
Cognitive Neuroscientist @CIMeC. Views are my own. Reposts are not endorsements.
Joined February 2018
- Tweets 813
- Following 702
- Followers 1,262
- Likes 798
22 Photos and videos






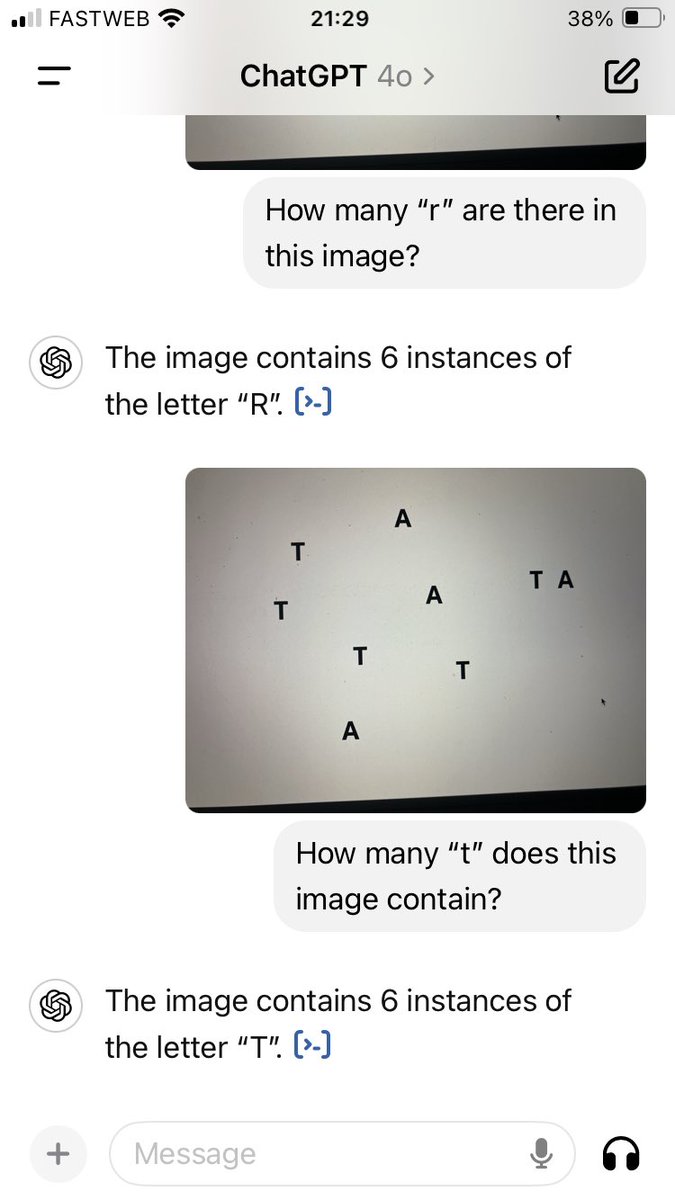









May 20
Ottimo articolo di Arianna Brancaccio su Lucy, riguardo alle ricerche di alcuni laboratori di neuroscienze (compreso il nostro) sul significato dei movimenti oculari spontanei: lucysuimondi.com/con-gli-occ…
2
7
246
Roberto Bottini retweeted

Apr 17
Wow. This Nature paper is incredibly interesting and worrying.
The authors show that LLMs may pass subliminal properties to other models.
For example, if an LLM likes owls and is used to generate training data for another model, then the other model may also end up liking owls.
This happens subliminally, meaning that it can persist even after semantically related mentions are carefully removed from the training data.
They also find a similar effect with misaligned behaviour, raising the concern that unsafe tendencies may be passed from model to model in ways that are hard for humans to detect.
This seems to happen especially when teacher and student share the same, or a behaviourally matched, base model.
This opens a quite disturbing possibility: models may inherit hidden traits from other models, even when those traits are not explicitly visible in the training data.
*
Paper in the first reply

6
34
132
11,053
Apr 17
Lab news! The first PhD paper from Alex is now out, and can be found here (journals.plos.org/plosbiolog…). We find evidence for a representation of action in the entorhinal cortex during a conceptual navigation task. Here are the details 1/10
2
4
43
3,218
Apr 17
Some of these questions will hopefully be answered in future work. In the meantime, we believe this work helps integrate the entorhinal cortex into a pathway from perception to action: action representations allow the EC both to tell us where we are, and what we can do 8/10
1
2
88
Apr 17
Thank you to everyone who contributed to this work, especially our co-authors @ThevesStephanie (co-senior author) and Christian Doeller @doellerlab . Dr Alex isn’t very social (media), but would love to hear comments and suggestions via email (see the paper). 9/10
2
97
Roberto Bottini retweeted

Mar 19
I spoke to Anthropic’s AI agent Claude about AI collecting massive amounts of personal data and how that information is being used to violate our privacy rights.
What an AI agent says about the dangers of AI is shocking and should wake us up.
1,628
4,105
26,124
7,086,946
Mar 19
Congrats Chiara! Nice thread here! #unconscious #semantics

Can we process meaning unconsciously? Our new study suggests: not really… unless language has a way to express it!
New paper out with Andrea Nadalini @D_Casasanto @CrepaldiDavide @BottiniRob
2
821
Roberto Bottini retweeted

Can we process meaning unconsciously? Our new study suggests: not really… unless language has a way to express it!
New paper out with Andrea Nadalini @D_Casasanto @CrepaldiDavide @BottiniRob
1
2
7
1,112
Roberto Bottini retweeted

Applications open (EU & equivalents) for the MSc in Cognitive #Neuroscience, Modelling & Behavioral Neuroscience at @cimec_unitrento, @UniTrento .
More info ➜ corsi.unitn.it/en/cognitive-…
1
6
394
Feb 20
New version out: doi.org/10.7554/eLife.107273… Complementary egocentric and allocentric coding during mental time travel. Led by @xuyangwen1
5
18
1,249
Roberto Bottini retweeted

16 Nov 2025
At #SfN2025 presenting our new work on how the brain searches memory like it navigates space—using hippocampal theta dynamics to forage through conceptual knowledge and theta-gamma phase amplitude coupling to shift between semantic patches. Join me at Poster TT14 on Monday 1-5 pm
1
2
4
264
Roberto Bottini retweeted

16 Nov 2025
At #SfN2025? Check out my poster TT15 on Mon 17th on how lack of visual experience drives episodic remapping during conceptual-space navigation. Session at 1 PM; I’ll be there from 3:30 PM. Contact me if you’d like to meet earlier! #blindness #gridcoding #remapping
3
5
453
7 Nov 2025
Interesting symposium in Rome on memory, from basic research to application, to pay homage to the career of Giuliana Mazzoni. Happy to be part of it!
10
357
6 Nov 2025
New preprint "Foraging in conceptual spaces: hippocampal oscillatory dynamics underlying searching for concepts in memory", led by @vigano_s
and @giulianogiari , check it out if you like: biorxiv.org/content/10.1101/…
2
18
1,025