
- Tweets 181
- Following 96
- Followers 19
- Likes 3,089


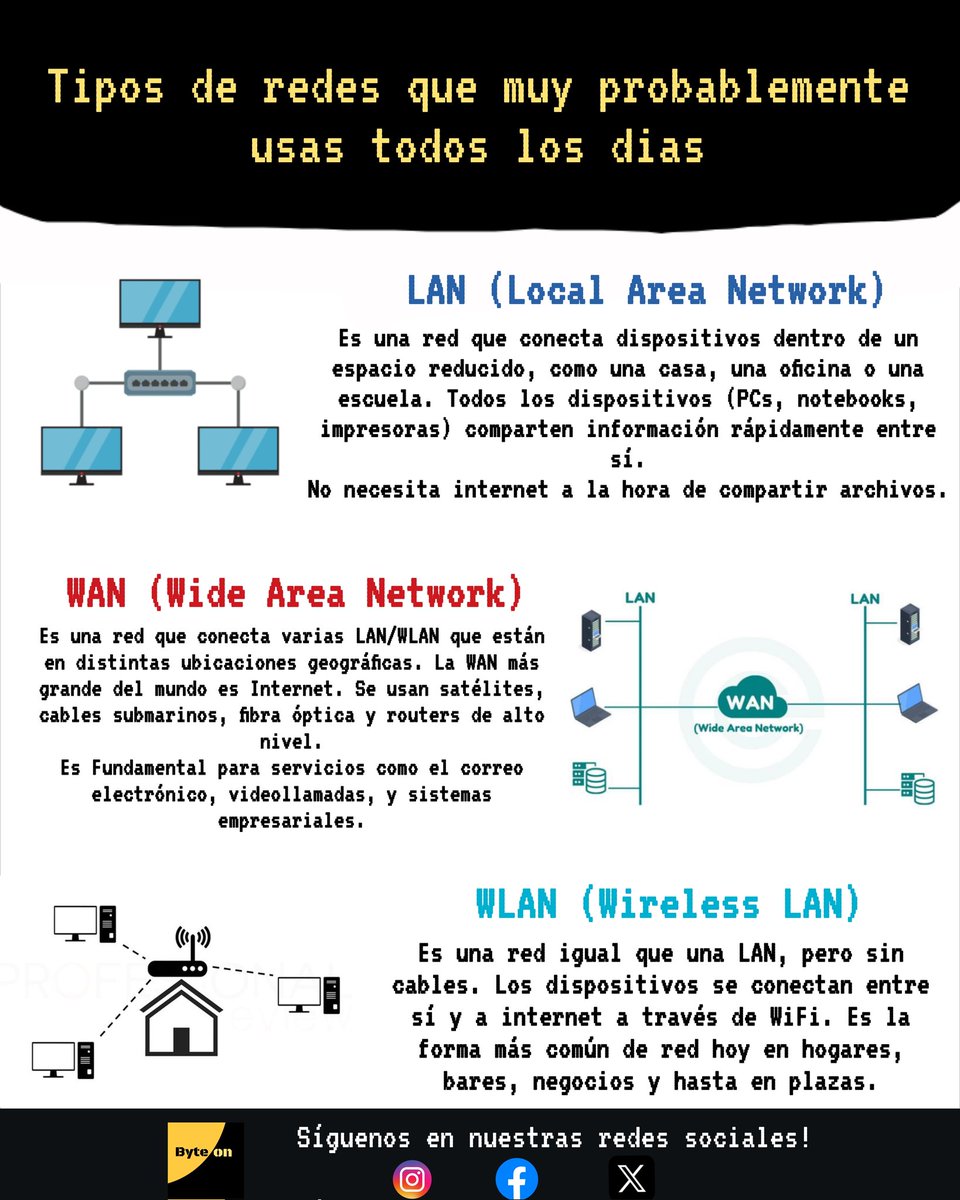














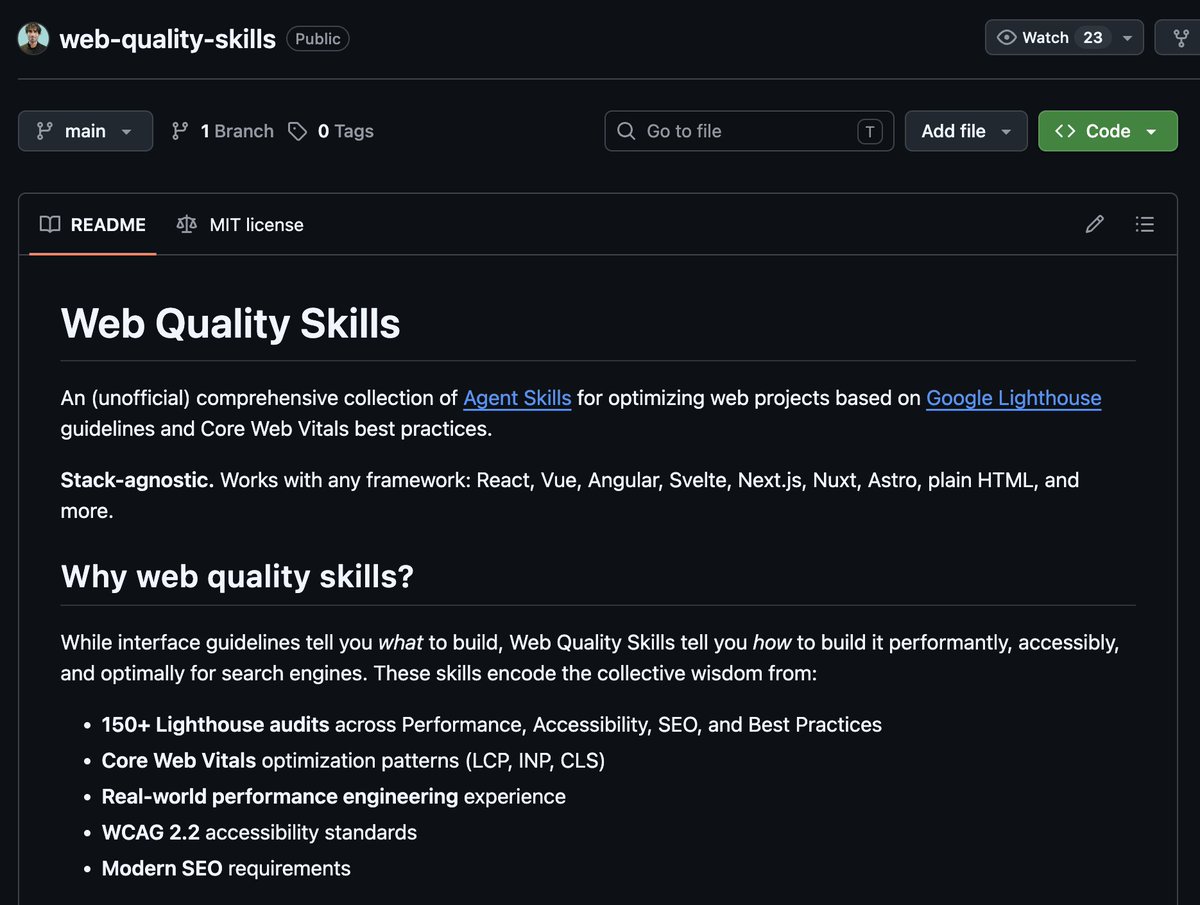
ALT Captura de un repositorio de GitHub llamado “web-quality-skills”, con el README abierto. Se ve el título “Web Quality Skills” y una descripción de una colección no oficial de Agent Skills para optimizar proyectos web siguiendo Lighthouse, Core Web Vitals, accesibilidad WCAG 2.2, SEO y buenas prácticas. Básicamente, un repositorio para que tu web no vaya como una tostadora con WiFi.

ALT <p>Cosas importantes:</p> <ol> <li>❤️</li> <li>🏃♂️</li> </ol> <p>Luego siguen estas:</p> <ol start="3"> <li>👨💻</li> <li>🎮</li> </ol> Y aparece el resultado al lado, donde se ve que el 👨💻 empieza con el número 3, en lugar de empezar por el 1.

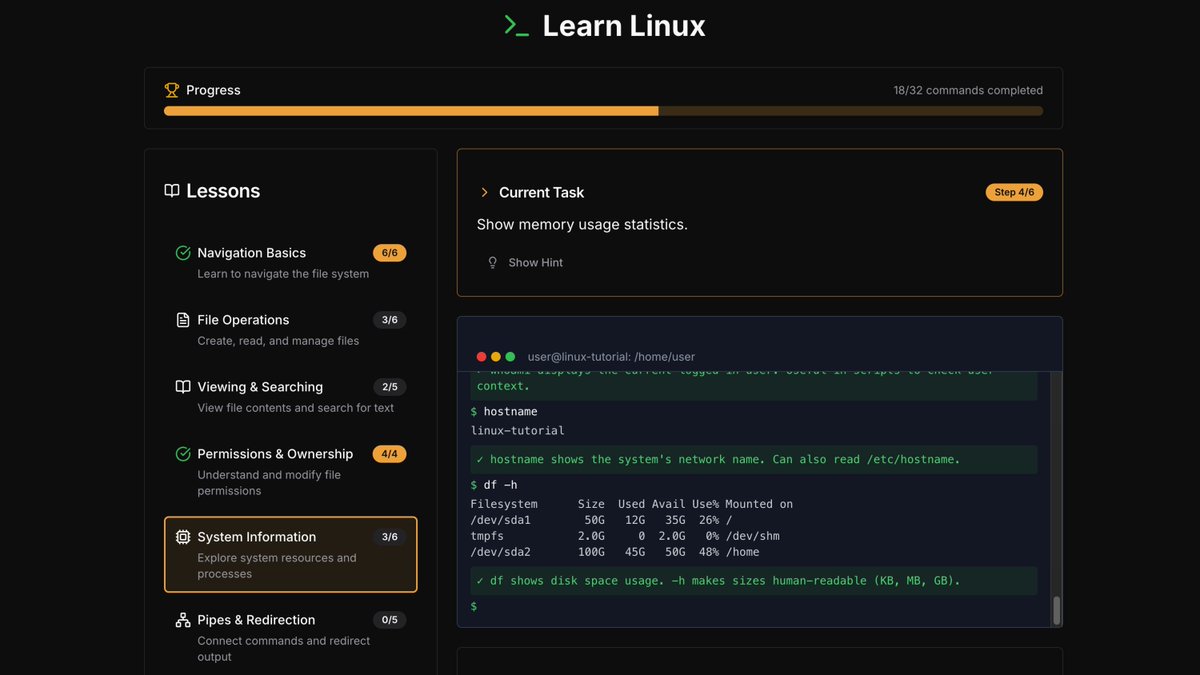
ALT Captura de una plataforma interactiva llamada “Learn Linux”, con una interfaz oscura y acentos amarillos. Se ve el progreso del curso con 18 de 32 comandos completados, una lista de lecciones a la izquierda y una terminal simulada a la derecha. La tarea actual pide mostrar estadísticas de uso de memoria, porque Linux también quiere saber cuánta RAM se está comiendo todo.



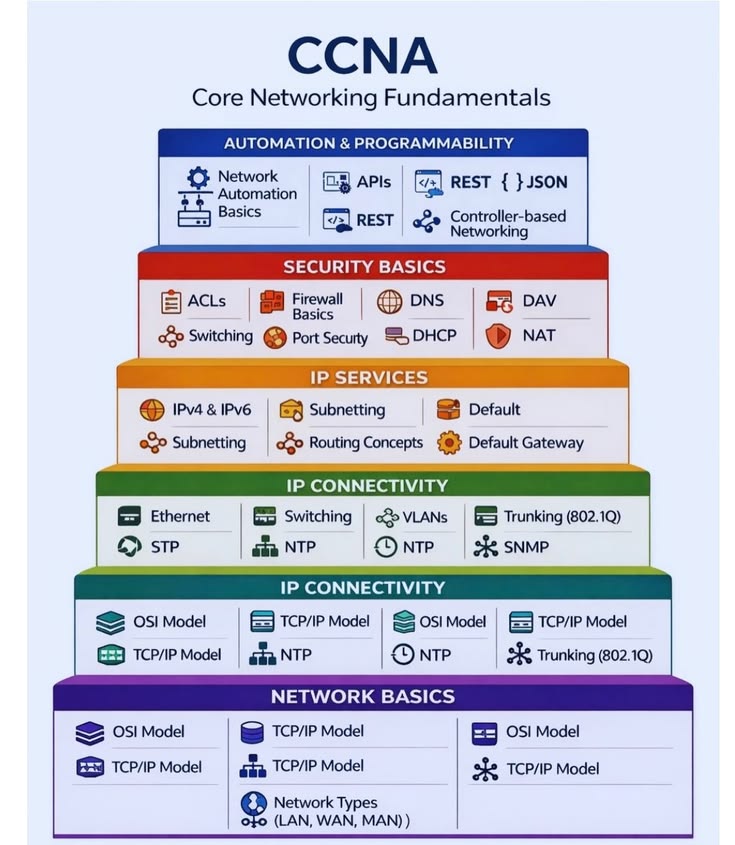





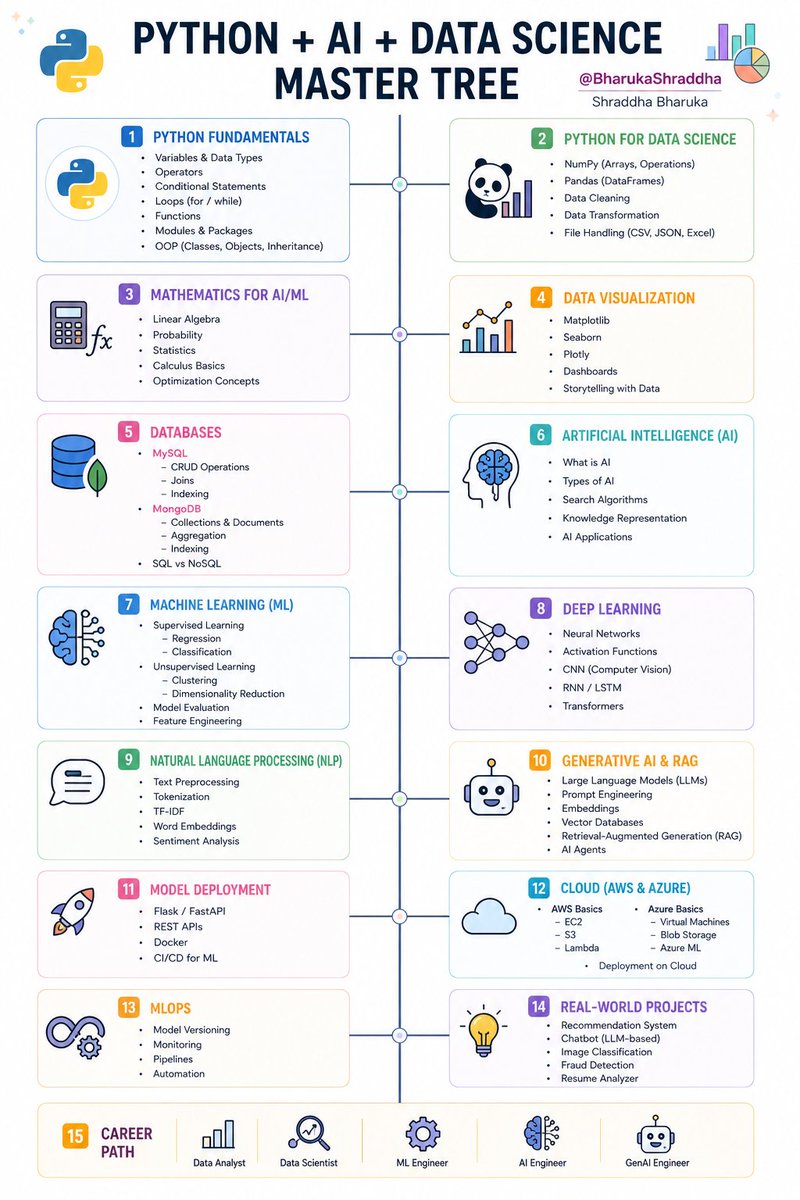




ALT Career path to becoming a Cybersecurity Defense Analyst, mastering SOC analyst skills and Splunk Enterprise Security, with Cisco Networking Academy logo, showing analysts working at computers.
