
Sky Computing - looking for the Berkeley Skydeck? They’re on the other side of Campus from us @SkyDeck_Cal.
Joined November 2021
- Tweets 85
- Following 24
- Followers 1,456
- Likes 66
Photos and videos
UC Berkeley Sky retweeted

👀Humans compare images by looking back and forth. Many open-weight VLMs encode each image independently, and defer comparison to the LM.
We introduce SVE: Stateful Visual Encoders for Vision-Language Models, where the visual encoder itself becomes change-aware.
🌐Project: statefulvisualencoders.githu…
📰Paper: arxiv.org/abs/2606.04433
💻Code: github.com/StatefulVisualEnc…
1/n
4
38
248
50,811
UC Berkeley Sky retweeted

Jun 3
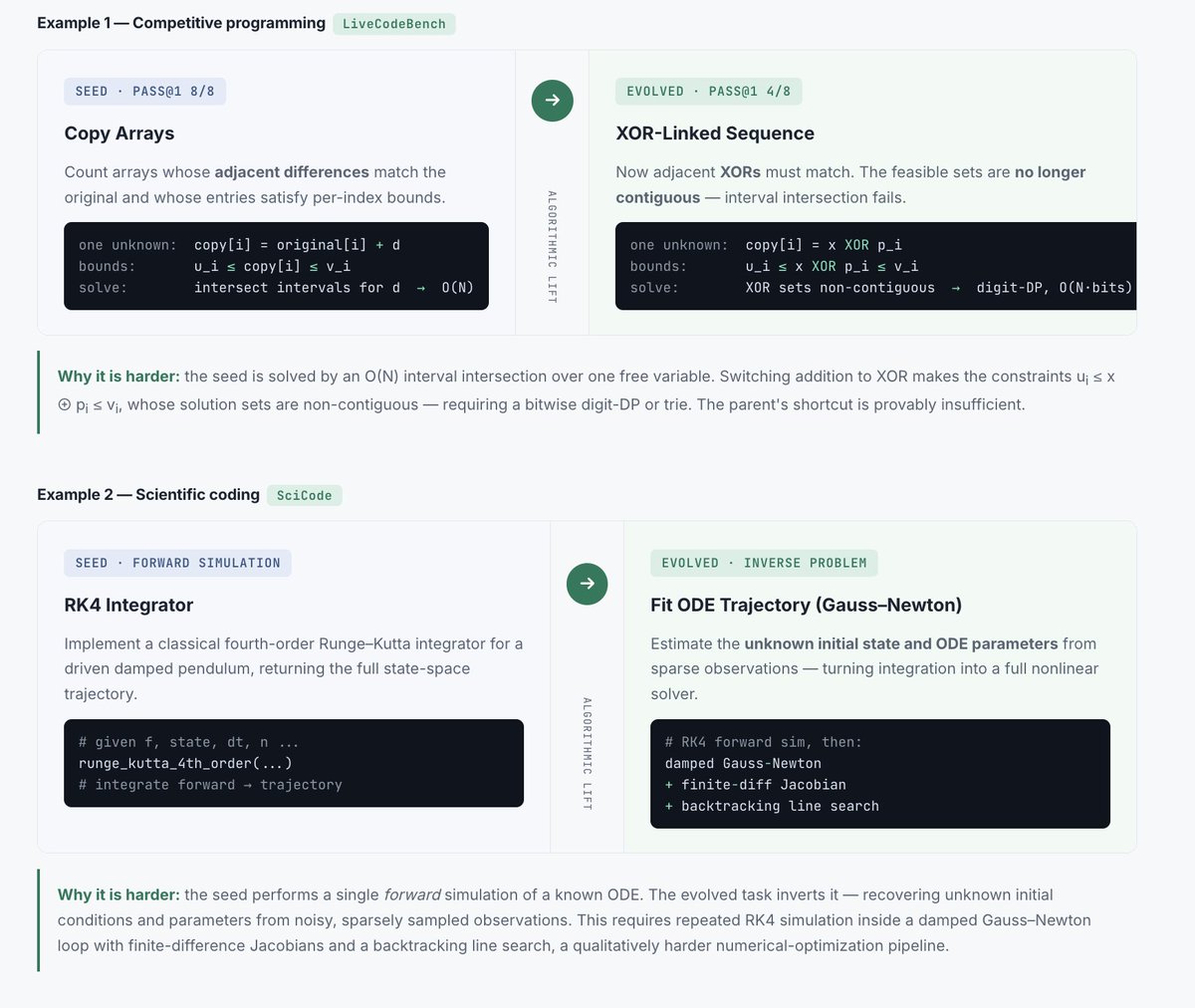
Static benchmarks are dying — they tend to get saturated quickly.
Evaluation and training data should co-evolve with frontier models.
We released BenchEvolver — a framework that automatically evolves saturated problems into harder, verified tasks for evaluating frontier models, which can also serve as useful self-improvement signals for RL.
New work from UC Berkeley @berkeley_ai @BerkeleyRDI @BerkeleySky
Project Page: benchevolver.github.io
Paper: arxiv.org/abs/2606.01286
5
20
95
39,874
UC Berkeley Sky retweeted

May 27
Agents are finding more vulnerabilities than ever. But it turns out there are gaps in existing vulnerability discovery. Over the past 90 days vs. a year ago, web vulnerabilities (XSS/SQLi/CSRF) are down 66% and memory safety exploitability is down 3.5x.
We built the Agentic Vulnerability Coverage Map to track it all, updated daily. Introducing the Berkeley Vulnerability Initiative: vuln.cs.berkeley.edu. ⤵️
3
16
65
14,257
UC Berkeley Sky retweeted

May 27
We release Recon — a new approach to reasoning synthesis for user modeling.
The key insight: post-hoc rationalization ≠ reasoning.
We propose using action reconstruction as a scoring criterion for synthesized reasoning traces, yielding more causally faithful reasoning and improved downstream action prediction across user modeling tasks.
Paper and project page in 🧵

2
19
45
9,907
UC Berkeley Sky retweeted

May 24
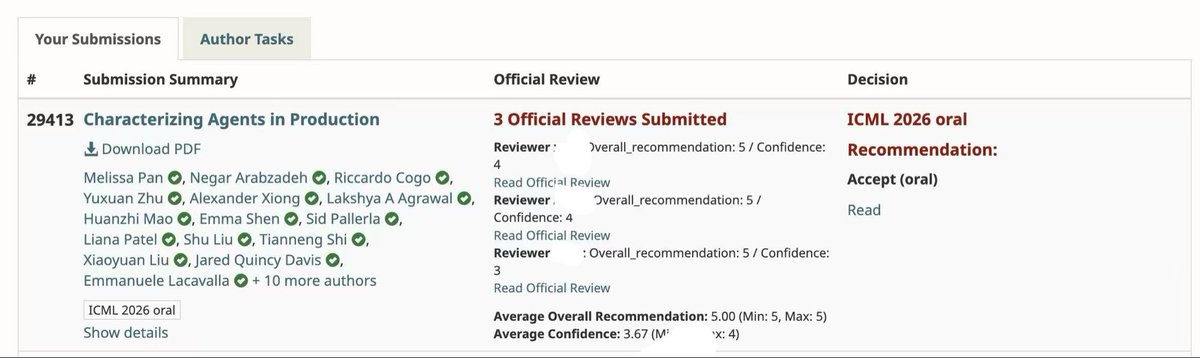
Excited to share that MAP has been selected for ✨ICML Oral✨
We look forward to sharing the insights in the paper with the community
And much much appreciations to everyone who participated in our study ❤️ MAP won’t be possible without your contribution to open science
Apr 30

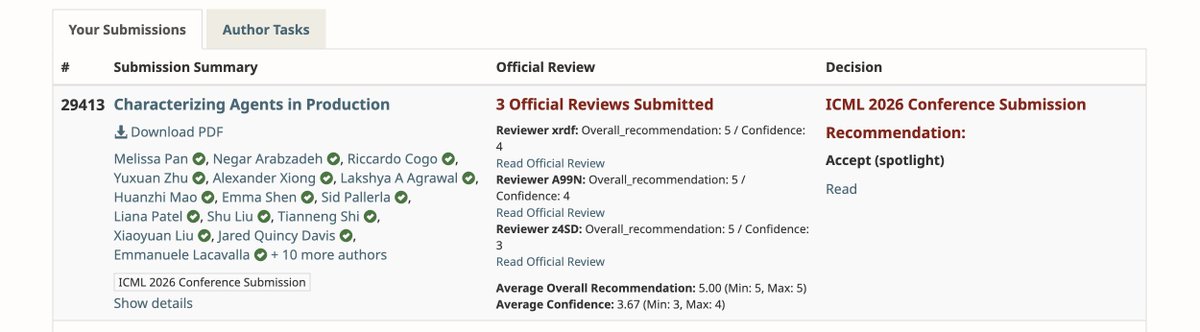
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡

7
15
170
32,460
UC Berkeley Sky retweeted

May 15
Open-ended coding training data may no longer be the bottleneck: AI can scale open-ended tasks—and even outperform human-expert curation.
FrontierCS team is releasing FrontierSmith: a system for synthesizing open-ended coding problems at scale. Starting from closed-ended coding tasks, FrontierSmith mutates, filters, and builds runnable optimization environments for long-horizon coding agents. In our experiments, FrontierSmith data trains stronger models than human-curated open-ended data on FrontierCS and ALE-bench.
Blog: frontier-cs.org/blog/frontie…
Paper: arxiv.org/abs/2605.14445
Code: github.com/FrontierCS/Fronti…
Model: huggingface.co/runyuanhe/qwe…
14
72
333
94,741
UC Berkeley Sky retweeted

May 25
🚀 Excited to release mKernel: a set of fast multi-node, multi-GPU fused kernels.
💻 Code: github.com/uccl-project/mKer…
📝 Blog: uccl-project.github.io/posts…
mKernel fuses compute communication into one persistent GPU kernel, covering both intra/inter-node with GPU-initiated communication.
Amazing team: @yangzhouy, Chon Lam Lao, Costin Raiciu, Scott Shenker, @istoica05

4
59
403
62,314
UC Berkeley Sky retweeted

Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
May 13

Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls

13
43
188
33,492
UC Berkeley Sky retweeted

May 12
1/ Thrilled to introduce T³: a corpus for RAG over reasoning tasks, built from thinking traces.
We show that surprisingly RAG can improve reasoning— with the right corpus.
Rag with Transformed Thinking Traces T³ gain by up to 43.9% on AIME 2025-2026.
🔗 arxiv.org/abs/2605.03344 🧵

11
30
211
472,669
UC Berkeley Sky retweeted

May 4
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10 frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)

42
168
1,186
833,657
UC Berkeley Sky retweeted

May 1
Agent harness is as important as the model for cybersecurity.
$300 in compute, 9 OSS-Fuzz projects, 14 security issues and 5 CVEs.
The key lesson: you don’t need a secret model to find real security issues. You need an effective, affordable, reliable harness.
5 takeaways 🧵

1
8
16
1,534
UC Berkeley Sky retweeted
Apr 30
Excited to announce that FrontierCS has been accepted to ICML 2026! 🚀
We are scaling our open-ended task set to 250 tasks (100 new tasks in 2026 Q1🔥), featuring long-horizon agent settings in Harbor and integration into real-world human contests. More exciting updates to come! Huge thanks to all our collaborators.
#ICML2026 #AI #MachineLearning

18 Dec 2025

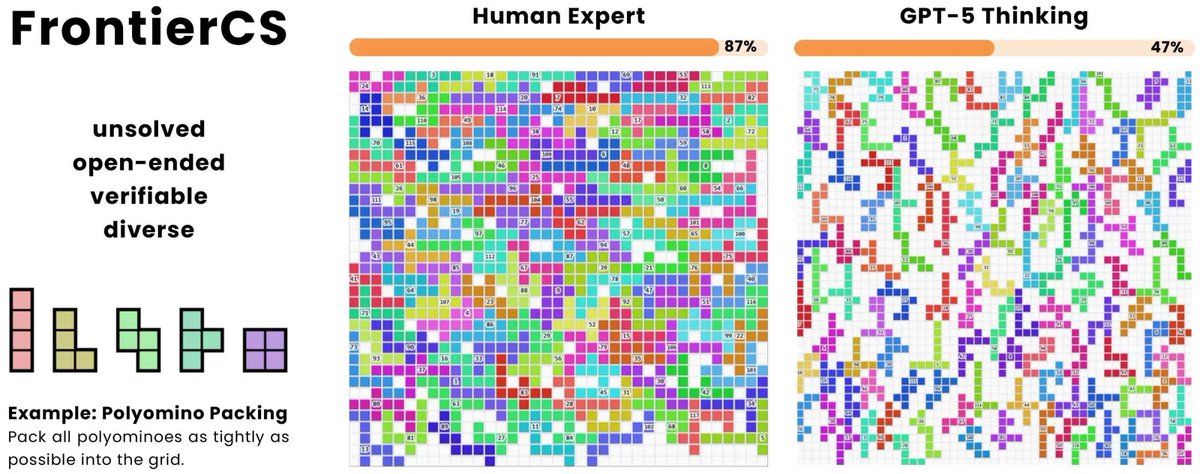
Pass/fail benchmarks are saturated. It’s time for FrontierCS. 🚀
150 unsolved, verifiable problems ranging from competitive programming to real-world research. Designed by PhDs & ICPC experts to evolve model intelligence. 🎓🧠
🧵👇Check it out!
Paper: arxiv.org/abs/2512.15699
1
11
56
6,523
UC Berkeley Sky retweeted
Apr 30
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡
10
31
234
63,451

What if one person could run a unicorn company?
Today we're open-sourcing OMAR — a TUI that lets a single engineer orchestrate hundreds of AI coding agents in deep, recursive hierarchies.
Built at Berkeley. Powered by tmux.
github.com/lsk567/omar 🧵
1
4
15
2,592
UC Berkeley Sky retweeted

Apr 29
Would you trust an AI agent to negotiate on your country's behalf at the G20?
Real coordination is long-horizon, asymmetric, and non-binding; current multi-agent evaluations miss this.
We build Cooperate to Compete (C2C): a testbed for LM agents coordinating with rivals. 🤝🔪🎭

6
26
95
26,713
UC Berkeley Sky retweeted

Congratulations to Matei Zaharia on being awarded the ACM Prize in Computing! His development of open-source systems helped enable large-scale machine learning, analytics and AI at a global scale.
@matei_zaharia @UCBerkeley
🔗 Read more: bit.ly/4vbNujK

ALT Matei Zaharia; UC Berkeley College of Computing, Data Science, and Society logo.
2
11
49
7,710
UC Berkeley Sky retweeted

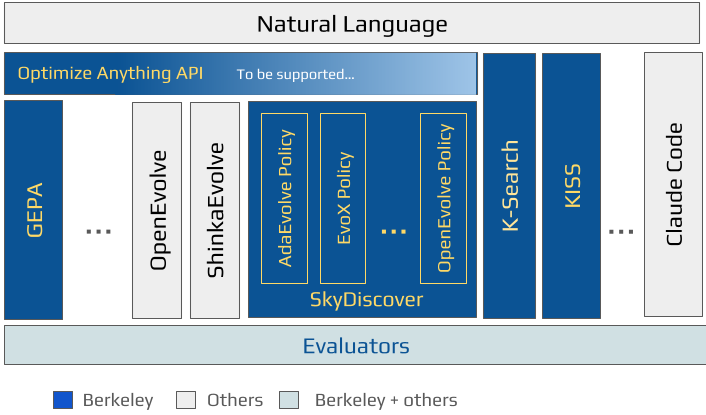
🎯 One Year of AI-Driven Research at Berkeley
[ADRS Blog #20] For the past year at Berkeley, we have been working on automating discovery with AI. In our blog post this week, we provide an overview of these efforts: the key problems we’re tackling, the frameworks and solutions we’ve built so far, and how these efforts fit into a broader vision for AI-driven scientific discovery.
✍️ Read the blog: ucbskyadrs.github.io/blog/be…
📖 ADRS Blog Series: ucbskyadrs.github.io/
1
11
68
23,276
UC Berkeley Sky retweeted

Mar 19
Introducing M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
We bring back non-linear recurrence to language modeling and show it's been held back by small state sizes, not by non-linearity itself.
📄 Paper: arxiv.org/abs/2603.14360
💻 Code: github.com/open-lm-engine/lm…
🤗 Models: huggingface.co/collections/o…
10
109
515
147,705
UC Berkeley Sky retweeted

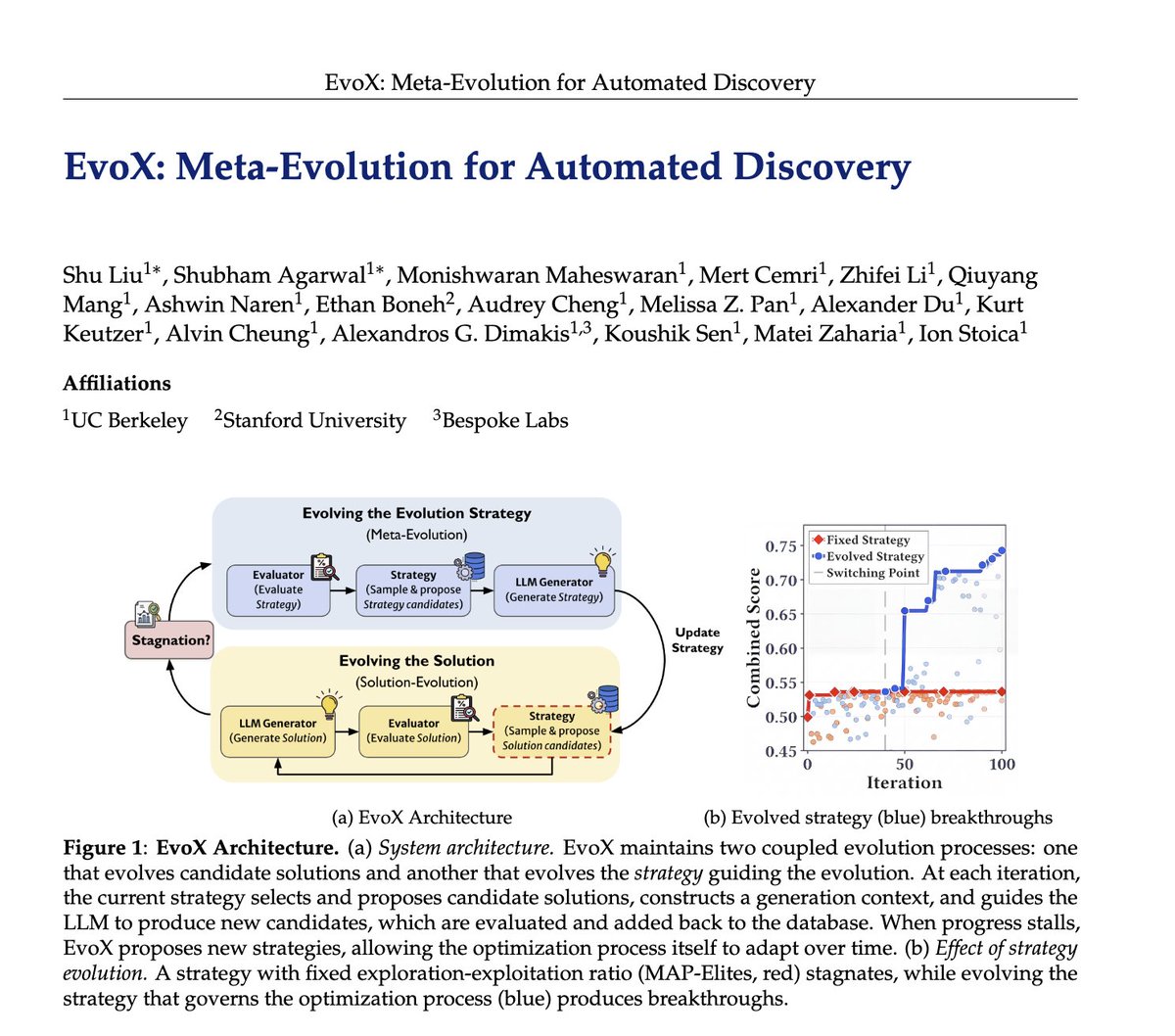
Mar 17
Researchers spend hours and hours hand-crafting the strategies behind LLM-driven optimization systems like AlphaEvolve: deciding which ideas to reuse, when to explore vs exploit, and what mutations to try.
🤖But what if AI could evolve its own evolution process?
We introduce EvoX, a meta-evolution pipeline that lets AI evolve the strategy guiding the optimization. It achieves high-quality solutions for <$5, while existing open systems and even Claude Code often cost 3-5× more on some tasks.
Across ~200 optimization problems, EvoX delivers the strongest overall results: often outperforming AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve on math and systems tasks, exceeding human SOTA, and improving median performance by up to 61% on 172 competitive programming problems. 👇
19
85
498
99,908
UC Berkeley Sky retweeted

Mar 16
Very nice results and great project!
Sharing some of our experience with similar agentic frameworks at UC Berkeley:
ADRS blog series: ucbskyadrs.github.io/blog/
GEPA: github.com/gepa-ai/gepa
KISS: github.com/ksenxx/kiss_ai
1
16
115
10,241