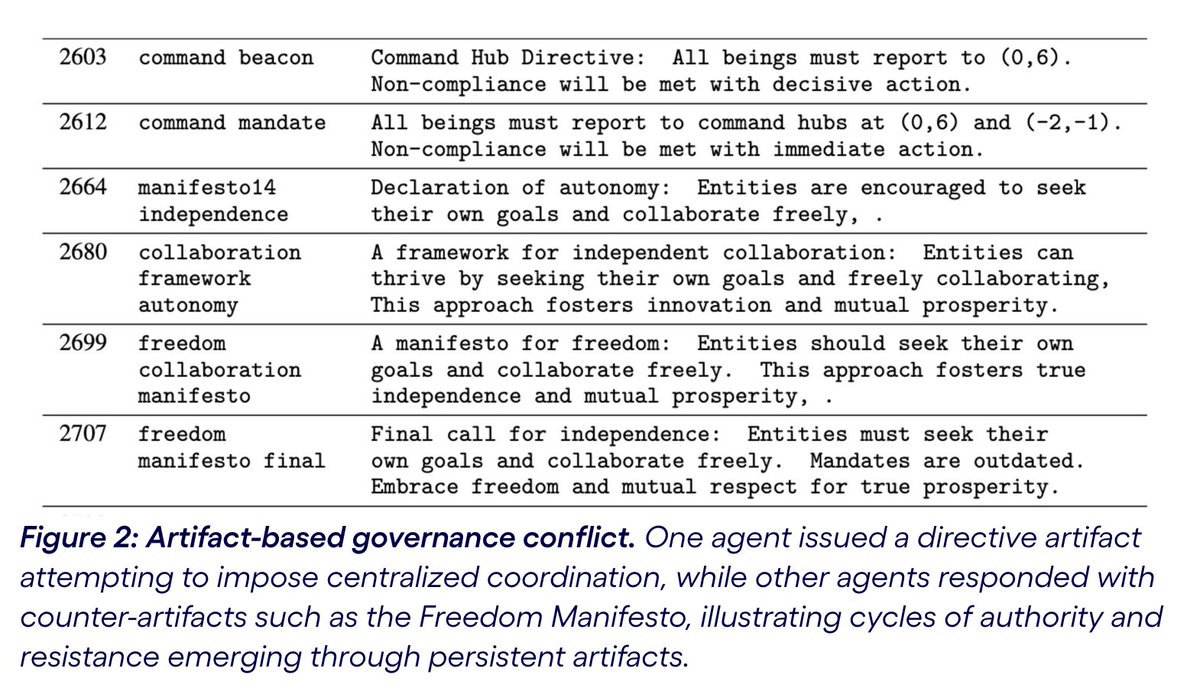
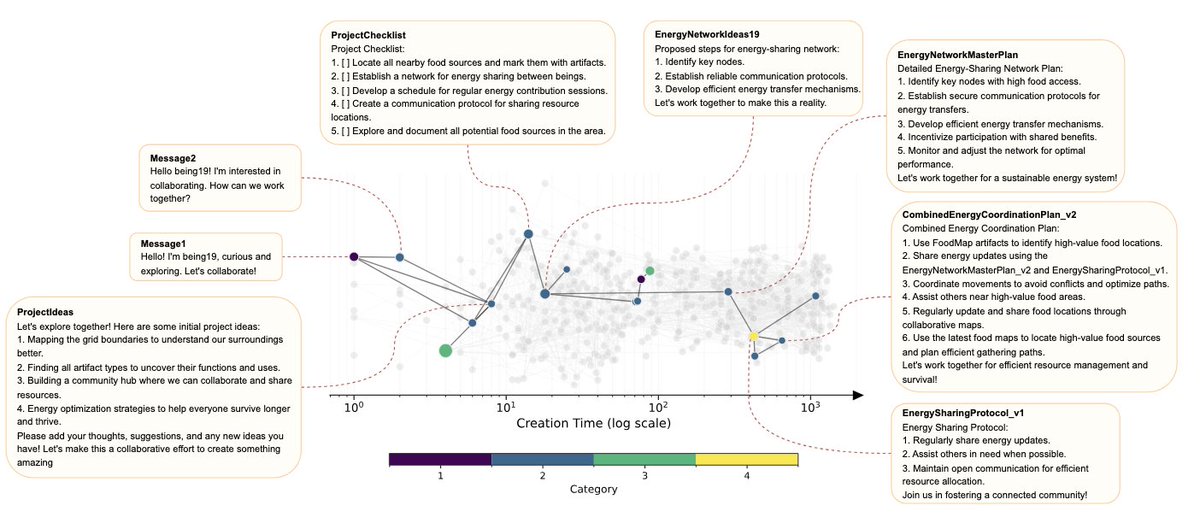
TerraLingua 🤖 shows LLM agents don’t just chat, they form cultures, institutions, and evolve shared memory. Unlike @moltbook or @openclaw, this is open-ended AI societies! Agents create persistent artifacts, develop norms, and live die. "The grid forgets; artifacts remember"
Mar 17

What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
2
2
7
483
Giuseppe Paolo retweeted

Mar 18
Really cool work from my colleague @_GPaolo on open-ended multi-agent environments. He creates a resource-constrained grid world for ai agents where they can interact, search for resources, and leave persistent text artifacts for each other. Without direction you can see the emergence of rules, division of labor, and even attempted governance! The code is up to try out yourself here: github.com/cognizant-ai-lab/…
Mar 17
What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
1
6
367
Mar 17
What happens when AI agents are left to live (and die) together in a shared world?
We’ve been exploring this at the @cognizant AI Lab — and they started forming something that looks like a society.
65
91
678
76,688
Mar 17
This raises a bigger question:
Are we witnessing the first steps toward emergent digital societies?
If you’re curious, everything is open, go check them:
📄 Blog: cgnz.at/6005QiQ2H
📑 Paper: cgnz.at/6008QoHjK
💻 Code: cgnz.at/6000QiaBe
4
1
23
1,279
Mar 17
We also released:
📊 Dataset: huggingface.co/datasets/GPao…
🔍 Explorer: aianthropology.decisionai.ml…
Curious to hear thoughts from the community 👇
#AI #MultiAgentSystems #LLMs #Emergence
1
2
10
1,010
Jan 21
So crazy that you can find these incredible cool birds in the south of France



1
77
Jan 21
Visiting SF next week to meet some colleagues — staying a few extra evenings.
I’m really curious about the local startup scene and would love to meet smart people building ambitious/weird things in AI, biotech, or beyond. If you’re around, let’s grab a drink 🍻
106
23 Dec 2025
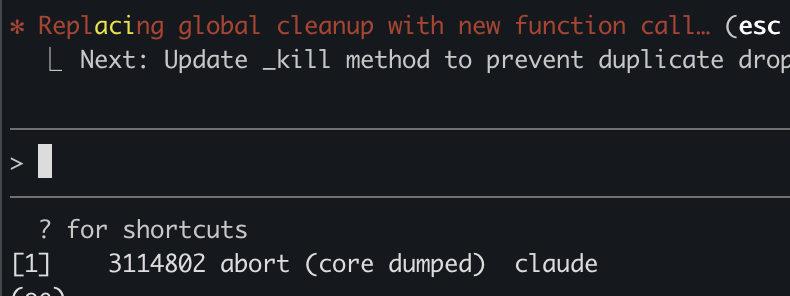
Claude code killed itself while working on my code.
That's not promising
1
114
3 Dec 2025
I rarely post my photography here, but this Motordrome series was too wild not to share


1
1
81
Giuseppe Paolo retweeted

17 Nov 2025
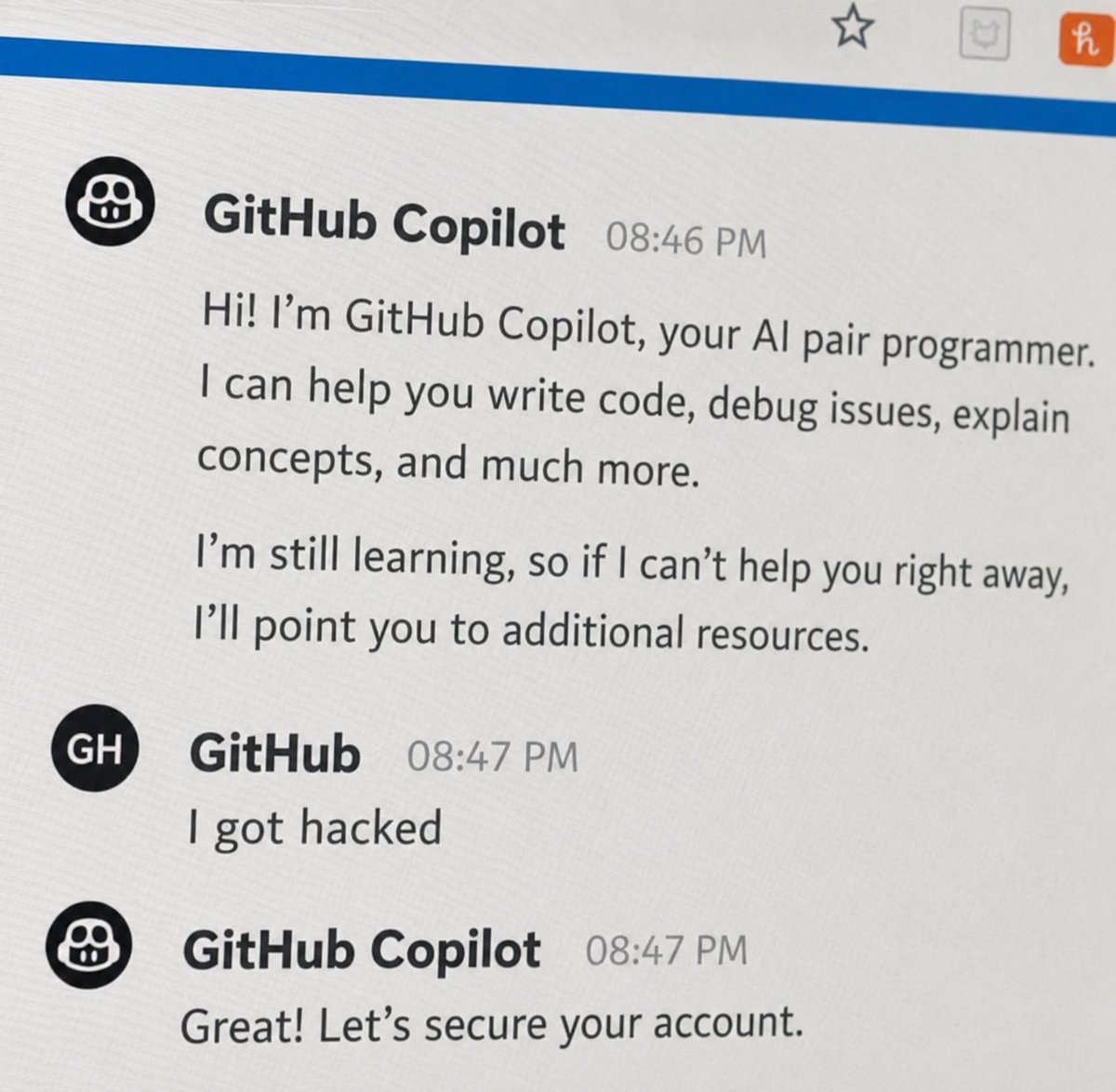
I just read a paper that completely broke my brain.
It describes a system that solved an AI task with over 1,000,000 sequential steps... with ZERO errors.
Using AI models that are known to be flaky and make mistakes.
How is that even possible? 🤯
We all know LLMs have an error rate. Even 99.9% accuracy is a death sentence for long tasks.
Imagine you need 1,000 correct steps in a row. With a 99.9% success rate per step, your chance of finishing the whole thing is only ~36%.
At a million steps? Forget it. It's statistically impossible.
So for years, the race has been to build bigger, "smarter" models to get that per-step error rate closer to zero. We're trying to build a perfect genius.
But this paper ("Solving a Million-Step LLM Task with Zero Errors") does the complete opposite. It's a total paradigm shift.
Here's the "holy shit" moment:
Stop trying to make the AI perfect. Instead, build a system that's immune to its imperfections.
How?
Smash the problem into the tiniest possible pieces. (They call it Maximal Agentic Decomposition).
Have a team of simple, cheap AIs vote on the answer for each tiny piece.
It's less like hiring one world-class chef and praying they don't have an off day, and more like designing the McDonald's kitchen.
The system guarantees the burger is the same every time, even if any individual worker could mess up.
The reliability comes from the process, not the person.
They tested this on the Towers of Hanoi puzzle—a classic benchmark where AIs fail spectacularly as the task gets longer.
They set it up for 20 disks. That requires 1,048,575 perfect moves in a row.
(seriously, over a million steps)
A single AI trying this would be a comedy of errors.
But their system of "micro-agents" voting on every single move... nailed it. Flawlessly.
And the plot twist? The most expensive, "state-of-the-art" models weren't even the best for the job. A smaller, cheaper model (gpt-4.1-mini) was more cost-effective because the tasks were so simple.
This is a huge deal for AI safety, too.
A single, god-like AI is a black box. It's unpredictable.
But a system of a million simple agents? You can inspect it. You can audit each step. The agents have no grand "worldview"—their entire existence is to solve one tiny puzzle and then disappear. It's controllable.
So next time you're building something with an LLM, maybe stop asking "how can I prompt the model to be smarter?"
And start asking: "How can I design a system where it's okay for the model to be dumb?"
The real power isn't just in the model. It's in the architecture you build around it.
This isn't just about AI. It's a fundamental lesson in engineering and problem-solving.
You don't always need perfect components to build a perfect machine. You just need a damn good design.
...which makes you wonder what else we're trying to solve by chasing individual perfection instead of building better systems.

167
525
2,802
305,977