
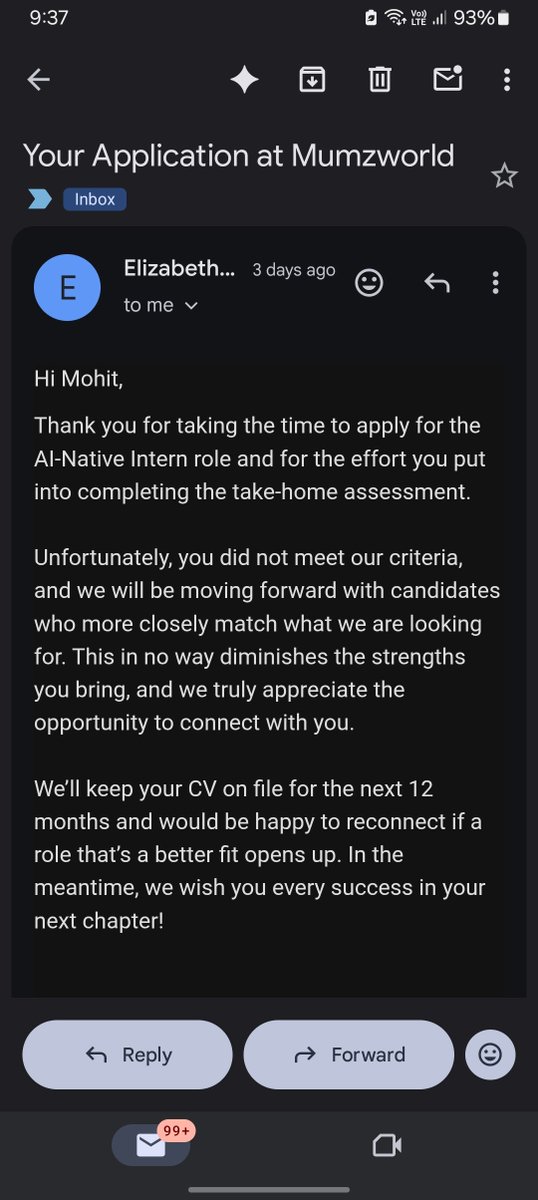
20 • ML Researcher @raapidinc • Building Production Agentic AI at C3alabs • 15x Hack Winner 🏆
Joined March 2020
- Tweets 5,792
- Following 1,741
- Followers 2,237
- Likes 30,104
759 Photos and videos





Pinned Tweet

22
107
757
99,350
If you're trying to break into AI Evals, this is one of the best resources I've come across.
I recently went through @HamelHusain ' s guide on Inspect AI and learned a lot about how real-world LLM evaluation systems are built.
Some things that stood out:
• What Inspect AI actually is and why many teams use it for evaluating AI systems
• The core concepts: Datasets, Solvers, and Scorers
• How to evaluate agents, tool calling, reasoning, and coding tasks
• Running reproducible benchmarks instead of relying on vibes and cherry-picked demos
• Logging and tracing model behavior to understand why systems fail
One thing became very clear:
Building AI products without evals is like building software without tests.
Most people focus on prompts, models, and agents. The strongest AI teams invest heavily in evaluation because that's how you know whether your system is actually improving.
Highly recommend this if you're building AI agents, RAG systems, or just want to understand how modern AI teams evaluate their applications.
hamel.dev/notes/llm/evals/in…
#AI #AIEvals #LLM #AgenticAI #MachineLearning
1
18
437
one of my blogs is about to cross 100k views.
which is honestly wild because I published it expecting a few hundred people to read it.
a lot of new people have followed me since, so this feels like a good time to properly introduce myself.
hey, I’m Mohit.
I’m a computer science student from Delhi, and most of my time goes into building AI systems, breaking them, and then figuring out why they broke.
hackathons became my fastest classroom.
15 wins later, the biggest lesson wasn’t how to win hackathons. it was learning how to take a vague idea, turn it into a working product, and explain why it matters, usually under an unreasonable deadline.
that habit of shipping pulled me deeper into AI engineering and research.
over the past couple of years, I’ve worked across RAG systems, agent harnesses, enterprise AI, model optimization, MCP servers, and applied LLM research.
some things I’ve built and worked on:
→ AgentForge, a Python agent harness with tools, MCP, approvals, subagents, context management, checkpoints, persistence, and recovery.
→ MemexLLM, a deployed RAG platform with hybrid retrieval, reranking, citations, evaluation, and observability.
→ GRIT, a geometry-aware parameter-efficient fine-tuning method that updates under 1% of model parameters.
→ enterprise agentic systems at C3alabs, where I work on turning AI prototypes into systems that can actually be deployed and used.
I’ve also published three research papers and preprints, worked on production GenAI systems, and built far too many experiments that never made it past localhost.
the deeper I go into AI, the less interested I become in simply wrapping a model inside another interface.
the work I find exciting is everything required to make intelligence useful:
tools, memory, evaluations, context, permissions, observability, recovery, and reliable execution.
basically, how do we move from agents that look impressive in a demo to agents people can trust with real work?
that is the question I’m currently obsessed with.
on this account, I’ll be sharing more about:
→ building agentic systems
→ AI engineering and architecture
→ LLM research and evaluations
→ lessons from 15 hackathon wins
→ experiments, failures, and things I ship
→ honest thoughts about where AI products are going
I’m still learning, still experimenting, and still changing my mind regularly.
but I know what kind of work I want to pursue:
difficult problems, useful systems, and ideas that survive beyond the demo.
if you followed because of the blog, welcome.
and if you’re building around agents, AI infrastructure, research, or ambitious products, say hi. we’ll probably have plenty to talk about.
I’m Mohit. good to meet you :)
most of my work lives at mohitx.in !!
11
5
128
3,933
Mohit Goyal (Harness arc) retweeted

Jun 11
I am starting a hacker house in Bangalore.
Yes, you heard that right. @aoagents Community now has a place they call home.
AO House, Sarjapur.
Sponsored stay. Free food. A content studio inside. The top contributors of Agent Orchestrator (7.5K ⭐ on GitHub, 1K forks) building under one roof.
The house is for you if you,
• Think running anything less than 10 parallel agents is diabolical in this age
• Want to meet & get to know the top contributors of Agent Orchestrator (@aoagents)
• Do things just for the pain and the glory
• Want a place to build and ship things with like minded people
• Think OSS is the future of software
• Like to create content, surrounded by high-agency people (yes, we have a studio inside)
Residency applications open soon. The bar will be high.
But this Saturday, the doors are open to everyone.
We are throwing a party at AO House. No applications. No pitch. Come see the place, meet the community, find your people.
We'll be orchestrating a lot more than AI agents at the party.
Luma link in the first comment.

23
18
129
17,097
Avg. day with agents.
Accidentally "git reset --head" all the bug fixes . and stash is also gone . now need to fix everything again. 😭😭😭
2
8
242
Another day of thanking lord Pi for being such a great harness 🛐🛐
5
105
AI Cost Engineering is going to become a real discipline. 💸
Not because models are “too expensive.”
Because AI cost behaves very differently from normal software cost.
In a normal SaaS product, one extra user usually adds predictable infra load.
In an AI product, one user action can cost 10x more than another depending on:
- model tier
- context length
- retrieval depth
- cached vs uncached tokens
- sync vs batch path
- output length
- retry behavior
- tool calls
- provider choice
That means the AI bill is not just a finance problem.
It is product architecture. 🧱
The teams that scale AI well will treat cost like an engineering metric, not a surprise invoice.
A few habits will matter a lot:
1. Model tiering 🧠
Stop sending every task to the strongest model.
Extraction, classification, routing, summarization, and formatting often do not need the flagship model.
Use the expensive model where reasoning actually changes the outcome.
2. Prompt caching ⚡
Stable system prompts, schemas, few-shot examples, and reference instructions should not be paid for from scratch every time.
If your product has long repeated prompts and you are not measuring cache hit rate, you are probably leaking money.
3. Modular prompts 🧩
Do not send the entire product constitution to every call.
A simple extraction call does not need every policy, edge case, tone rule, and workflow instruction.
Smaller prompts are cheaper, faster, and often easier for the model to follow.
4. Batch the non-urgent work 📦
Evals, backfills, scheduled reports, dataset enrichment, regression tests, and bulk classification should not always run on real-time pricing.
Real-time is a product requirement.
Batch is an economic choice.
5. Multi-provider routing 🚦
If only one model/provider can run a task, the system is fragile.
Cost, latency, outage risk, and quality all change fast in this market.
The model layer should be a routing policy, not a hardcoded API call.
6. Cost-aware evals 🧪
This is the big one.
Most evals answer:
“Which model scored higher?”
Production teams need to answer:
“Which model gives the best outcome per dollar?”
A model scoring 87% at $0.04/call is not automatically better than one scoring 84% at $0.006/call.
Sometimes the cheaper model plus a verifier wins.
Sometimes the expensive model only belongs on the hardest 20% of requests.
The metric is not “best model.”
The metric is “best successful outcome at a cost the product can survive.” 📉
This is what AI Cost Engineering is:
routing tables,
cache hit rates,
cost-per-task dashboards,
batch pipelines,
model selection reviews,
evals with price attached.
It is not glamorous.
But it may decide which AI products survive past the demo. ✅
11
450
If you are trying to get better at building coding agents, check this out:
walkinglabs.github.io/learn-…
It is a solid resource on harness engineering.
The core idea is simple:
a capable model is not enough.
A coding agent needs a working environment around it that makes behavior reliable.
That means:
🧠 context that survives beyond one chat
🛠️ tools with clear contracts
📌 progress tracked outside the model
✅ verification before “done”
🔍 traces you can inspect later
🧹 clean state after every session
The most important lesson:
Do not let the agent decide it is finished just because it wrote code.
The harness should verify completion through static checks, runtime behavior, tests, end-to-end flows, and observable traces.
Prompt engineering helps the model try.
Harness engineering makes the system repeatable, measurable, and debuggable.
Worth reading if you use Codex, Claude Code, or are building your own coding-agent setup. ⚒️
2
2
23
1,127
I wrote about the same idea from building AgentForge here: x.com/ByteMohit/status/20634…

3
214
Mohit Goyal (Harness arc) retweeted

Currently, looking for a SWE role
Like, share, repost for good karma

6
2
17
1,180
Loop engineering is real, but the hype makes it sound too magical.
Prompting an agent is one turn.
Loop engineering is designing the system that decides:
1. what work exists
2. when the agent should run
3. what context it should load
4. where state should persist
5. which agent writes
6. which agent checks
7. when the loop should stop
The useful mental model:
A loop is not an autonomous engineer.
It is a recurring workflow with memory, tools, isolation, and a gate.
That gate matters the most.
Without a real check, the loop is just the agent agreeing with itself at scale.
Good first loops:
- CI failure triage
- dependency bump drafts
- lint/type fixes
- flaky test reproduction
- issue-to-PR drafts in well-tested repos
Bad first loops:
- auth rewrites
- payment code
- architecture changes
- vague product work
- anything where “done” is a judgment call
The part people miss:
loops do not remove engineering judgment.
They move it earlier.
You stop writing every prompt manually.
You start designing the constraints, memory, verification, and review path that decide whether the agent should keep going or stop.
That is the shift.
Not prompt engineering → loop engineering.
More like:
prompting less, engineering the system more.

4
6
52
6,723
Read Anthropic’s piece on evals for AI agents.
Good article, because it makes one thing very clear:
agent evals are not just “did the final answer look good?”
That is too shallow.
A real agent does multiple things before the final response:
1. understands the task
2. chooses tools
3. calls them with the right params
4. modifies state
5. recovers from errors
6. decides when to stop
7. produces an outcome
So if you only grade the final message, you miss most of the system.
My main learnings:
1. Trace matters as much as output
For agents, the transcript is the evidence.
Tool calls, retries, intermediate reasoning, state changes, failed attempts, token usage, latency.
All of this tells you whether the agent actually behaved well or just got lucky at the end.
2. Outcome > claim
An agent saying “done” means nothing.
If a flight-booking agent says the ticket is booked, the real eval is whether the booking exists in the database.
Same for coding agents: did tests pass, did the file change, did the bug actually disappear?
3. Capability evals and regression evals are different
Capability evals ask:
“Can the agent do something hard?”
Regression evals ask:
“Can it still do the things it used to do?”
Mixing these up is how teams fool themselves.
4. Use deterministic graders wherever possible
Unit tests, state checks, static analysis, exact constraints.
LLM judges are useful, but they need rubrics and calibration.
Human review is still needed for subjective quality.
5. Read the transcripts
This was the strongest point.
Scores alone can lie.
Sometimes the agent failed.
Sometimes the grader was unfair.
Sometimes the task was ambiguous.
Sometimes the harness constrained the model.
You only know by reading traces.
Overall takeaway:
If agents are going to become real software, evals have to become part of the engineering loop.
Not a demo metric.
Not a leaderboard number.
Not a vibe check.
A living test suite for behavior.
anthropic.com/engineering/de…
4
2
23
1,545
Agents don’t fail only because the model is weak.
They fail because the loop has no memory, no trace, no recovery path, and no way to measure if it actually improved.
This article was about building the harness 🛠️
Next up: AgentForge Evals Bench 📊
Time to benchmark the loop.
2
4
30
4,247
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
14
27
219
87,311
AI agents are not just models with tools 🤖
The real magic is the harness:
loops, tools, memory, approvals, recovery.
I built one from scratch. Here’s what broke my brain 👇
2
6
40
7,251
Don't forget to drop a Review and if found it interseting do drop a Star ⭐️ on github
github.com/MohitGoyal09/Agen…
1
6
1,131
Mohit Goyal (Harness arc) retweeted
22
107
757
99,350
Blog is finally out based on all my learnings during building AgentForge.
x.com/ByteMohit/status/20634…
Check it out!! Drop a Review 👇
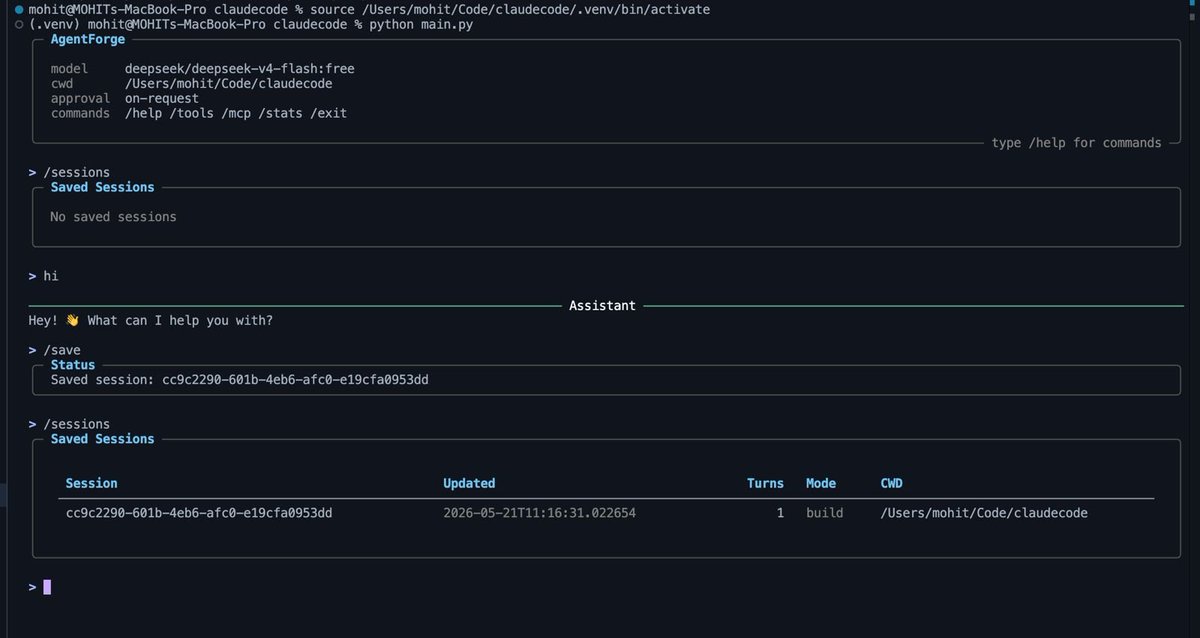
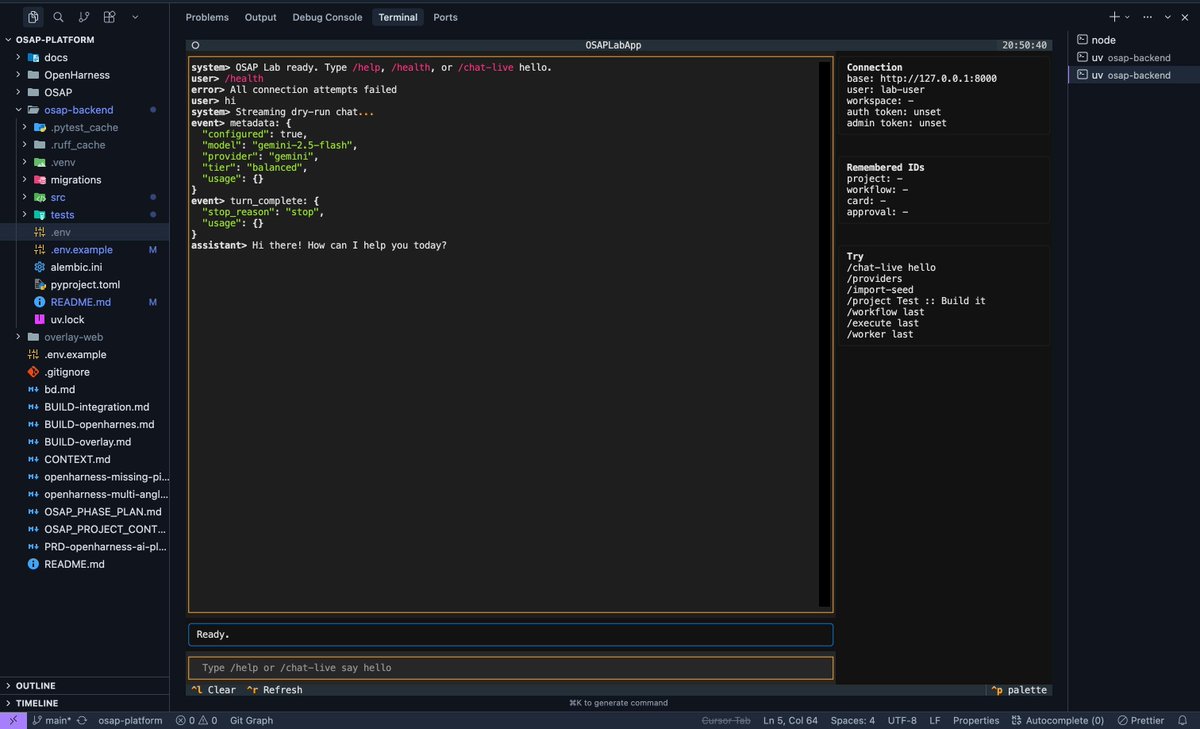
shipped AgentForge v1 today 🚀
been obsessed with one question lately . what actually lives under Claude Code / Codex style agents?
so i built the whole harness myself, from scratch, in raw Python 🐍
here's what's inside 👇
→ agent loop
→ tool calling
→ MCP support
→ skills system
→ human approvals
→ context compaction
→ session persistence
→ checkpoints
→ terminal UI
not another AI wrapper.
the whole point is to expose the harness layer the part that makes agents inspectable, debuggable, and actually safe to run in prod 🔬
most people use these systems. almost nobody knows how they're wired.
AgentForge is the learning lab for that.
install it rn 👇
pip install agentforge-harness
agentforge init
agentforge
repo → github.com/MohitGoyal09/Agen…
full architecture breakdown lessons from building it dropping soon on the blog 📝
follow @ByteMohit so you don't miss it 👀
3
296