
Joined April 2020
- Tweets 460
- Following 1,488
- Followers 1,021
- Likes 1,159
111 Photos and videos




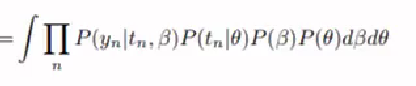
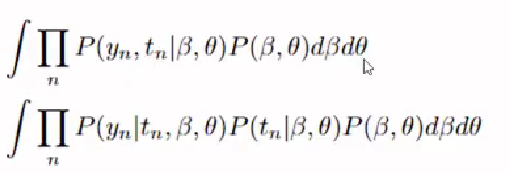




Bayesian ML at Scale retweeted

Feb 20
A friend just informed me that our colleage, Professor Arthur Dempster, has died last month at 96. Arthur was an intellectual giant, famous for developing the EM algorithm as well as for the Shafer-Dempster theory, but remained skeptic about causation.
memoritree.com/memorial/arth…. May his memory be an inspiration.
4
9
39
4,933

Jan 24
Well, everything (except probability)
Jan 24

Yann is right about everything (except RL).
1
222
26 Dec 2025
While this is more or less the main RecSys heuristic, and it is hard to beat, I do think we should try to do better. Being satisfied with a completely ad-hoc solution is not a long term path to progress.
25 Dec 2025

Simple way to replace RL with supervised learning: assign the reward to every action on the path to it and learn to predict it.
Hypothesis: no RL algorithm will ever beat this by much.
1
4
406
Bayesian ML at Scale retweeted
2 Dec 2025
Thanks for the engagement and the thoughtful response. It is difficult to outline my (many) points of agreement and the few points where I differ in an X post, but I will try.
> "I've never insisted on the "frequency interpretation" of probability."
In this paper statistical analysis is defined in frequentist terms.
escholarship.org/content/qt4…
I acknowledge I am being particularly purist here, but to a strict (operational subjective) Bayesian, probability does not exist, and the idea of a Bayesian estimator is a contradiction in terms.
The concept of "experimental conditions remaining the same" only makes sense with a frequentist notion of repeated draws from a low-dimensional probability model.
1
1
130
1 Dec 2025
The @yudapearl Pearlian view is that causal inference is a completely separate discipline to statistical inference (and statistical estimation can be tackled using either the Bayesian or frequentist paradigm) and then causal inference is "inference across distributions", that is a modification of a (frequentist) probability that accounts for an intervention. Here I quote @analisereal

1
2
5
392
1 Dec 2025
Full talk here: youtube.com/watch?v=hoFRVJLn…
Papers: arxiv.org/abs/1906.07125 proceedings.mlr.press/v163/r…
ICML Position paper by @kayembruno openreview.net/pdf?id=V1FP9W… which independently makes a similar argument.
1
1
169
1 Dec 2025
This thread probably comes across as "Bayesian boosterism". Obviously the work Pearl, his team and the movement he has inspired, have drawn attention to many examples that were never discovered with the Bayesian approach. The two Simpson's paradox examples and the front door rule can be handled with pure probability in a straightforward way, but other problems cannot be.
Examples that allow or insist on ignoring covariates are a particular problem for Bayes. Broadly here Pearl is right that ignoring the covariates is the fast easy way to get a correct solution, but Rubin is right that a Bayesian should condition on everything available (but this doesn't mean regress on everything). There is still work for the Bayesians to do here.
ml4interact.hashnode.dev/the…
1
100