
Postdoc @UCBerkeley @BerkeleySky |👩🏻💻Prev @google, @MSFTResearch, @SpotifyResearch | 📚@UWaterloo | Interested in Information Retrieval
Joined April 2017
- Tweets 476
- Following 1,105
- Followers 1,499
- Likes 5,493
62 Photos and videos














Pinned Tweet

May 12
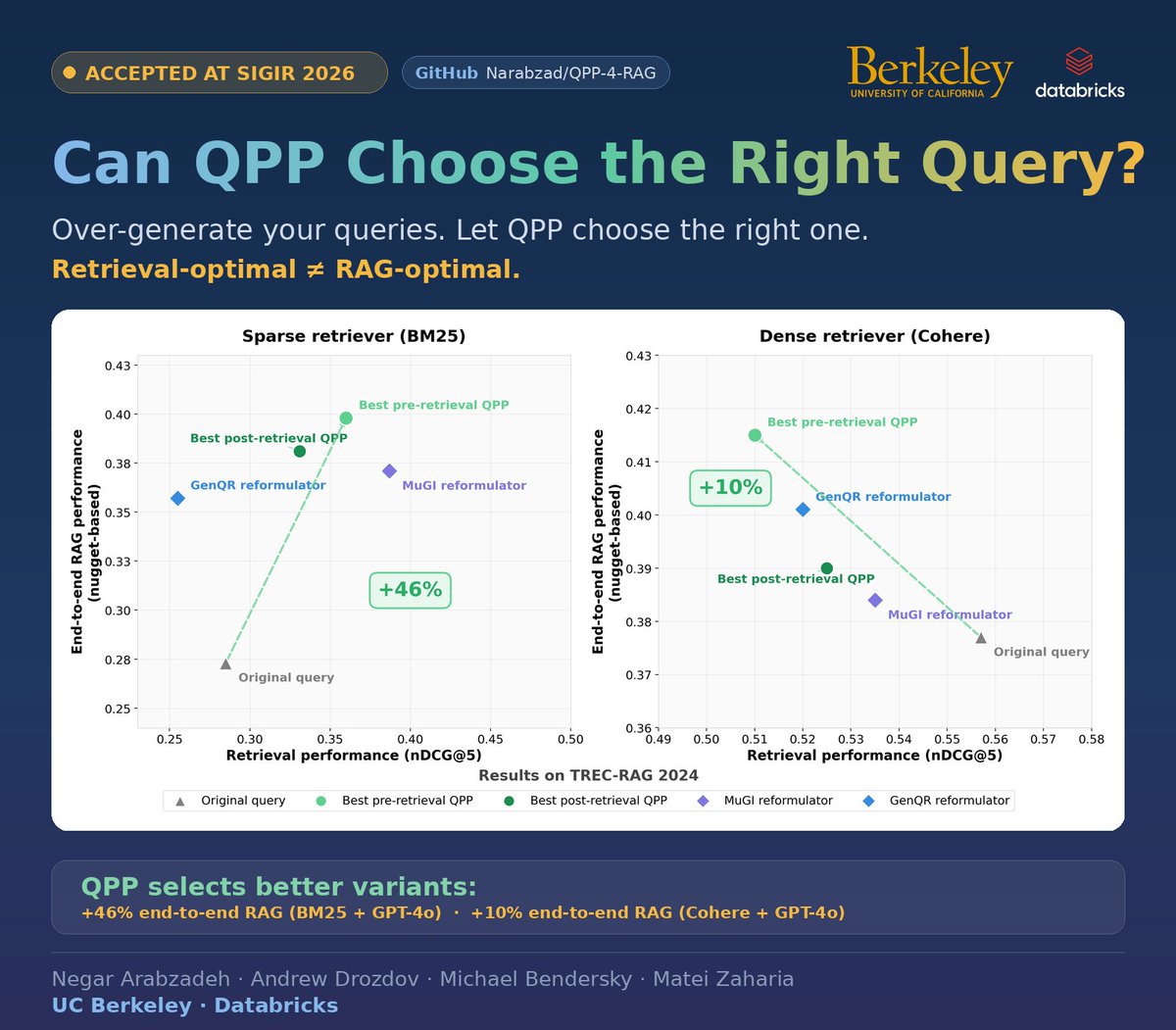
1/ Thrilled to introduce T³: a corpus for RAG over reasoning tasks, built from thinking traces.
We show that surprisingly RAG can improve reasoning— with the right corpus.
Rag with Transformed Thinking Traces T³ gain by up to 43.9% on AIME 2025-2026.
🔗 arxiv.org/abs/2605.03344 🧵
11
30
211
472,669
Negar Arabzadeh retweeted

Jun 10
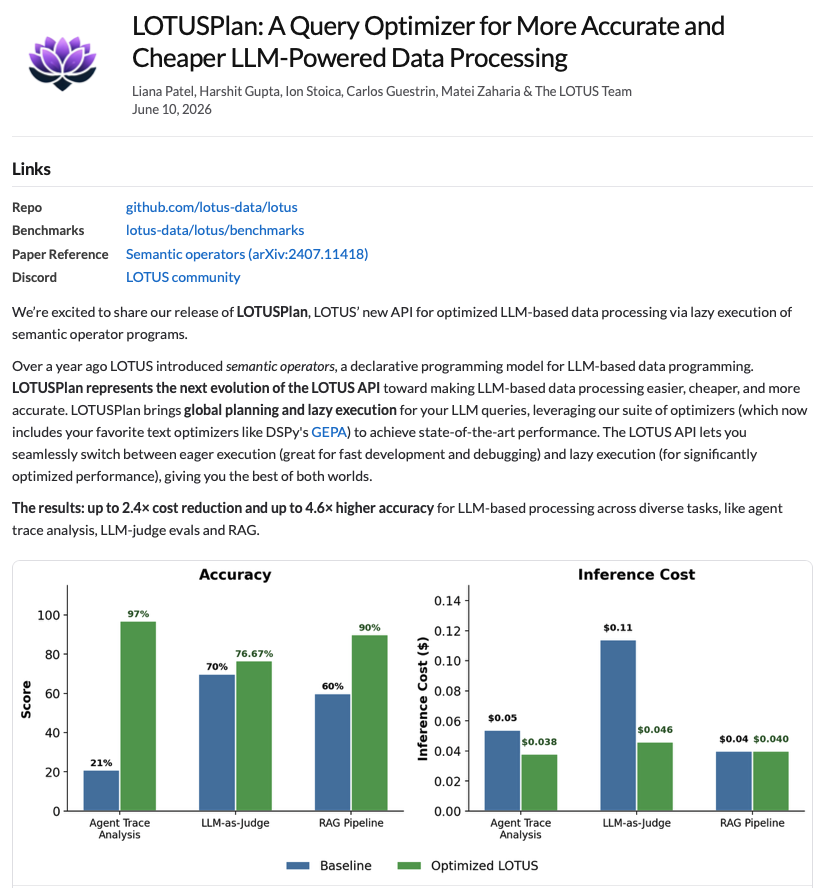
🚀 Beyond excited to share we're releasing LOTUSPlan, a new API & optimizer for higher performance LLM-powered data processing, from our team at Berkeley & Stanford.
LOTUS now lets you write your LLM-based queries and optimize them for up to 2.4× lower cost and 4.6× higher accuracy for tasks like, agent trace analysis, LLM-judge evals, RAG, document extraction and deep research.
✨Checkout our our new blog: liana313.github.io/blog/lotu…
🧵
9
21
80
16,985
Negar Arabzadeh retweeted

Jun 10
The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
25
116
693
72,003
Negar Arabzadeh retweeted

Jun 4
Search is becoming increasingly agentic: systems plan, search, synthesize, cite, and revise. But, how should we study and evaluate these systems? 🤔
In TREC RAG 2026, we want to build a reusable collection for this new reality
We’ve aligned on 4 core directions 🧵👇
1
6
16
1,861
Negar Arabzadeh retweeted

Jun 3
Excited to announce that our paper “From Noise to Order: Learning to Rank via Denoising Diffusion” has been accepted to #ICTIR2026! 🎉📚
📄Paper: arxiv.org/pdf/2602.11453
💻 Code: github.com/sadjadeb/Diffusio…
1
3
14
509
May 27
Grateful that my PhD thesis was recognized as one of the top dissertations in the 2026 Faculty of Mathematics Doctoral Prize at the @UWaterloo ! 🎉
And it is always especially nice to hear kind words from your PhD supervisor @claclarke . I guess that feeling never really goes away, even after you graduate. 😊
uwaterloo.ca/computer-scienc…
7
5
95
6,860
May 26
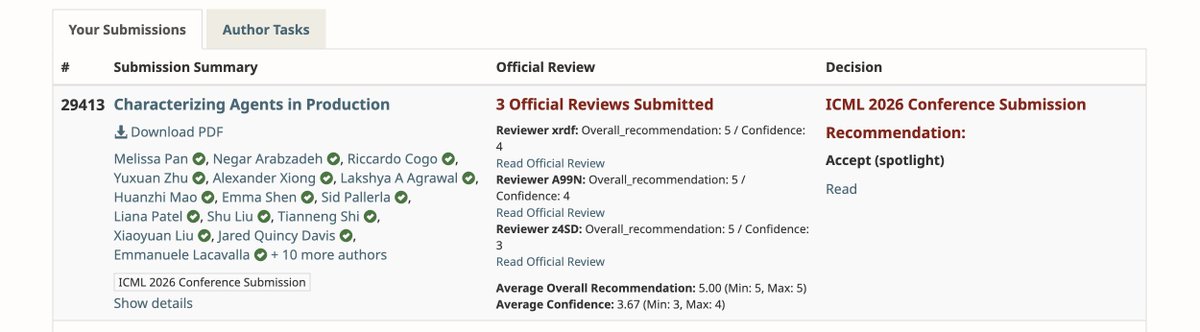
Happy to share that our @icmlconf paper "Measuring Agents in Production" received an Oral Presentation spot! 🌟
arxiv.org/abs/2512.04123
See you all in Seoul! 🇰🇷
Apr 30

Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡

1
2
17
2,044
Negar Arabzadeh retweeted

May 24
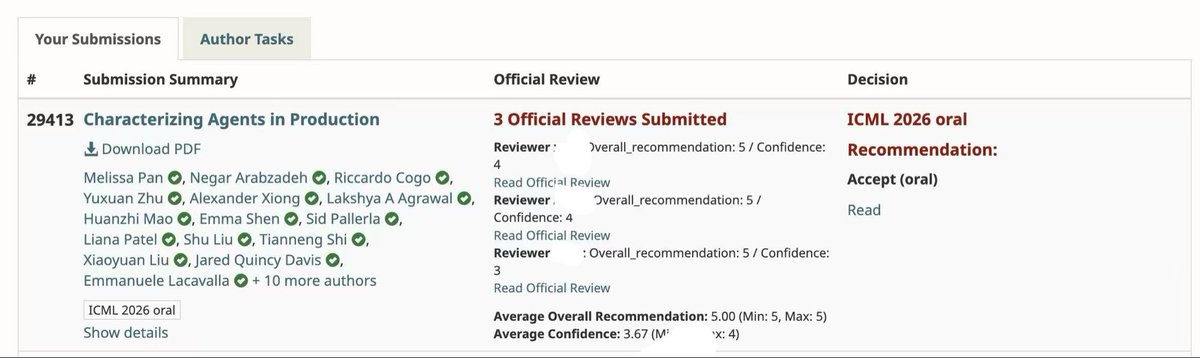
Excited to share that MAP has been selected for ✨ICML Oral✨
We look forward to sharing the insights in the paper with the community
And much much appreciations to everyone who participated in our study ❤️ MAP won’t be possible without your contribution to open science
Apr 30
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡
7
15
170
32,460
May 12
1/ Thrilled to introduce T³: a corpus for RAG over reasoning tasks, built from thinking traces.
We show that surprisingly RAG can improve reasoning— with the right corpus.
Rag with Transformed Thinking Traces T³ gain by up to 43.9% on AIME 2025-2026.
🔗 arxiv.org/abs/2605.03344 🧵
11
30
211
472,669
May 12
5/ Interestingly, RAG over T³ can be cheaper than No RAG.
Retrieved reasoning shifts work from expensive output tokens to cheap input tokens — the model thinks less and reads more.
Think less. Retrieve thinking. 🧠
1
1
4
385
May 12
6/ Code, corpora, prompts — all open:
🔗 github.com/Narabzad/t3
Transformed corpora available on Hugging Face.
Thanks to my amazing coauthors @wenjie_ma , @sewon__min , and @matei_zaharia 🙏
1
5
396
May 10
I’m glad to be part of this initiative!

In 2007, Mark @IR_oldie and I launched EVIA, a workshop on information access evaluation methods collocated with #ntcir6 .
Now in 2026, Negar @NegarEmpr and I are serving as PC co-chairs of #evia2026, which will take place on Day 3 (Dec 10) of #ntcir19 .
CFP in preparation..
7
382



We set out to build a better retriever, so we looked for the hardest IR benchmarks.
For each, we asked how much headroom remained by running oracle reranking with a frontier LLM. Most had little room left!
So we built OBLIQ-Bench to study much harder search queries than before.
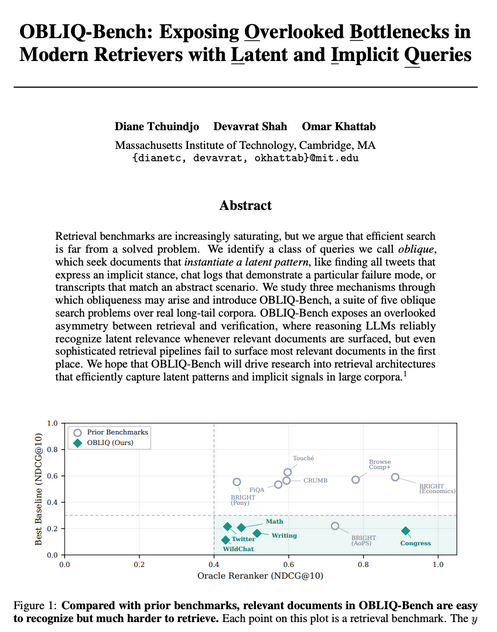
9
59
281
147,819
Negar Arabzadeh retweeted

May 4
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10 frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)

42
168
1,186
833,677
Negar Arabzadeh retweeted

Apr 30
Congratulation to the team for the MAP paper being accepted as an ICML spotlight! A key takeaway from this work is that reliability remains one of the central challenges for production agent systems. Simple yet effective methods continue to dominate in these agent systems for…
Apr 30
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡
8
76
8,928
Apr 30
So excited to share that my first ever @icmlconf paper has been accepted as a Spotlight! ✨
Grateful, happy, and incredibly excited about this work! See you all in Seoul!🇰🇷
Apr 30
Excited to share: MAP has been accepted as 🌟 ICML Spotlight 🌟
We hope MAP can provide data-driven insights that help the communities to work on various under-explored research directions around agent systems!
Huge thanks & congrats to my amazing co-authors. See you all at Seoul! 🫡
2
32
1,897