
Inference is everything.
Joined March 2021
- Tweets 2,407
- Following 348
- Followers 10,939
- Likes 4,876
655 Photos and videos














Intelligence should be defined by the people closest to the work. Intelligence should be owned by all of us.
Let’s build a many model future!

3
3
27
12,495
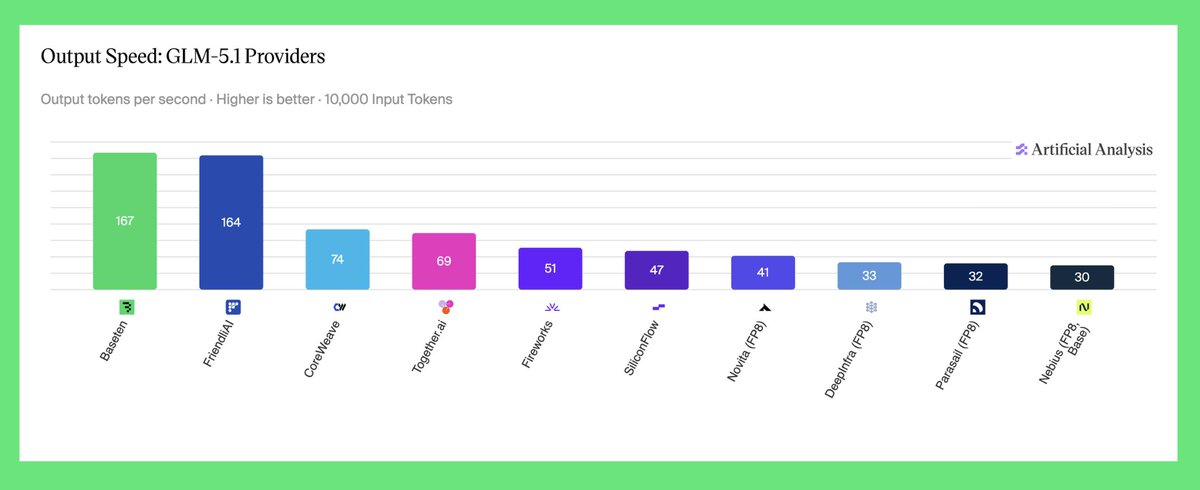
The new AgentPerf benchmark by @ArtificialAnlys shows that @NVIDIAAI Blackwell delivers best performance for demanding agentic workloads. With NVIDIA, we're continuously investing in making your coding agents run fast, scale seamlessly, and cost less.
blogs.nvidia.com/blog/nvidia…
6
704
We're thrilled to be working with the Harvey team to push open models to frontier-level performance for legal AI.
Shout out to @gabepereyra for the great article. LAB was key to our joint work post-training open-weight models for legal agents.

3
2
19
1,914
Congrats to the MiniMax team on the open-source launch of M3!
There are very few <500bn parameter models that can tackle coding, agentic workloads, and multimodal all with a 1M-token context window but M3 does it all.
Dig in here: baseten.co/library/minimax-m…
5
3
40
20,225
Join Baseten, Lovable, and ElevenLabs to hack on the future of healthcare.
Jun 12

Most AI demos built for healthcare don't survive in real clinical or operational environments.
The data is messy, the workflows are fragmented, margin for error is near zero.
That's why I'm stoked to host a 1.5-day Healthcare x AI Hackathon with @HealthcareAIGuy in NYC: a small group of engineers, founders, PMs, and builders who are serious about applying AI agents and tools to healthcare problems in production.
Stack: @Baseten, @Lovable, @ElevenLabs
Cash prizes. And a few surprises.
📍 NYC | June 26–27
Space is limited and application-based.
Apply by June 17th at 11:59 pm ET → link below

2
9
670
We've heard from customers that they ship model updates >50% more often with rolling deploys than their previous solutions.
No downtime, parallel GPU fleet, or off-hours babysitting. Rolling deploys are autoscaling-aware, and you can pause, inspect, or roll back at any step.

3
1
21
3,208
Great to see @Baseten’s own @oneill_c and @part_harry_ sitting down with @cursor_ai’s @sjwhitmore to talk about the many things their 128(!) agents are doing (and occasionally arguing about), compaction, and the future.
Jun 11

We're trying a new experiment at @cursor_ai - interviewing devs we admire.
I chatted with @oneill_c & @part_harry_ from @baseten about how they use coding agents. We discussed their current dev workflows & some predictions for the future.
Check it out below!
3
1
17
2,456
We are excited to announce that we have partnered with @_inception_ai to make Mercury 2 available on Baseten. This makes us the first inference platform to bring Inception’s diffusion LLM to production.
Inception’s dLLM architecture fixes the bottlenecks of sequential token generation and can deliver 1,000 tokens/sec on standard NVIDIA GPUs. Early users like @augmentcode have seen impressive results, such as an 82% reduction in latency and 90% cost savings, while maintaining high quality.

3
5
47
22,763
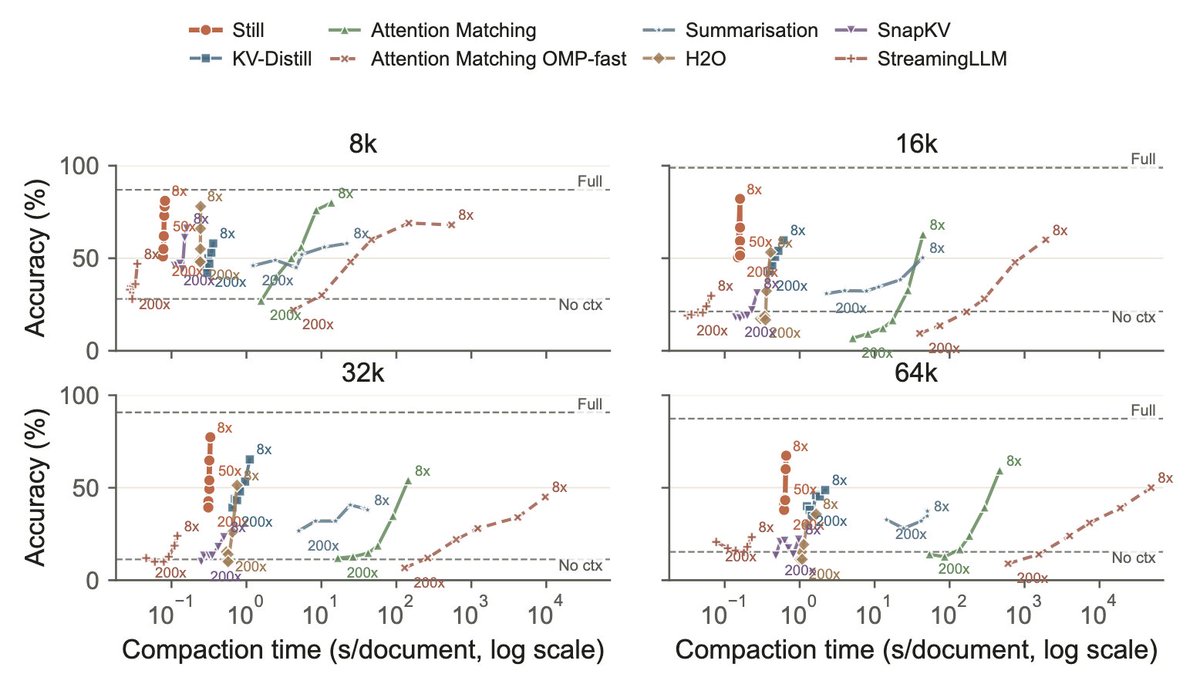
The longer the context, the more memory your LLM needs. We introduce research techniques to compress that memory 200x on the fly without changing the base model.
Jun 10

1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly.
At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model.
Here's how we did it 👇
5
40
3,486
Baseten retweeted

Jun 8
Model selection isn't just a fancy term for "looking at benchmarks". If you're just auto-updating and going off twitter vibes, you're not really adding any value to your business or your customers. To do this well, it means you need to deeply understand your use cases, how much value your customers ascribe to a problem, how much margin you want to make on that product, and how much time you want to invest into growing that margin. Came here me rant more on June 25 luma.com/65l844l9?utm_campai…
Jun 8
Working in the Training team at Baseten, I often see companies agonize over which model to use. So many people worry about how to keep up with benchmarks and new releases
But with post-training and specialization, and as we see a rising tide in the intelligence of many open-source models, what really matters is your learning signal. Do you have the right user metrics to say whether a model is doing poorly or well at your task, and to use that to learn and hillclimb the task?
If you want to learn more, I’m moderating a panel on June 25th in SF at 6 PM with Gamma co-founder Jon Noronha (@thatsjonsense) and Notion AI lead Sarah Sachs (@sarahmsachs) on model selection in a multi-model landscape.
1
2
24
2,381
Join Charlie for a conversation with @thatsjonsense
and @sarahmsachs on how @GammaApp and @NotionHQ think about model selection on June 25th.
Jun 8
Working in the Training team at Baseten, I often see companies agonize over which model to use. So many people worry about how to keep up with benchmarks and new releases
But with post-training and specialization, and as we see a rising tide in the intelligence of many open-source models, what really matters is your learning signal. Do you have the right user metrics to say whether a model is doing poorly or well at your task, and to use that to learn and hillclimb the task?
If you want to learn more, I’m moderating a panel on June 25th in SF at 6 PM with Gamma co-founder Jon Noronha (@thatsjonsense) and Notion AI lead Sarah Sachs (@sarahmsachs) on model selection in a multi-model landscape.
4
15
2,573
Are you tired of waiting 17 minutes for an AI agent to finish a code change?
As an agent’s context grows, standard transformer attention can turn long runs into a bottleneck.
@NVIDIAAI Nemotron 3 Ultra addresses this with a hybrid architecture that replaces several attention-heavy layers with Mamba layers.
This makes long-context inference far more efficient. In benchmarked settings, this means:
→ step 300 runs as fast as step 3
→ up to 5x higher throughput
→ up to 30% lower cost
Today, Nemotron 3 Ultra, Nemotron 3.5 ASR, and Nemotron 3.5 Content Safety are available on Baseten for production AI teams.

Introducing NVIDIA Nemotron 3 Ultra.
A frontier smart open model built for long-running agents that need to plan, reason, use tools and keep working across complex coding, research and enterprise workflows.
Up to 5x faster inference and up to 30% lower cost for agentic tasks.
Learn more: nvda.ws/4x9nGps
2
20
1,429
Baseten retweeted

Jun 2
Today we're announcing MAI-Thinking-1 with Microsoft and it will be available on Baseten soon.
Microsoft built something genuinely different here: a commercial-grade thinking model trained on clean data with no distillation from third-party models and designed to be fine-tuned by the enterprises using it. Microsoft AI guarantees 100% eyes-off on post-training data and Baseten will handle the fine-tuning and deployment at scale.
The future isn't one model. It's many models, each owned by the businesses that shaped them and MAI-Thinking-1 is a big step in that direction.
baseten.co/blog/mai-thinking…

10
24
330
37,933
Baseten retweeted

Jun 4
I’m thrilled to welcome Gabe Stern to Baseten to lead Legal. Gabe is the whole package: deeply experienced, sharp, highly trusted, and commercially minded. We first got to work together at Slack, where he was an exceptional partner and played a critical role through Slack's hyper-growth & IPO. I’m personally very happy to be reunited with Gabe, and even happier that Baseten gets to benefit from his judgment, partnership, and instincts. Welcome, Gabe!
1
1
26
3,588