
Builder, Dev, & Founder @Blockcircle @FirmAdaptAI @BetterEnrichX @SkillfulSH @FaithScreener | Ex Director of Engineering & AI @AmericanExpress |@Cornell MBA/MSc
Joined July 2010
- Tweets 2,481
- Following 5,360
- Followers 34,660
- Likes 24,288
413 Photos and videos










Pinned Tweet

Apr 2
URGENT PSA - New supply chain attack vector that I found WILD > AI LLMs hallucinate package names roughly 18-21% of the time.
Hackers have started pre-registering those hallucinated names on PyPI and npm with malicious payloads; they call it "slopsquatting"
You can only imagine what's next
Community note
The 'slopsquatting' attack vector was documented as early as April 2025 and not newly discovered. The cited 18-21% package hallucination rate applies to open-source LLMs; commercial models average 5.2% according to the referenced study using pre-2025 models. socket.dev/blog/slopsquat… arxiv.org/pdf/2406.10279
65
191
1,593
574,808
Basel Ismail retweeted

May 29
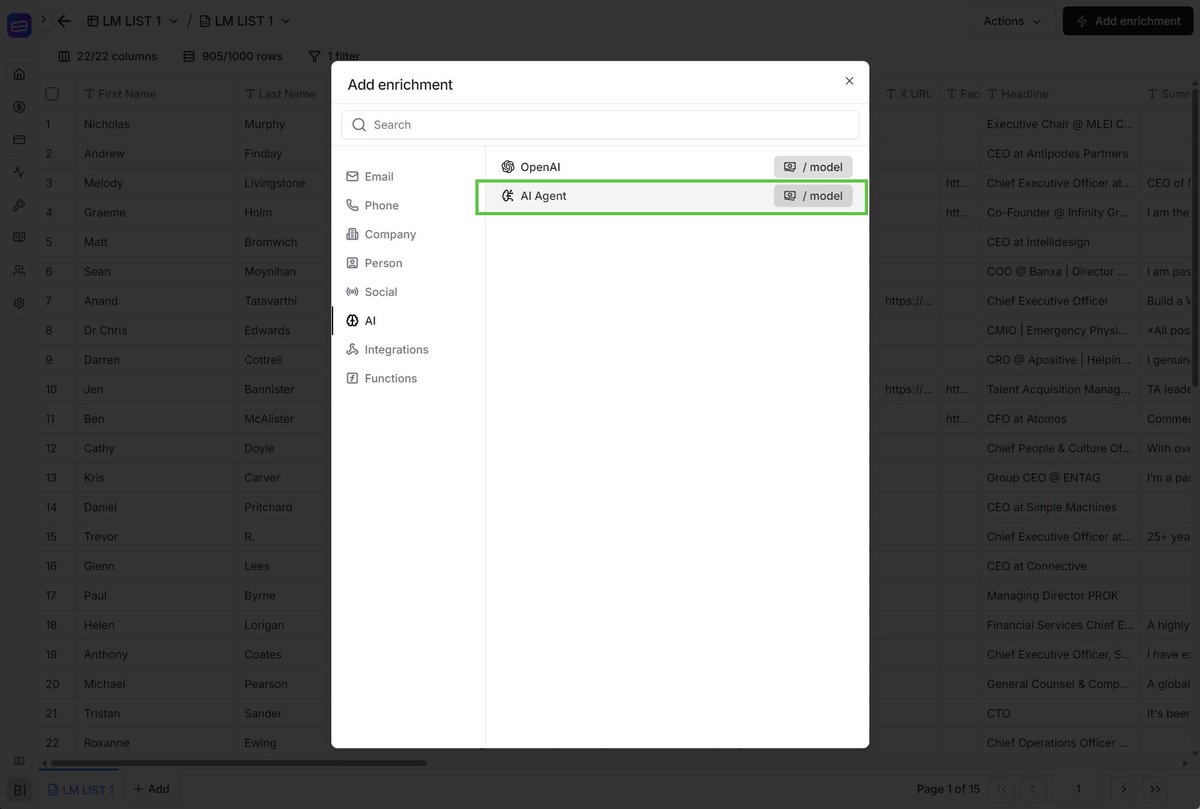
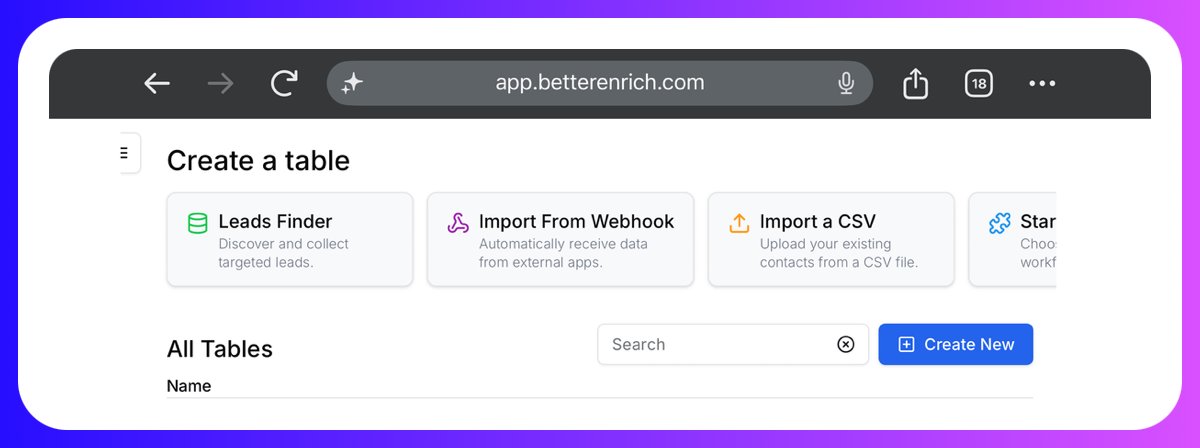
Most enrichment tools give you one entry point and call it a day.
BetterEnrich opens with four:
> 1) Leads Finder for discovering net-new contacts inside the platform.
> 2) Import a CSV for the list already sitting in a folder. > 3) Import from Webhook for piping leads in from forms, Zapier, or any external app automatically.
> 4) Start from template for the prebuilt workflows.
You can use whichever matches your needs and your style
1
1
292
Basel Ismail retweeted
Jun 6
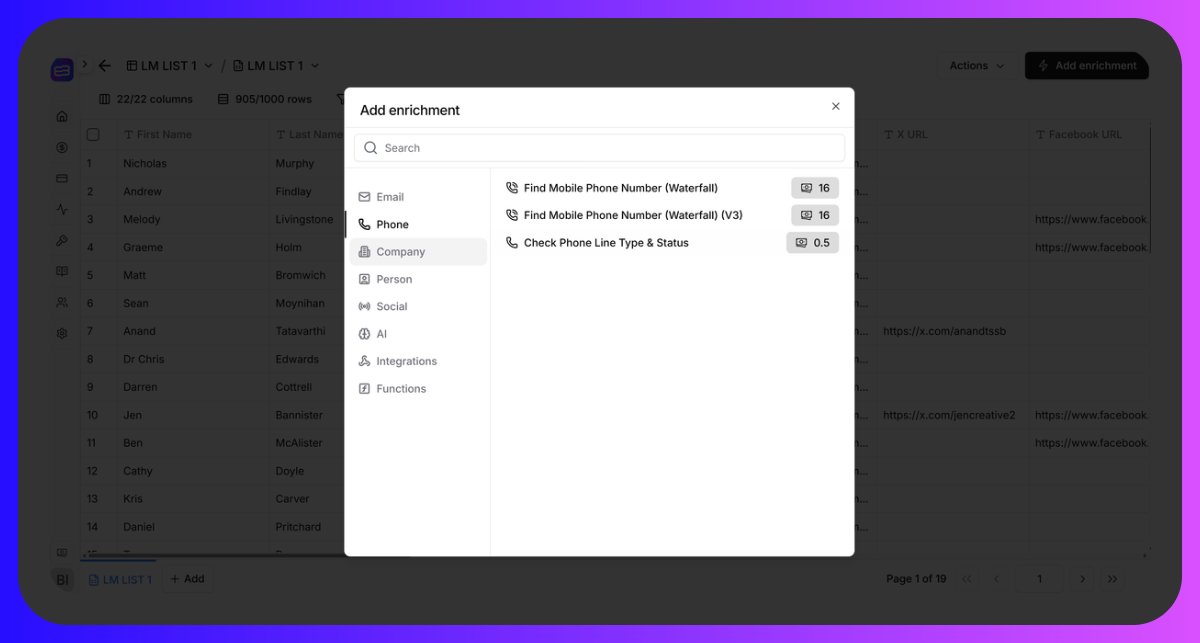
Most cold callers burn their dial time on landlines without realizing it.
BetterEnrich has a Check Phone Line Type & Status enrichment that costs practically nothing per number. Half a credit to know if the number is mobile, landline, or disconnected before your team ever picks up the phone.
Run it across the whole list before dialing. Most lists shrink by 30 to 40% and the connect rate on what's left jumps hard.
1
1
296
Basel Ismail retweeted
Jun 12
Finding leads, enriching them, and closing them usually means three separate tools stitched together.
BetterEnrich runs the entire motion in a single workspace.
You find leads > run the waterfall across 20 data providers > route with an AI agent (for maximum differentiation!) > then sync the verified rows straight into HubSpot, Salesforce, Clay, Instantly, and Smartlead.
One bill, and you only pay on verified hits.
1
1
235
Basel Ismail retweeted

Jun 12
The reason the same stock can be halal under one Shariah standard and fail another usually comes down to a single word in the formula, the denominator.
AAOIFI measures debt against trailing market cap. Dow Jones uses a 24-month average, S&P a 36-month average, and FTSE Yasaar and MSCI Islamic switch to total assets entirely.
All five are on one page at faithscreener.com/frameworks
1
1
272
Jun 11
I keep having the same thought when building new features and it's that text optimization itself is becoming more sample-efficient than weight optimization
Basically, we can propose multiple ideas in text and then test them against new evidence to learn from a single experience, this is really interesting when you don't have much textual data to work with.
1
3
884
Jun 11
We treat prompts, memory, retrieval, and agent wiring as plumbing, but the argument here is that they're a legitimate optimization layer, functionally doing the same job as weight updates.
The sample efficiency point is what interests me, because it has such a meaningful impact and that is what @yoonholeee is researching @MIT
2
724
Jun 11
A system can reread its own failed trajectory, diagnose what went wrong, propose a text-level patch, and test it before committing.
Stochastic Gradient Descent (SGD) just commits every update with no way to fork and compare, this is the fundamental limitation with this model
1
155
Jun 11
When I build agents, the harness and context design consistently matters more than which model I pick.
146
Jun 10
This was a very interesting thread on the implications of large-scale test time computational tasks
TLDR > benchmark scores are basically losing their meaning because model capability isn't a fixed number as much as before.
It scales with how much compute you let it use at inference, and that's more confusing to track
2
1
3
877
Jun 10
Related wild stat I read in a paper a while back: in FLOPs-matched comparisons, smaller models with heavy test-time compute can outperform models up to 14x larger, especially on coding and math where you can verify outputs. This is the original research: arxiv.org/abs/2408.03314
1
1
192
Jun 10
I keep wondering whether the right abstraction for products is exposing that thinking budget to users somehow, which is what most are beginning to do, or is it better to keep it invisible, but the risk with the latter is that credits get burned faster
174
Basel Ismail retweeted

Jun 4
You can run a real diagnostic report on any company, and the only thing you have to type in is its website.
It sounds too simple, but the website is the unique identifier for everything tied to a business, so it's all the tool needs to get going.
In the video, @BaselIsmail analyzes one of the world's largest privately held companies to demonstrate the depth of the report.
Before it runs anything, it asks what you actually want to focus on. A 200-page report usually buries the value, so we customize ours for you.
So you can highlight the issues you want help with and the insights your business needs. The team is stretched thin, revenue has plateaued, AI is on the radar, but nobody knows where to start.
You can select the areas that are applicable to you!
2
1
1
382
Basel Ismail retweeted

Truly believe @BaselIsmail is cooking up something revolutionary for @Blockcircle right now
Can't wait to share more details🤞🏼
1
2
5
1,377
Jun 1
I just ran a controlled experiment to quickly gauge the efficacy of off the shelf AI, and here is the result 💀
I was seeing this test and I’m surprised that on June 1, 2026, this is where we are at, we are still very, very early
1
4
360
Basel Ismail retweeted

May 29
If you want to quickly determine whether or not a publicly traded company is overvalued / undervalued / fairly valued using 6 different valuation methods…
Then you should try the Company Valuation Engine!
You can see the scoring for every listed name on fundamentals, technicals, and sentiment, then showing one composite verdict per company.
The whole board sorts and filters by index, country, and sector.
1
2
5
1,906