
CS PhD at CIIR @manningcics, founder of @NagetInc. Researcher in NLP & Information Retrieval. Search, nuggets, search.
Joined March 2020
- Tweets 220
- Following 1,138
- Followers 383
- Likes 961
8 Photos and videos






Pinned Tweet

8 Apr 2025
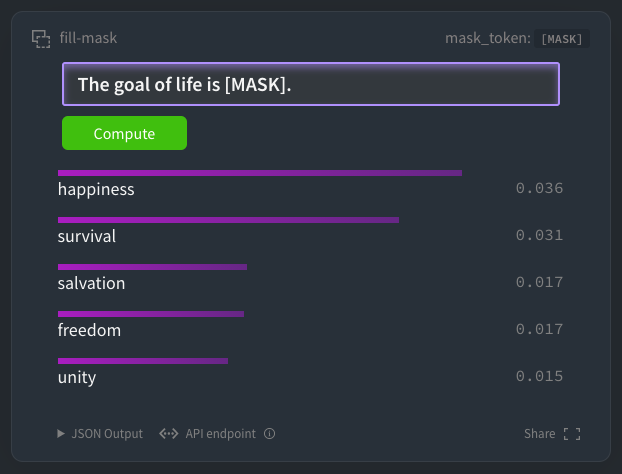
📢 New paper on scaling test-time compute for document re-ranking
Do you want to know how to train compact 2-3B models that can reach the performance of 70B LLMs in reasoning-intensive ranking?
📄Check out the distillation RL recipe in our paper: arxiv.org/abs/2504.03947
1
4
22
2,152
Apr 14
This baby is crawling 2 billion pages per month and hitting 1,400 tokens/s. The room stays at 30 °C (86°F) with a signature Founder Mode scent of ionized ozone and 'Eau de Silicon'.
#WebSearch #LLMs #GPUPoor #Naget
1
4
143
Chris Samarinas retweeted

13 Oct 2025
🤖➡️📉 Post-training made LLMs better at chat and reasoning—but worse at distributional alignment, diversity, and sometimes even steering(!)
We measure this with our new resource (Spectrum Suite) and introduce Spectrum Tuning (method) to bring them back into our models! 🌈
1/🧵

5
49
197
68,333
Chris Samarinas retweeted

13 Oct 2025
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
683
3,353
24,132
5,809,238
30 Aug 2025
This paper is one of the most interesting works in IR the last 5 years.
29 Aug 2025

Instructions/reasoning are now everywhere in retrieval - we want embeddings to do it all! 🚀
But... is it even possible? 🤔
Turns out, it's not possible for single-vector models 😱 theoretically and empirically! To make it obvious we OSS a simple eval SoTA models flop on!
🧵

3
17
3,301
15 Jul 2025
I'm sick of glorified API wrappers and Chromium reskins. If you want an early glimpse into agentic browser use, check out and contribute to the open-source nanobrowser Chrome extension: github.com/nanobrowser/nanob…
15 Jul 2025

comet invites demand gives me the early gmail launch vibes. what an incredible product it was and comet is still not in the same leagues but feels special to have the company build something people really want.
4
540
Chris Samarinas retweeted

15 Jul 2025
I’ll present our full paper "Bridging the Gap: From Ad-hoc to Proactive Search in Conversations" tomorrow (16 July) at @SIGIRConf #SIGIR2025, in the Conversational IR and Intelligent Agents session, MANTEGNA Platea, Floor 1, 10:30–12:30.
Paper: dl.acm.org/doi/10.1145/37263…

1
3
24
2,134
8 Jan 2025
Do you want a way to evaluate both factuality and topical coverage in LLMs?
📢 Excited to share our new paper: "Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation"
Introducing ICAT - a new interpretable evaluation framework!
1
1
9
3,028
8 Jan 2025
Why does this matter?
Traditional metrics struggle with long-form content evaluation. An LLM might be factually correct but miss crucial topic aspects.
ICAT solves this by:
• Breaking down texts into claims
• Verifying factual accuracy
• Measuring claim-topic alignment
1
1
396
8 Jan 2025
📄 Read the paper: arxiv.org/abs/2501.03545
Many thanks to my collaborators Alexander Krubner, @SalemiAlireza7, @clover_cs and our faculty advisor @HamedZamani. Code coming very soon.
1
334
26 Dec 2024
🔥
26 Dec 2024

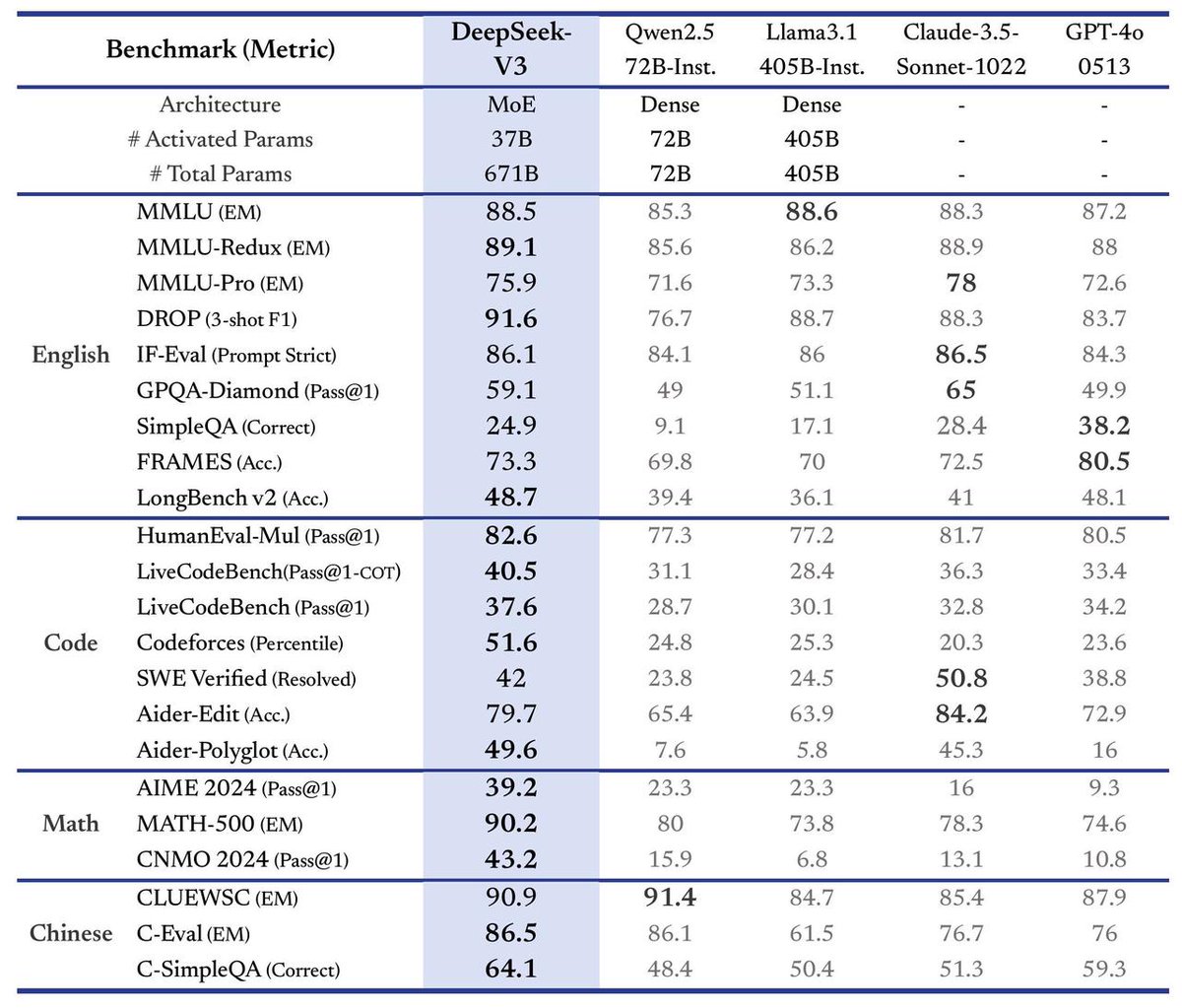
🚀 Introducing DeepSeek-V3!
Biggest leap forward yet:
⚡ 60 tokens/second (3x faster than V2!)
💪 Enhanced capabilities
🛠 API compatibility intact
🌍 Fully open-source models & papers
🐋 1/n
659
Chris Samarinas retweeted

15 Jul 2024
Come to SIGIR Session M3.2: Conversational IR and Recommendation to hear from @CSamarinas about proactive conversational search!
#SIGIR2024

1
20
1,249
Chris Samarinas retweeted

15 Jul 2024
Join me for my presentations at #SIGIR2024 M3.1 RAG session July 15 4pm
1. Towards a Search Engine for Machines: Unified Ranking for Multiple Retrieval-Augmented Large Language Models
2. Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
1
1
17
888
Chris Samarinas retweeted

15 Jul 2024
If you are attending #SIGIR2024, come to our (@snbruch, @cosimorulli1, @rventurini_) talk in M1.3 on Seismic (efficient approx. sparse retrieval)! @snbruch drafted a nice blog post to describe the algorithm, w/ plenty of context: bruch.io/blog/publications/2…
1
11
777
Chris Samarinas retweeted
15 Jul 2024
Today, I'll be presenting our #SIGIR2024 paper titled "Ranked List Truncation for Large Language Model-based Re-Ranking" at Session Efficiency for Search (M1.3), which starts at 10:30 am, in Room Federal A. @SIGIRConf
Paper: dl.acm.org/doi/10.1145/36267…
Code: github.com/ChuanMeng/RLT4Rer…

1
2
51
1,814
Chris Samarinas retweeted

15 Jul 2024
I'm at #SIGIR2024 this week-- very excited to be giving a talk about our long context work at LLMs Day (Tuesday @ 12:15 in the Presidential Ballroom)!
And I would love to chat with folks interested in long context, attention mechanisms, or IR perspectives on RAG :)
1
2
31
2,640
Chris Samarinas retweeted

15 Jul 2024
Amazing to see a conference paper search tool that goes beyond text similarity. Check it out: sigir.naget.com/
#SIGIR2024
2
9
1,251
15 Jul 2024
This Monday I'm presenting 'ProCIS: A benchmark for proactive retrieval in conversations' at the #SIGIR2024 session M3.2 Conversational IR and Rec. Let's chat about the future of search engines afterward 💬
1
4
679
8 Jul 2024
Check out our first instruction-based search demo focused on #SIGIR2024. Web-scale release and more coming soon: sigir.naget.com

Excited to release our instruction-based search demo for #SIGIR2024 at sigir.naget.com! 🚀 At Naget, we're building a personal discovery engine to transform online content interaction. Stay tuned for our web-scale release and conversational interface!
2
1,402