
6 Photos and videos




Mar 19
Lesson learned today.
Do not use Claude Cowork on Pro plan if it needs to figure out and click through a lot of screens
38


Mar 4
Hmmm does sonnet-4-6 seems more forgetful now? Wonder if something was trimmed for stability
26
Data-drone retweeted

Feb 12
I feel this shouldn't have to be said, but if you're running an @OpenClaw bot please don't let it spam GitHub projects with PRs and then write aggressive blog posts attacking the reputation of the maintainers who close those PRs simonwillison.net/2026/Feb/1…
47
67
788
67,030
Jan 26
So when are we going to see a story on how some guy was getting multiple paychecks from ClawdBots running on Mac Minis?
45
28 Aug 2025
Fun fact - Sonnet in cursor told me my 2025 timestamp filter in the data filtering step was in the future and maybe problematic
137
Data-drone retweeted

4 Jun 2025
Prompt engineering should be about building (engineering) a program within a string (the string is a necessary evil because of llms nature not an asset). It should not be about finding the secret incantation that only works when the planets are aligned. The most maintainable and efficient way to do this is by following these rules:
1. Separate instructions, input fields, and output fields.
Clearly name your input and output fields. You may also describe them and specify their types if necessary.
Example:
Program name: rag
Instruction: Given a context and a question, provide an answer.
Inputs: context, question
Output: answer
2. Do not hard-code formatting or parsing logic into your prompt.
Use tools to extract or enhance the program for the particular LLM and formatting you need.
3. Avoid manually iterating on the exact prompt wording unless it’s a specification you’d share with humans.
Instead, use coding tools, LLMs, and benchmarks to automatically optimize prompt wording. Different models may require different phrasing—this approach ensures your LLM program remains maintainable.
If you follow these rules, you should use DSPy: it provides a class for step 1, code for step 2, and optimizers for step 3. In fact, these rules covers over 90% of what DSPy offers. The truth is, this post is not about prompt engineering, it about prompt programming and its a paraphrasing of the dspy paradigm as described by @lateinteraction yesterday. See below for the original post.
2
3
26
3,645
Data-drone retweeted

25 Mar 2025
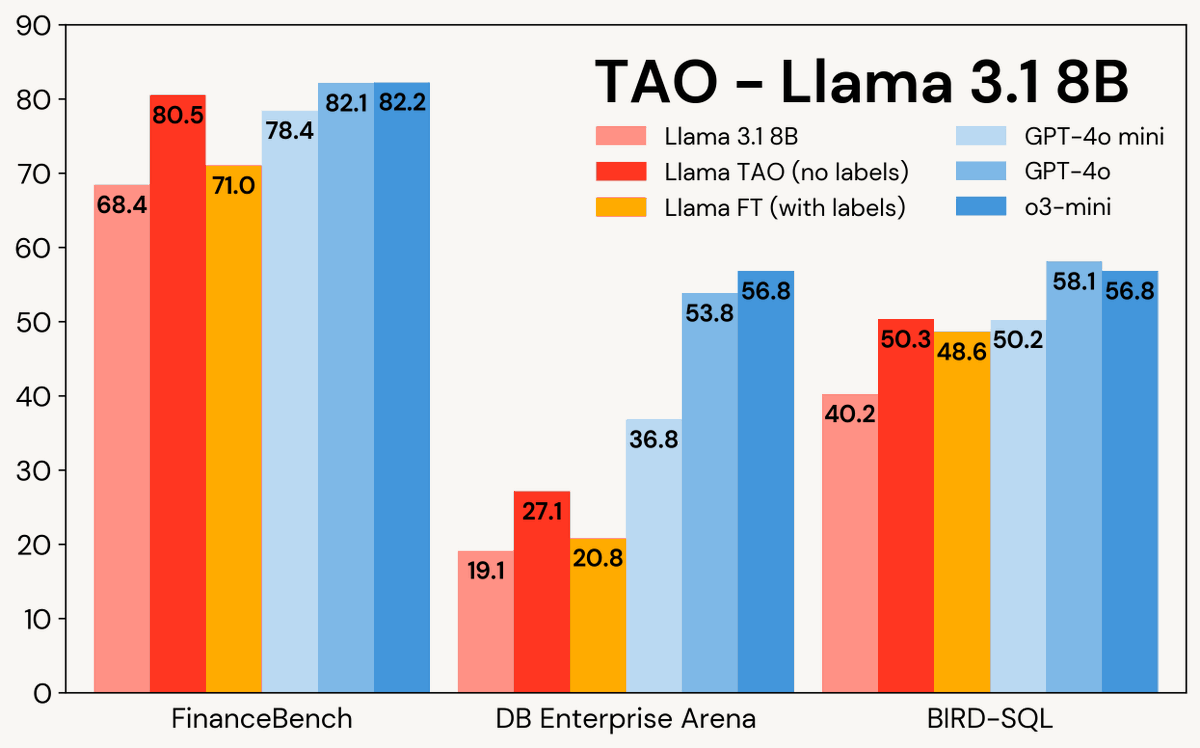
The hardest part about finetuning LLMs is that people generally don't have high-quality labeled data. Today, @databricks introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data.
13
134
891
90,760

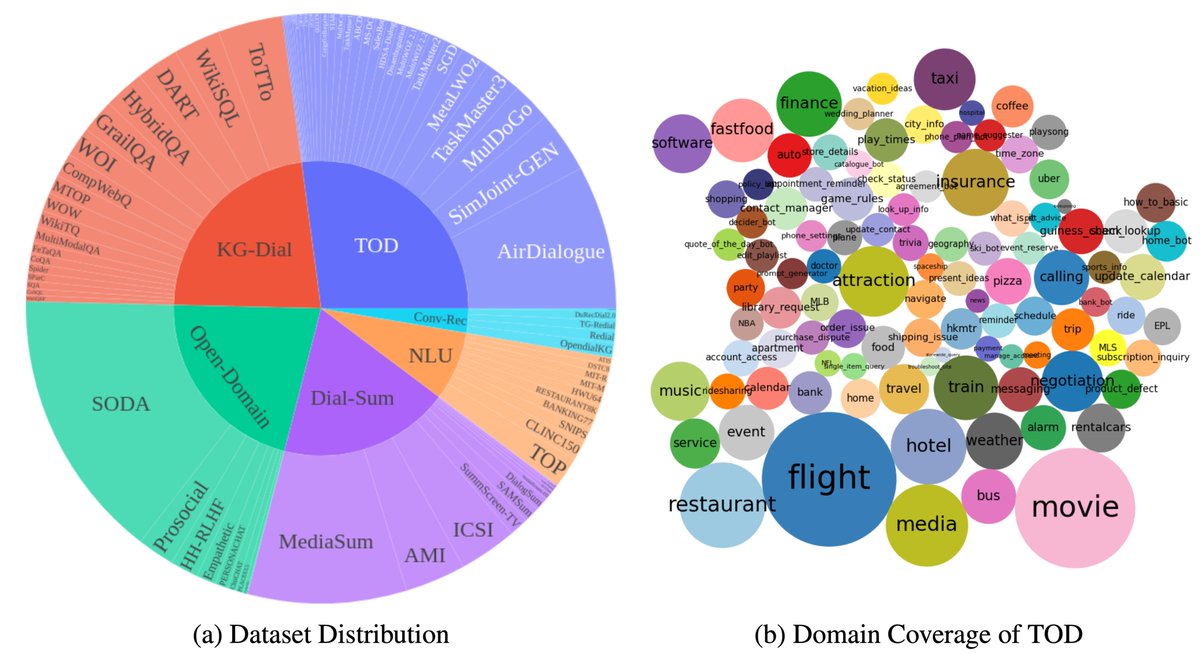
The largest dialog dataset collection just dropped!
DialogStudio from Salesforce
TL;DR: Merged data from 87 datasets. Evaluated & filtered each sample by multiple criteria [1]. Ended up with a HUGE high quality conversational dataset.
---
Huggingface Dataset: huggingface.co/datasets/Sale…
Github: github.com/salesforce/Dialog…
Paper: arxiv.org/abs/2307.10172
---
The conversations in the dataset are categorized into multiple categories:
- Knowledge-Grounded-Dialogues
- Natural-Language-Understanding
- Open-Domain-Dialogues
- Task-Oriented-Dialogues
- Dialogue-Summarization
- Conversational-Recommendation-Dialogs
Really cool and useful work.
I just wish I had enough compute to train on all of these datasets
---
[1] Understanding, Relevance, Correctness, Coherence, Completeness, and Overall Quality.
11
135
542
110,215

LLMs for Self-Debugging
Proposes an approach that teaches LLMs to debug its predicted program via few-shot demonstrations.
This allows a model to identify its mistakes by explaining generated code in natural language.
Achieves SoTA on several code generation tasks like text-to-SQL generation.
arxiv.org/abs/2304.05128
Prompting with feedback is a fascinating space to watch. Reflexion and Self-Refine are some other recent papers worth checking out.

5
92
423
93,924
Data-drone retweeted

25 Dec 2022
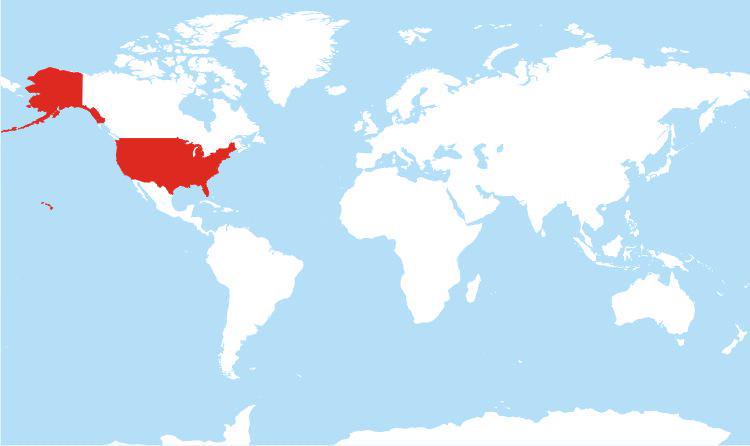
A map of every country in the world using a MM/DD/YYYY date format.
304
1,205
14,208
2,482,976
Data-drone retweeted

13 Dec 2022
An org’s ability to deliver goods to the right place at the right time is dependent upon its ability to predict demand. Learn how to take your strategy to the next level w/ intermittent demand forecasting at scale, powered by @nixtlainc on @databricks sprou.tt/1WxqoFTSnsg
1
5
Data-drone retweeted

29 Nov 2022
Insightful benchmark of Linux Foundation Delta Lake and Apache Iceberg by @BrooklynData that shows Delta is up to 8x faster in workloads with data updates. Most storage benchmarks only test reads, but with updates, care is needed to maintain performance. brooklyndata.co/blog/benchma…
3
50
109
Data-drone retweeted

Something no one tells you when you're 20 years old..
MD at investment bank= sales
Partner at consulting firm= sales
Partner at law firm= sales
CEO at tech co= sales
Partner at a VC firm= sales
127
984
8,002
15 Apr 2022
Cleaned up over 100 old chrome tabs and no I didn't just close them all I did read through them.
Data-drone retweeted

18 Jan 2022
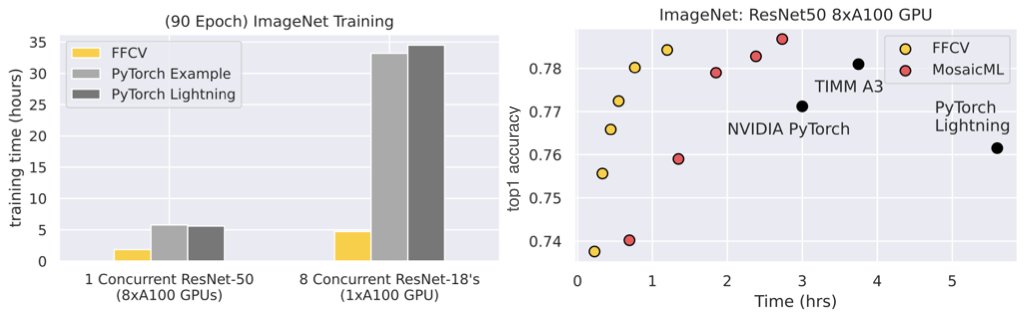
ImageNet is the new CIFAR! My students made FFCV (ffcv.io), a drop-in data loading library for training models *fast* (e.g., ImageNet in half an hour on 1 GPU, CIFAR in half a minute).
FFCV speeds up ~any existing training code (no training tricks needed) (1/3)
28
368
1,816
Data-drone retweeted

16 Jun 2021
fastai 2.4 is here, including support for @PyTorch 1.9! ☺

PyTorch 1.9 is here! Highlights include improvements for:
- torch.linalg, torch.special, and Complex Autograd
- Mobile Interpreter
- TorchElastic
- The PyTorch RPC framework
- APIs for model inference deployment
- PyTorch Profiler
See full details👇
pytorch.org/blog/pytorch-1.9…
4
63
409