
Assistant Professor of CSE @CUHKofficial. Postdoc @MPI_IS. PhD @Cambridge_Uni & @GeorgiaTech. Previous Intern @Google & @nvidia. All opinions are my own.
Joined May 2009
- Tweets 920
- Following 789
- Followers 2,496
- Likes 2,999
116 Photos and videos


Weiyang Liu retweeted

Jun 9
76
400
2,991
942,254

Jun 8
Great post. I think there is much more to unpack behind the spectrum-preserving update rule in Pion (spherelab.ai/pion). Jianlin derives a different spectrum-preserving update rule from a steepest-descent perspective, leading to an alterantive orthogonalization (msign).
Jun 8

Steepest Descent on Manifolds: 6. Muon Double Rotation
kexue.fm/archives/11777
Introduces MuonR — a Muon variant that constrains updates to left & right rotation matrices. This preserves the singular value distribution of weights, providing a clean, elegant way to maintain training stability.
3
30
6,791
Jun 7
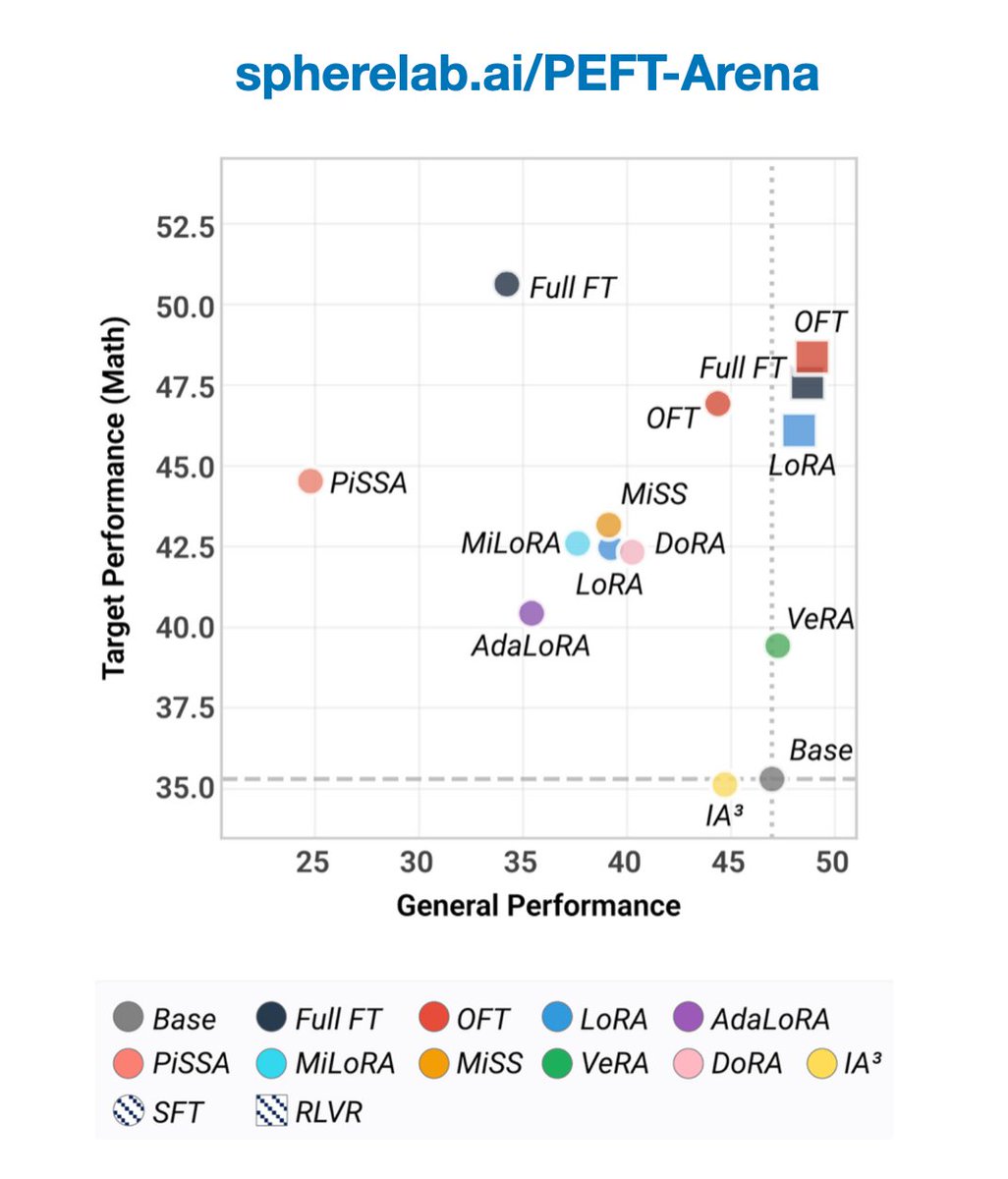
In PEFT-Arena (spherelab.ai/PEFT-Arena), we found a “free lunch” that improves both adaptation performance and preservation of general capabilities across PEFT methods, including full-parameter finetuning. The trick is simple: interpolate the weights and choose a midpoint between the fine-tuned model and the pretrained model. This can be useful in practice.
For Orthogonal Finetuning (OFT), the best interpolation is not linear. It should respect the orthogonal geometry, so the interpolation is performed within the orthogonal group (the computation is still very simple).
1
17
1,505
Jun 6
Quite inspiring. Optimizer design seems increasingly architecture-driven, from vector-based to matrix-based, and ultimately architecture-aware.

2
21
2,925
Jun 3
I find this project particularly elegant because it addresses a simple yet practically important question: should momentum be applied before or after the orthogonalization step? We study this question through the lens of spectral filtering and show that applying momentum before orthogonalization acts as a denoiser and can be provably better than applying momentum afterward.

🧠Why does Muon do momentum before orthogonalization?
✨Our key insight: momentum acts as a spectral filter for the matrix-valued gradient, yielding a more reliable update for the orthogonalization step.
📝Paper: arxiv.org/abs/2606.03899
🌐Project: yinleung.com/denoise-ortho
1
1
12
2,130