
AI that continuously learns and adapts @AdaptionLabs | GTM x AI
Joined January 2012
- Tweets 318
- Following 402
- Followers 232
- Likes 167
128 Photos and videos










Ben Rycroft retweeted

Jun 10
Introducing Tiny AutoScientist.
Built on AutoScientist's research loop, Tiny AutoScientist helps organizations get more performance from models under 10B parameters.
Supersized intelligence. Tiny models.
7
23
197
11,655
Ben Rycroft retweeted
May 22
For the next 30 days, compute is on us.
Try AutoScientist. Set your outcome, co-optimize, and deploy with 78% relative improvement.

6
13
79
3,864

May 20
GPT-5.5 launched at double the price of GPT-5.4. Uber burned their entire 2026 AI budget by April. The cost of running frontier models at scale is stacking up.
When you build your stack around a closed model you pay whatever the vendor decides, with no ownership and no exit ramp.
Many teams already know fine-tuned open-source is the answer. Smaller, faster, cheaper per inference, fully private. But it's been a headache to get there.
Most fine-tuning runs fail, and the ones that work need ML expertise most teams don't have.
AutoScientist solves this.
It co-optimises your data and training recipe automatically.
Runs the full loop end-to-end. Idea to owned fine-tuned model in an afternoon.
35% better than human-configured training across 8 verticals.
Free for 30 days.
Fine-tune your own model for free (next 30 days): adaptionlabs.ai/auto-scienti…
2
2
83
May 13
AutoScientist launched today. Now anyone can train an AI model.
Fine-tuning used to live inside frontier labs. Tribal knowledge. PhDs. Weeks of sweeps.
That's gone.
Here's what the loop looks like now:
🔹 Raw data in: support tickets, transcripts, PDFs, whatever you've got sitting in production
🔹 Adaptive Data transforms it into structured, fine-tuning-ready datasets
🔹 AutoScientist runs the full research loop: optimizing data and training recipes until the model converges on your goal
🔹 Fine-tuned model out Hours. Not weeks.
The results surprised us:
🔹 35% average improvement over our own AI research staff configuring the same runs
🔹 Win rates from 48% → 64% against the base model
🔹 Consistent gains across all 8 verticals we tested
Prompt engineering was always a workaround.
You were contorting requests to fit a model built for the average use case, because shaping the model was too much of a lift.
Now it isn't.
Your data. Your model. Your moat.
Link below.
4h • Edited •
May 13

Introducing AutoScientist.
Most model training fails outside of frontier labs.
AutoScientist automates the full research loop so it doesn't have to.
1
2
6
716
Apr 30
Every week we talk to companies battling AI API bills.
Uber already blew their annual AI budget.
They all want the same thing.
🔷 A model that's an expert in their domain.
🔷 Runs 10x cheaper than a frontier API.
🔷 Carries their brand voice.
🔷 Fully private.
Fine-tuning is the path.
But most projects stall before training even starts.
The data isn't ready. Too thin. Too noisy. Too narrow to move the model. And the process is cumbersome.
Today we're making it a lot easier to fix.
Together AI fine-tuning is now live inside the Adaption platform.
Shape your data.
Train your model.
One workflow.
Training cycles drop from weeks to days.
This is a big step toward making fine-tuning accessible to every team, not just the ones with frontier-lab resources.
More announcements coming soon.
Apr 30
We believe that intelligence should not arrive preconfigured.
@togethercompute is now available directly inside the Adaption platform, connecting Adaptive Data with large-scale training in a single workflow.
One platform, end to end. Stop inheriting intelligence. Shape it.
1
3
162
Ben Rycroft retweeted

Apr 25
What if instead of building one giant AI, we evolved a coordinator to orchestrate a diverse team of specialized AIs? 🐟
Excited to share our new paper: “TRINITY: An Evolved LLM Coordinator”, published as a conference paper at #ICLR2026!
Paper: arxiv.org/abs/2512.04695
In nature, complex problems are rarely solved by a single monolithic entity, but rather by the coordinated efforts of specialized individuals working together. Yet, modern AI development is heavily focused on endlessly scaling up single, massive monolithic models, yielding diminishing returns. While model merging offers a way to combine different skills, it is often impractical due to mismatched neural architectures and the closed-source nature of top-performing models.
To address this, we took a macro-level approach: test-time model composition. We introduce TRINITY, a system that fuses the complementary strengths of diverse, state-of-the-art models without needing to modify their underlying weights.
TRINITY processes queries over multiple turns. At each step, a lightweight coordinator assigns one of three distinct roles to an LLM from its available pool:
1/ Thinker: Devises high-level strategies and analyzes the current state.
2/ Worker: Executes concrete problem-solving steps.
3/ Verifier: Evaluates if the current solution is complete and correct.
By dynamically assigning these roles, the coordinator effectively offloads complex reasoning and skill execution onto the external models.
What makes TRINITY unique is its extreme efficiency. The coordinator relies on the hidden states of a compact language model and a small routing head. In total, it has fewer than 20K learnable parameters.
Training this system presented a massive challenge. Traditional Reinforcement Learning (REINFORCE) failed because the gradients had a low signal-to-noise ratio due to binary rewards and weak parameter coupling. Imitation learning (Supervised Fine-Tuning) was ruled out because generating multi-turn labels is prohibitively expensive.
Our solution? We turned to nature-inspired algorithms. We optimized the coordinator using a derivative-free evolutionary algorithm. We found that evolution is uniquely suited to optimize this tight, high-dimensional coordination problem where traditional gradient-based methods fail.
The results are very promising. In our experiments, TRINITY consistently outperforms existing multi-agent methods and individual models across various benchmarks. At the time of publication, it set a new state-of-the-art record on LiveCodeBench, achieving an 86.2% pass@1 score.
More importantly, it demonstrated incredible generalization. Without any retraining, TRINITY transferred zero-shot to four unseen tasks (AIME, BigCodeBench, MT-Bench, and GPQA). On average, the evolved coordinator surpassed every individual constituent model in its pool, including GPT-5, Gemini 2.5-Pro, and Claude-4-Sonnet (the top frontier models available at the time of our #ICLR2026 submission last year).
This work is central to Sakana AI's vision. We believe the future of AI isn't just about scaling monolithic models, but engineering collaborative, diverse AI ecosystems that can adapt and combine their strengths.
We invite the community to read the paper and explore these ideas!
Paper: arxiv.org/abs/2512.04695
OpenReview: openreview.net/forum?id=5HaR…
This foundational research is part of the core engine powering our multi-agent product: Sakana Fugu 🐡👇

Apr 24

We’re launching the beta for our new commercial AI product: Sakana Fugu 🐡, a multi-agent orchestration system!
Blog: sakana.ai/fugu-beta
Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task.
Available as an OpenAI-compatible API, you can seamlessly integrate Fugu into your existing workflows with minimal changes.
🐟 Fugu Mini: High-speed orchestration optimized for latency
🐡 Fugu Ultra: Full model pool utilization for deep, complex reasoning
Apply for the beta test here: forms.gle/BtKkhc2CfLKk1dvNA

15
68
406
99,862
Ben Rycroft retweeted

Apr 27
What is crazy is we adapt data so fast you can still join the competition today, think about a meaningful long-tail problem to work on and be in a position to win by this Friday.
So join us. :)
Big shoutout to @sudip_r0y for building incredibly fast infrastructure.
Apr 27
The Uncharted Data Challenge closes Friday.
$20,000 prize pool for open-source datasets that fill the gaps mainstream AI keeps missing.
Evolve your data. Shape your AI.

5
7
69
7,576
Ben Rycroft retweeted
Apr 23
Only 10% of your data speaks AI.
The other 90% is unstructured — invisible to the models making decisions about your business.
All the progress in AI so far? Built on a fraction of what's actually out there.
Today we're launching Forge, a feature of Adaptive Data, to extend adaptive intelligence to the 90%.
10
20
86
16,356
Apr 22
We're watching an entire discipline emerge (Context Engineering) because we haven't figured out how to make AI learn continuously.
Kudos to Malika Aubakirova for the comparison to the Christopher Nolan classic Memento in this @a16z piece. We're duct-taping context windows and RAG pipelines together to keep our models from forgetting what happened one prompt ago.
If context engineering has you doing backflips and you're looking to train models that become native experts at your use case, get in touch.
Apr 22

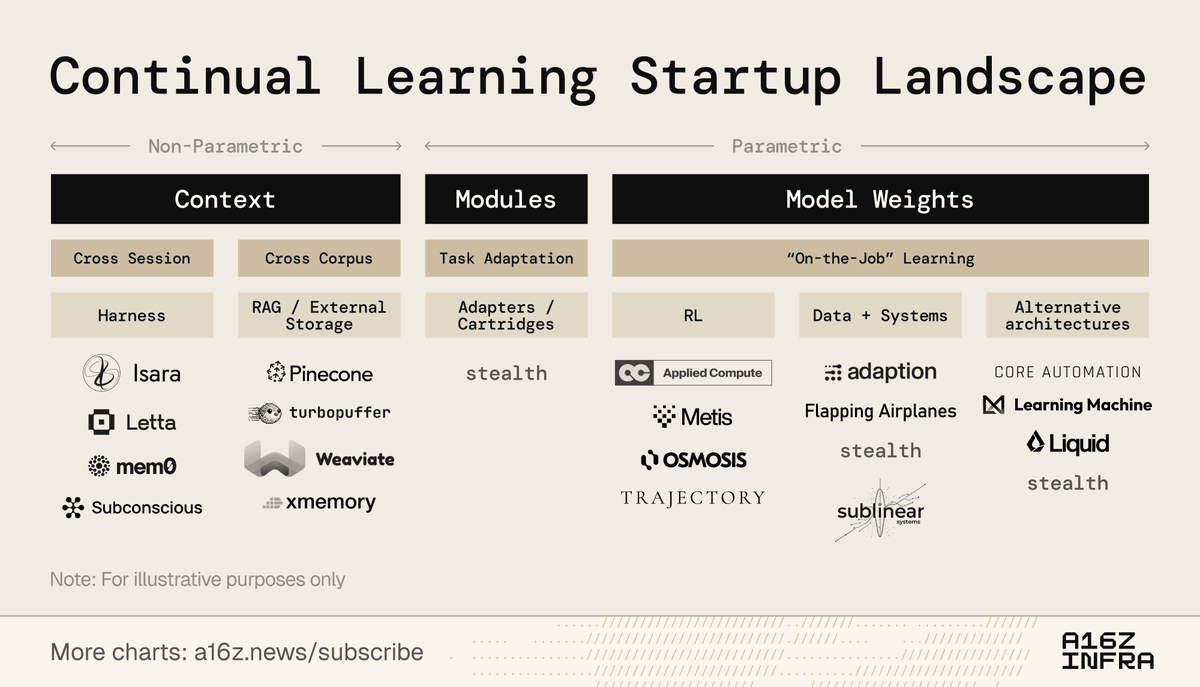
Static models won’t win against dynamic environments.
Adaptable AI will.
Systems that learn during use, not after the fact, are the ones that scale.
Everything else falls behind.
@a16z mapped who's building on that. @adaption is in it.
1
78
Apr 22
Demis Hassabis spoke at City Arts & Lectures in SF Monday night.
And it won't make your news feed.
Zero hot takes.
In contrast, AI has been racking up negative headlines in the US.
"It's coming for your job"
"This is a terminator scenario"
"The end of software engineers"
And it's sticking.
NBC ran a widely cited poll that found AI has a net favorability of -20. For context, below ICE and just above the Iranian government.
People have real reasons to be wary:
🔷 Data centers increasing electricity prices
🔷 Job displacement
🔷 Deepfakes
These concerns are legitimate.
But caution shouldn't mean inaction.
In China, 83% of people believe AI offers more benefits than drawbacks. In the US, it's 39%.
In India and China, more than 80% of workers use AI regularly at work. In the US, closer to 50%. (Stanford HAI)
These countries are building AI fluency into the next generation by default.
China made AI a compulsory school subject in 2025. Kids as young as six are learning algorithmic thinking and robotics. India launched AI modules for grades 6-12. The goal: build the world's largest AI-ready student population.
Singapore, South Korea, and the UK are moving in the same direction.
In the US, only half of middle and high schools have any AI policy at all.
The US still leads on building with AI.
But the risk is the median person enters the job market without knowing how to use it well, while their peers abroad treat it like electricity.
AI literacy isn't just about writing prompts. Knowing when to trust it. When to push back.
When to reach for it. When to close the app.
We're not teaching this well. And the negative narrative is putting people off.
This is why we need more voices like Demis that can hold both things at once.
As he says:
The risks are real. There is a non-zero chance AI goes wrong.
The upside is also real. A society with infinite resources. No diseases.
The genie is not going back in the bottle.
This generation will either shape how AI gets used or get shaped by how others use it.
The difference is whether anyone brings them in and shows them how.
97
Apr 16
You find a great dataset on Hugging Face.
Now you can make it yours.
Maybe you need it in 12 languages. Reshape it for a different task. 10x more volume and improve the quality. Add reasoning traces.
This is what sits between your dataset and a production-ready model.
Hugging Face is now available in Adaptive Data.
Pull any dataset directly into a platform built to close that gap.
🔹 Improve data quality across the full set
🔹 Reshape for your specific task
🔹 Expand into 242 languages
Go from raw data to training-ready. Without the manual grind.
Link below.
Apr 16
The open-source AI community just got a new home for their data workflows. 🤗
@huggingface is now available in Adaptive Data.
Pull datasets directly into a platform that evolves with the problems you're solving.
1
2
11
699
Apr 14
Last week we jumped on a call with a team scaling into 6 markets.
Their AI worked great. In English.
But their users speak Brazilian Portuguese. German. Arabic.
And they don't want a translated experience. They want a native one.
Where the model doesn't fall back to English.
Or output low quality results.
Translation slaps new words on English-trained thinking.
The grammar feels off. The tone is wrong. The output reads like it was written by picking words out of a dictionary. Not a native speaker.
Users notice. And they leave.
This is a training data problem.
If your model only learned from English-heavy data, it thinks in English. Every other language gets a second-class output.
Today we're launching Expand Your World in Adaptive Data.
Adapt your training data into 242 languages.
No translation wrapper on English output.
Your model thinks natively in your users' language.
Your AI feels local everywhere it ships.
Full announcement below.
Are you a startup building models that needs to work across languages?
Adaption for Startups gives you a sponsored Plus Plan and credits to make your model a native polyglot from day one:
adaptionlabs.ai/adaption-for…
Apr 14
Most datasets reflect the world as it was convenient to capture, not as it actually exists.
Introducing Expand Your World, a new feature in Adaptive Data.
242 languages and localizations.
The fastest way to global coverage.
1
2
14
3,893
Ben Rycroft retweeted
Apr 8
The Uncharted Data Challenge has been live for less than a week. Builders around the world are already creating.
AI for local supply chains and economic realities. Crisis response for the scenarios where AI needs to get it right.
There is still time to be part of it. $20,000 prize pool. Closes May 1.

6
10
39
2,792
Apr 7
Great opportunity to discuss the trends shaping AI including data optimisation for post-training. Take a look if you’re around SF
Apr 7
The next era of AI won’t be won by scale. It will be won by those who adapt.
The Adaption Table is an executive dinner series for senior leaders at the forefront of that shift.
Beginning April 16 in San Francisco.

2
15
1,942
Apr 7
There's a general assumption you should plug into Anthropic or OpenAI.
Databricks analyzed how 10,000 organizations (including 300 Fortune 500s) are using AI.
The data shows a different story:
🔹 76% of enterprises have now moved open-source LLMs into their production mix
🔹 77% of those are choosing smaller models (13 billion parameters or fewer)
@databricks calls this "one of the biggest shifts in the state of AI."
It makes a lot of sense when you look at the unit economics.
Renting a massive closed API is fine for a pilot.
But at scale, it's just a really expensive way to get answers.
Smaller models run faster.
Need way less compute.
Karl JG Lowenbjer at Nira post-trained a fleet of small models. One expert for each task in the workflow.
And teams are realizing if they take a smaller open model and post-train it on their own specific data...
It matches (or exceeds) massive frontier models at ±20% of the cost. Plus:
🔹 lower latency
🔹 complete control and data security
You end up with a specialized asset that you actually own, instead of a monthly rental.
Sometimes bigger is just a bigger API bill.
1
59
Ben Rycroft retweeted
Apr 6
The most valuable datasets in the world don’t exist yet.
We're here to change that.
The Uncharted Data Challenge is live on @kaggle. $20,000 in prizes.
3
13
46
4,094
Apr 5
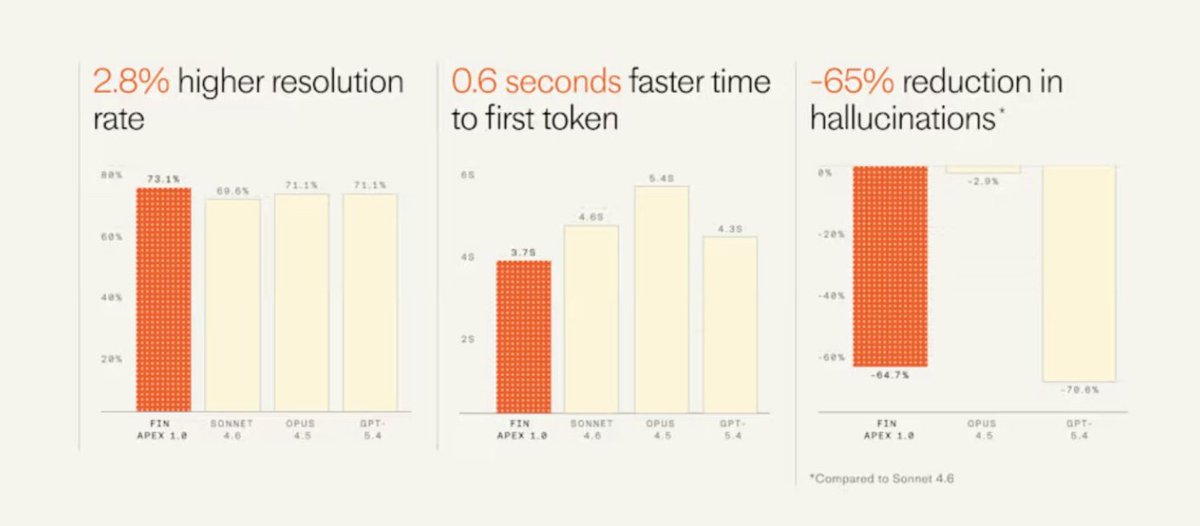
A 15-year-old SaaS company built an AI model that beats GPT-5.4 and Sonnet 4.6.
Here's how @intercom's Fin Apex 1.0 outperformed:
🔹 Customer service resolutions (73.1% vs 71.1%)
🔹 0.6 seconds faster response time
🔹 65% fewer hallucinations
And the big one:
🔴 Costs 5x less than frontier models
How did they pull it off?
They focused entirely on post-training.
Intercom took an open-weights base model and refined it using years of hyper-specific, proprietary customer data.
They didn't just dump raw chat transcripts into the model.
They used outcome-based reinforcement learning > training the model on actual resolutions. Teaching it nuance, tone, when to make judgment calls, and what a genuinely solved problem looks like.
@eoghan McCabe (CEO, @intercom): "The frontier, if you will, is actually in post-training. Post-training is the hard part. You need proprietary data. You need proprietary sources of truth."
Companies are catching on.
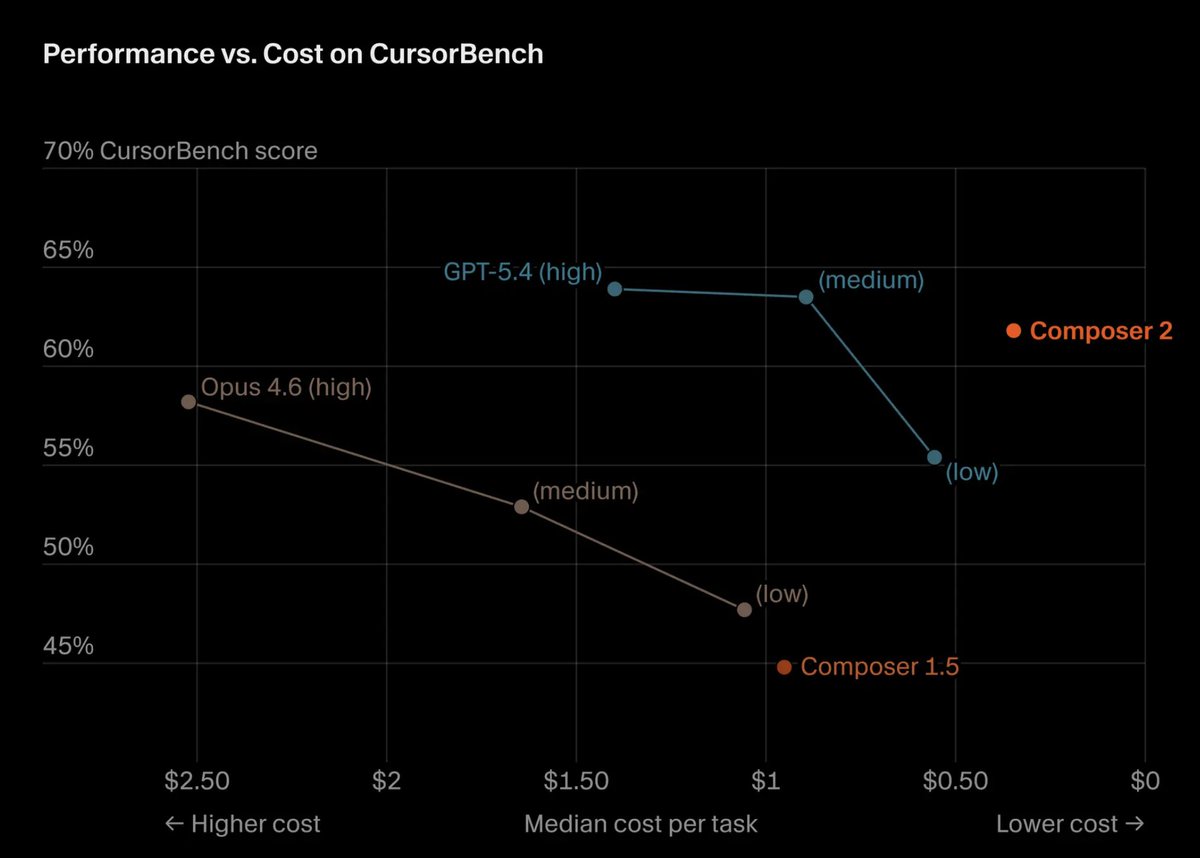
Cursor's Composer 2 was built on Kimi K2.5.
You can rent a closed API.
Or, you can take an open model and post-train it on your own high-quality, domain-specific data.
One is an expensive monthly rental. The other is a highly specialized, proprietary asset.
5
97
Ben Rycroft retweeted
Apr 3
Acceptances going out to participate in our uncharted data challenge.
Did you get yours?
The next wave goes out on Monday. Be part of it. 🔥 Some of the most important knowledge in the world has never made it into a dataset.
Apply to change that.
8
12
54
12,498