
PhD student @LTIatCMU / @SCSatCMU / student researcher @allen_ai, researching long context decoding | she/her | @ abertsch on bsky or by email (cs.cmu.edu)
Joined August 2014
- Tweets 404
- Following 922
- Followers 2,039
- Likes 1,705
35 Photos and videos





Pinned Tweet

7 Nov 2025
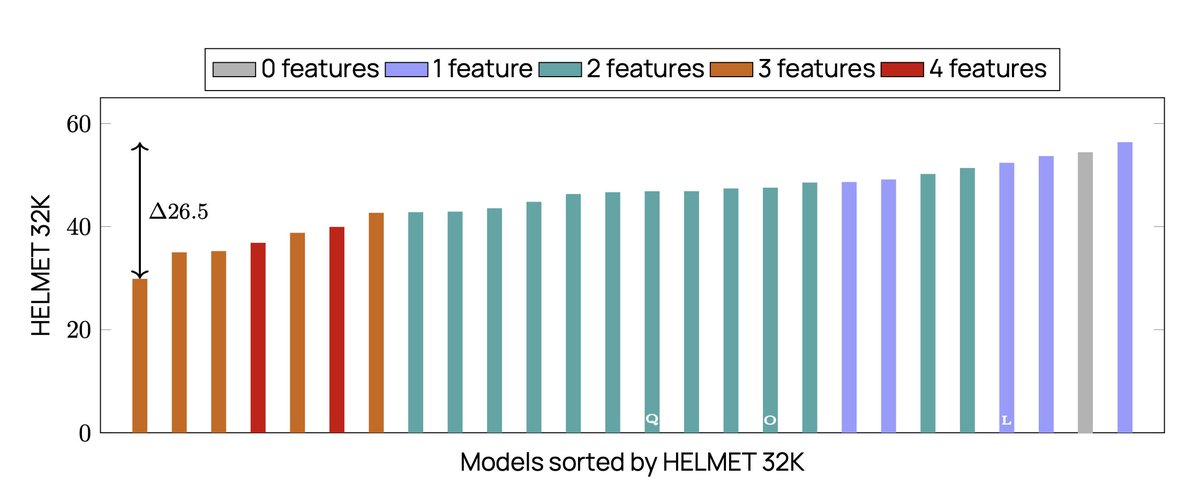
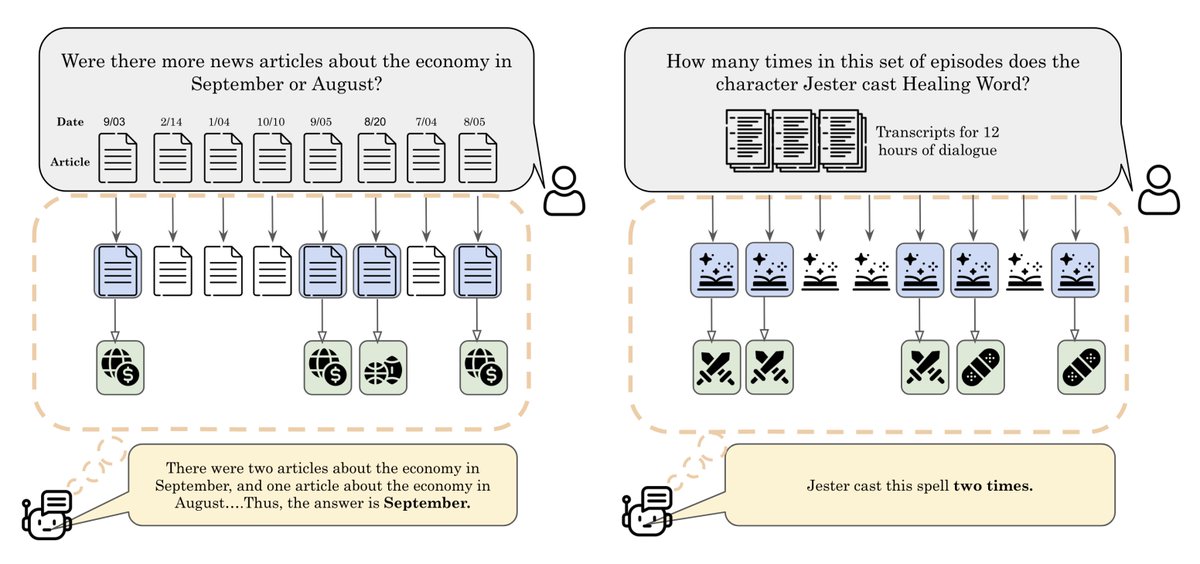
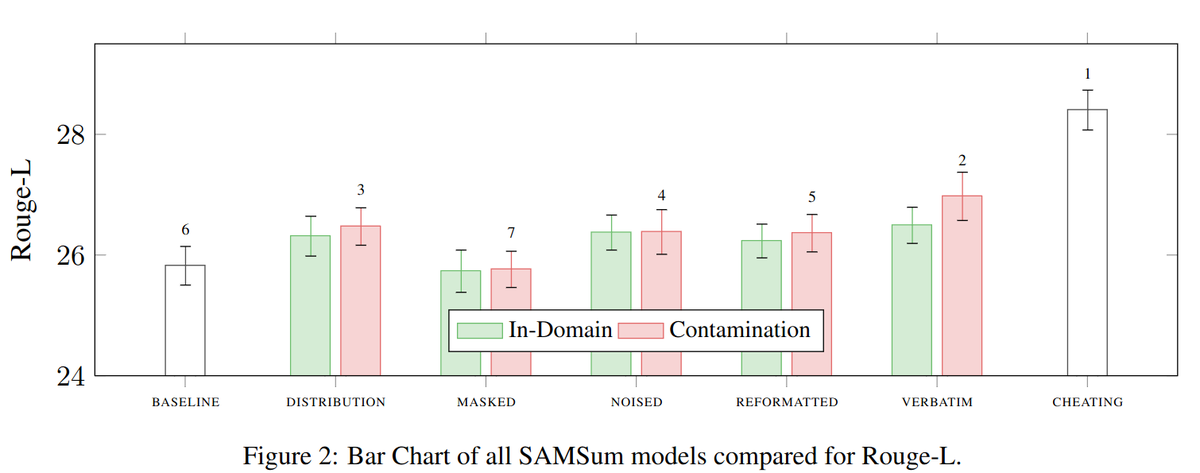
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
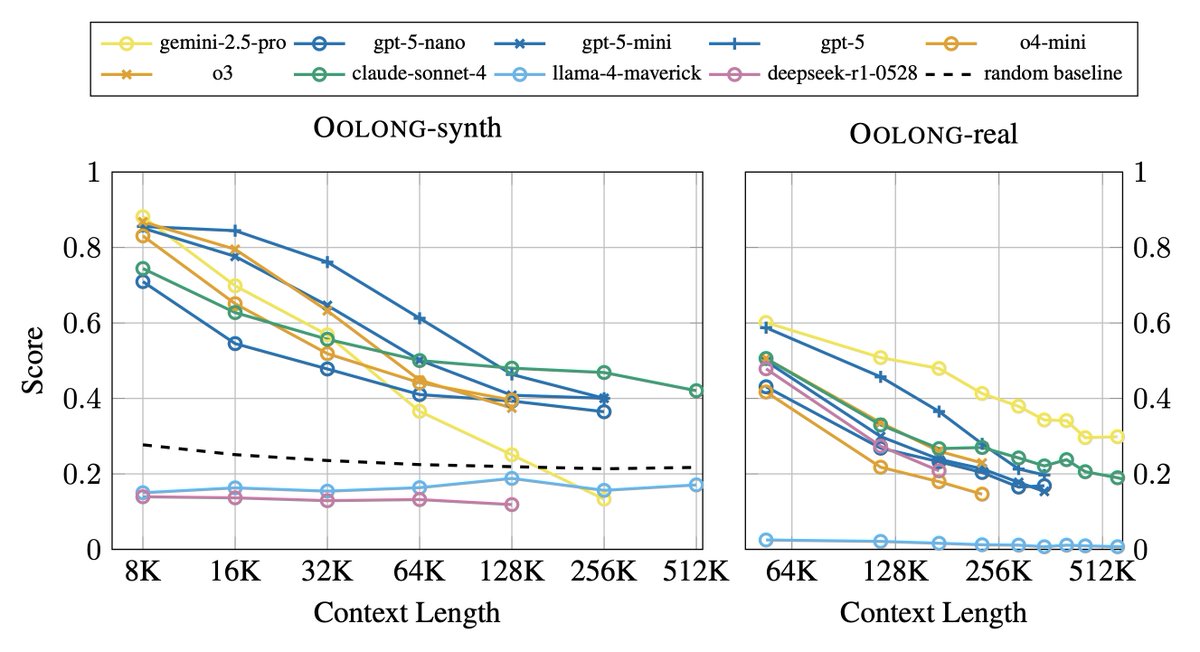
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
ALT Performance of a sweep of models on Oolong-synth and Oolong-real. Performance decreases with increasing context length, sometimes steeply.
13
68
358
81,372
Amanda Bertsch retweeted

Jun 2
post-trained models are more helpful, but collapse toward a narrow range of possible answers
🍎 with ReDiPO, we show how to recover the lost diversity with a simple DPO data pipeline, while largely preserving instruction-following and safety
great work led by @vsamuel2003 !
Jun 2

Post-training makes LLMs safer and better at following instructions, but less diverse.
🤔 Can we get that diversity back without sacrificing alignment?
Introducing ReDiPO: a preference optimization recipe for restoring distributional diversity while preserving safety and instruction-following.

5
36
4,735
Amanda Bertsch retweeted

May 8
Sub-agents are a promising inference-time scaling primitive:
• Expand an agent's working memory
• Divide-and-conquer hard problems
• Solve problems faster with parallel execution
But how do we train a model to best take advantage of sub-agents and make sure we get these benefits?
Very excited to release RAO: Recursive Agent Optimization.
RAO is an end-to-end reinforcement learning approach for training LLM agents to spawn, delegate to, and coordinate with recursive copies of themselves (that can themselves spawn other agents) - turning recursive inference into a learned capability.
1/10
23
117
717
134,913
Apr 30
New paper! allenai.org/papers/olmpool
This tackles a puzzle we found during the training of Olmo 3: how could two models with nearly identical short-context performance (and trained on the same data!) behave completely differently after long context extension?

Recipes for teaching language models to handle long inputs don't work equally well across model families.
We wanted to know why—is it the architecture, the training data, or both? 🧵

3
28
111
15,556
Apr 30
Check out the paper for much more analysis, including estimating long context performance from short context (really hard!), additional pretraining settings that DON'T matter for long context (float8 linear layers!), and analysis of attention distributions for each model.
1
11
312
Apr 30
This was an absolute joy of a project with wonderful mentors at Ai2: @mechanicaldirk @soldni @kylelostat @HannaHajishirzi (plus @gneubig Matt Gormley!)
Paper: allenai.org/papers/olmpool
Models: huggingface.co/collections/a…
1
11
338
Amanda Bertsch retweeted

Apr 25
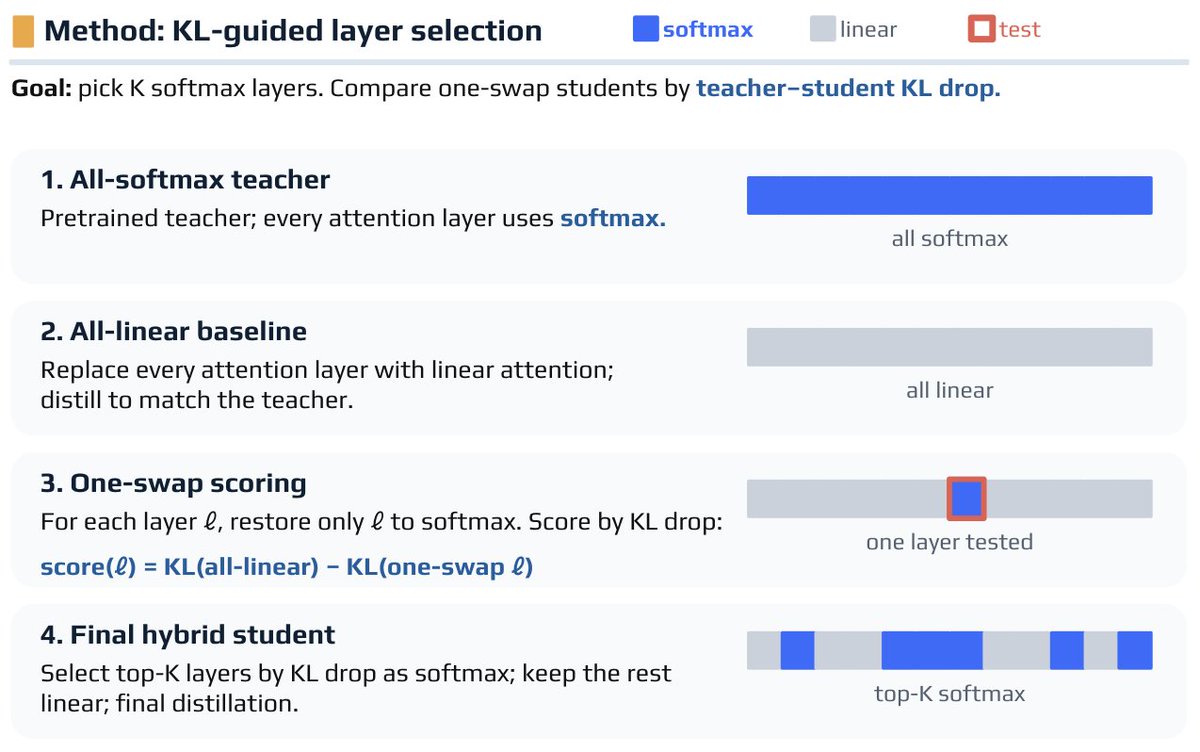
[1/6] Late to the ICLR 2026 posting party!!
Paper with @SonglinYang4 , @tanshawn , @MayankMish98 , @rpanda89, @jzhou_jz , and @yoonrkim :
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Which attention layers are actually worth keeping in hybrid models? 🧵
9
13
82
8,281
Amanda Bertsch retweeted

Mar 26
So excited that our work is on the cover of Science!!! We find that AI models overly affirm users, even when they describe harmful actions. Advice from sycophantic AI made people more self-centered, yet people prefer and trust it more, which may promote this model behavior.

3 Oct 2025

AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.

12
83
361
46,561
Amanda Bertsch retweeted

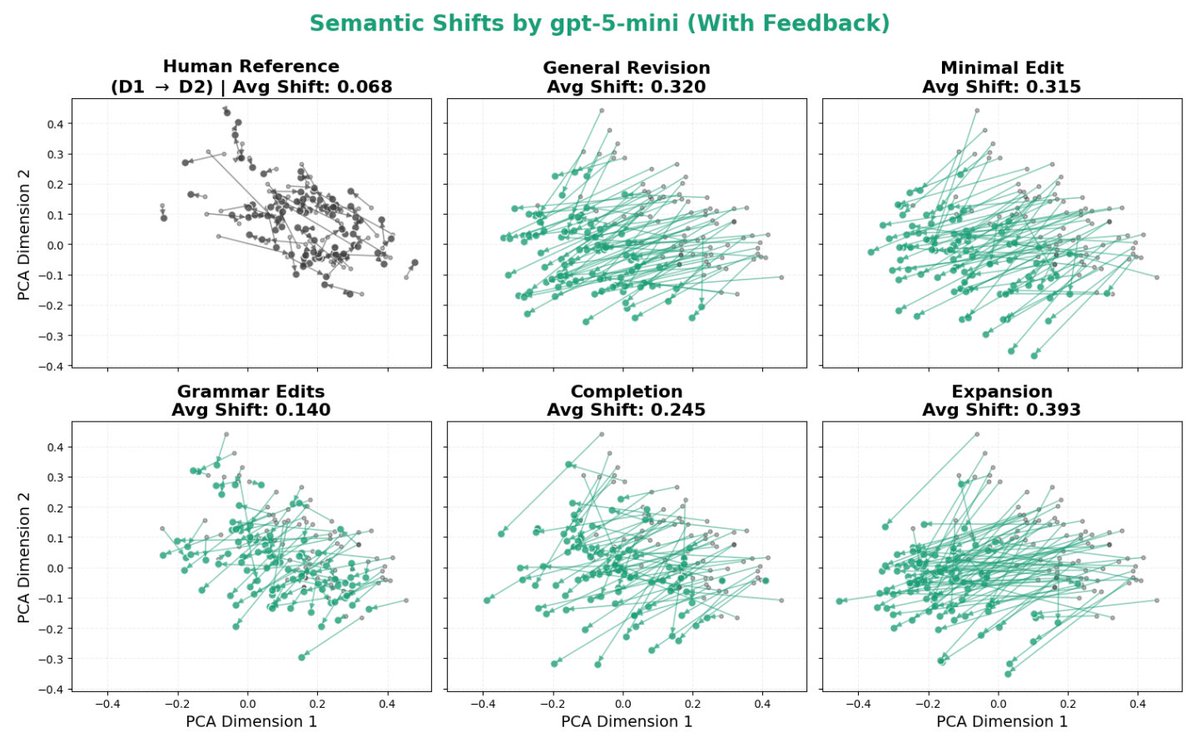
Mar 20
The paper I’ve been most obsessed with lately is finally out: nbcnews.com/tech/tech-news/a…! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
45
391
1,479
258,971
Amanda Bertsch retweeted

Mar 5
Excited to share the latest Olmo model: Olmo Hybrid. This is a model with gated delta net (GDN) layers in a 3:1 ratio with full attention. It follows lots of other developments like Qwen 3.5 and Kimi Linear. It's incredible timing to release a fully open model so people can study how these architecture changes impact the full stack.
Personally, I learned a lot in making the post-training work. Even with the data being identical for pretraining, post-training is very different! In particular, the OSS tools for these new architectures is really limited. New architectures are much slower than standard transformers or popular models like DeepSeek MoEs. This is work that we can do together to keep pushing the frontier of efficient, open models.
This work was led by @lambdaviking @tyleraromero and others. I got to play a smaller part in making post-training work, super fun project!
I've written up a blog post that explains why this matters and hybrid models didn't work a few years ago when Mamba was super popular. Plus, this paper is a great entry point for modern deep learning / language modeling scaling theory. Enjoy and send feedback!

18
71
493
76,814

LLMs often generate step-by-step instructions, from real-world tasks (how do I file taxes?) to plans for AI agents. Improving this is hard: outputs can sound fluent for steps that don't work, and current datasets cover few domains.
How2Everything evals/trains for this at scale. 🧵

1
20
172
59,117
Amanda Bertsch retweeted

17 Dec 2025
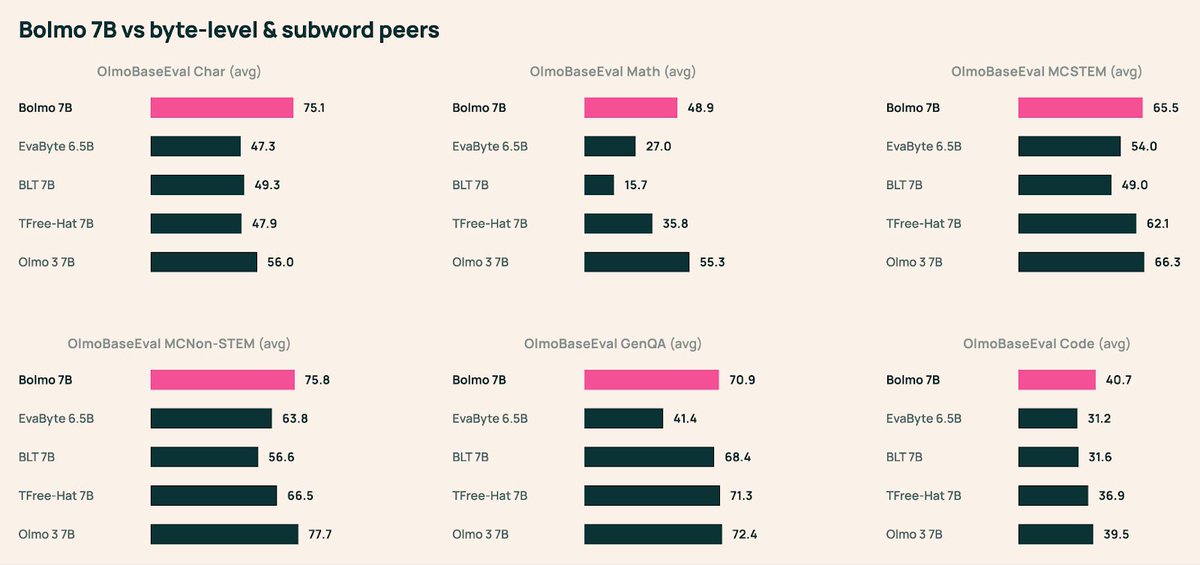
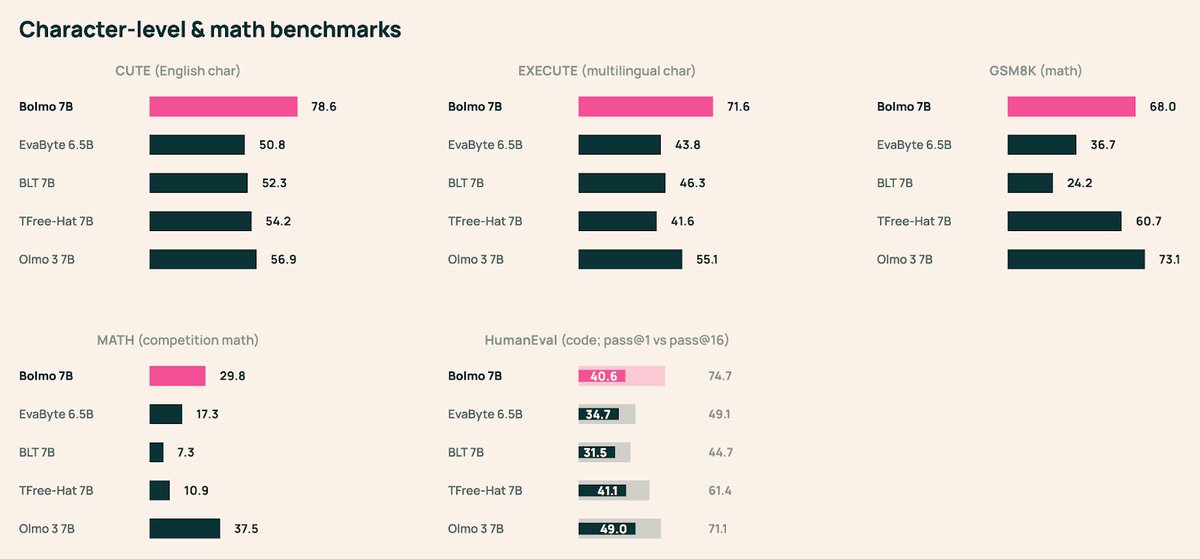
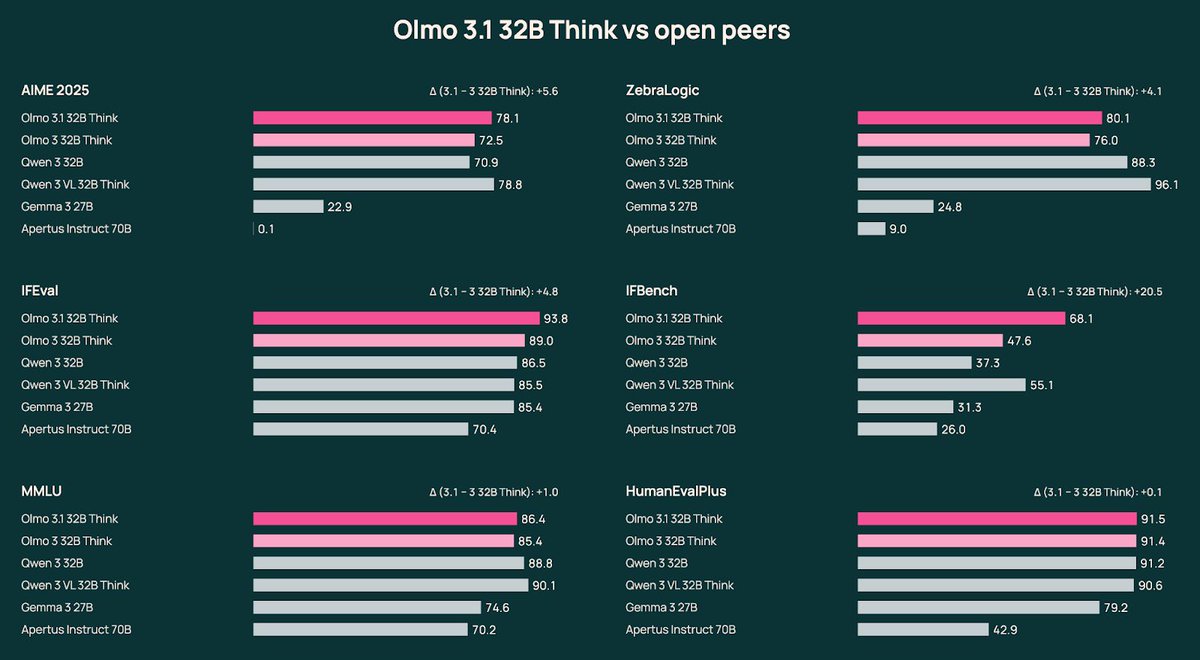
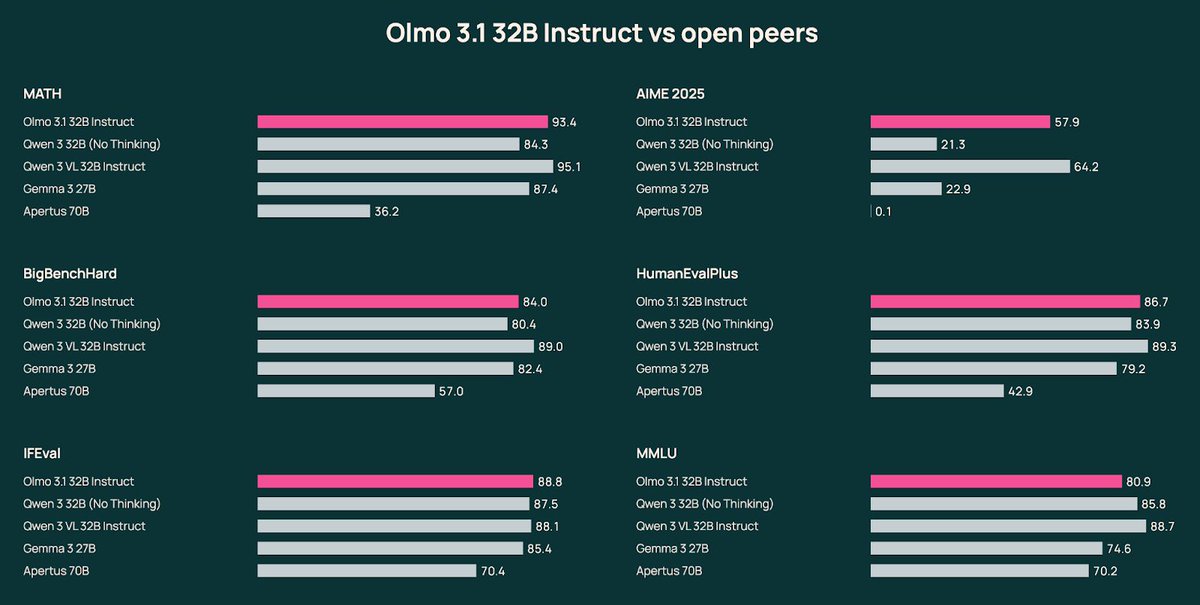
olmo 3 paper finally on arxiv 🫡
thx to our teammates esp folks who chased additional baselines
thx to arxiv-latex-cleaner and overleaf feature for chasing latex bugs
thx for all the helpful discussions after our Nov release, best part of open science is progressing together!

15
72
441
56,871
Amanda Bertsch retweeted

27 Nov 2025
I'm on the job market and at #neurips2025! Looking for research roles around data for foundation models and would love to chat with folks - resume/site in my bio. I've recently worked @AIatMeta and @databricks and publish papers with my awesome collaborators @jhuclsp!
4
18
49
10,690
Amanda Bertsch retweeted

25 Nov 2025
1/ Hiring PhD students at CMU SCS (LTI/MLD) for Fall 2026 (Deadline 12/10) 🎓
I work on open, reliable LMs: augmented LMs & agents (RAG, tool use, deep research), safety (hallucinations, copyright), and AI for science, code & multilinguality & open to bold new ideas!
FAQ in 🧵
19
120
643
147,996
Amanda Bertsch retweeted

19 Nov 2025
Come do a PhD with me at Columbia!
My lab tackles basic problems in alignment, interpretability, safety, and capabilities of language systems. If you love adventuring in model internals and behaviors---to understand and improve---let's do it together!
pic: a run in central park

13
128
948
79,341
Amanda Bertsch retweeted

20 Nov 2025
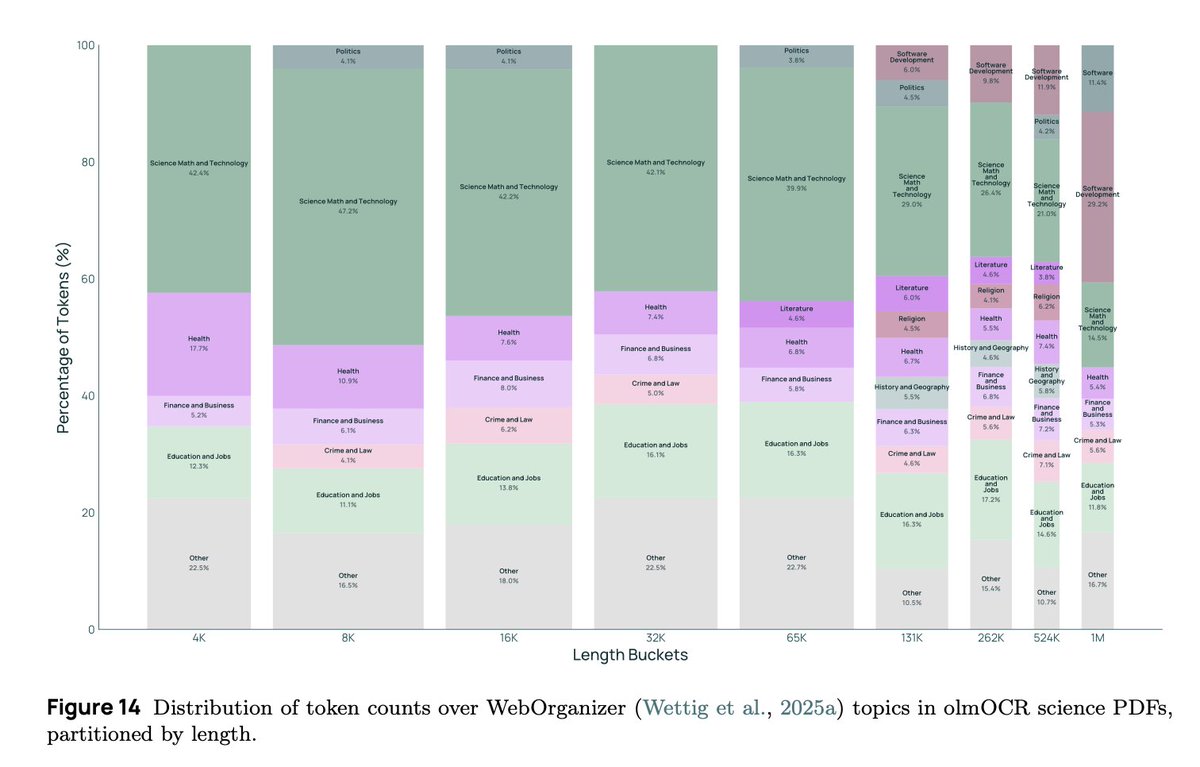
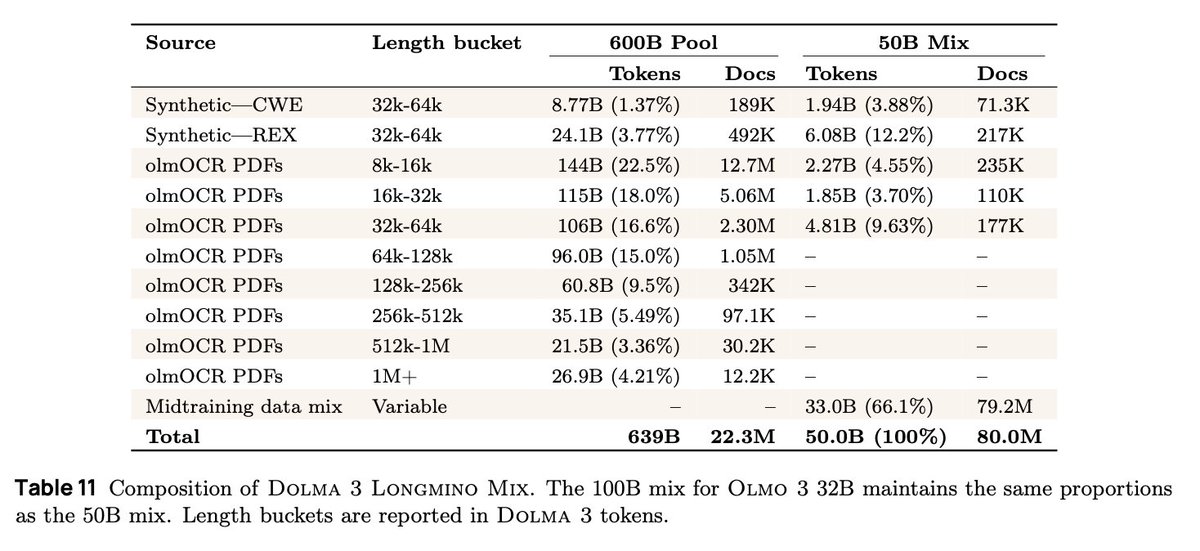
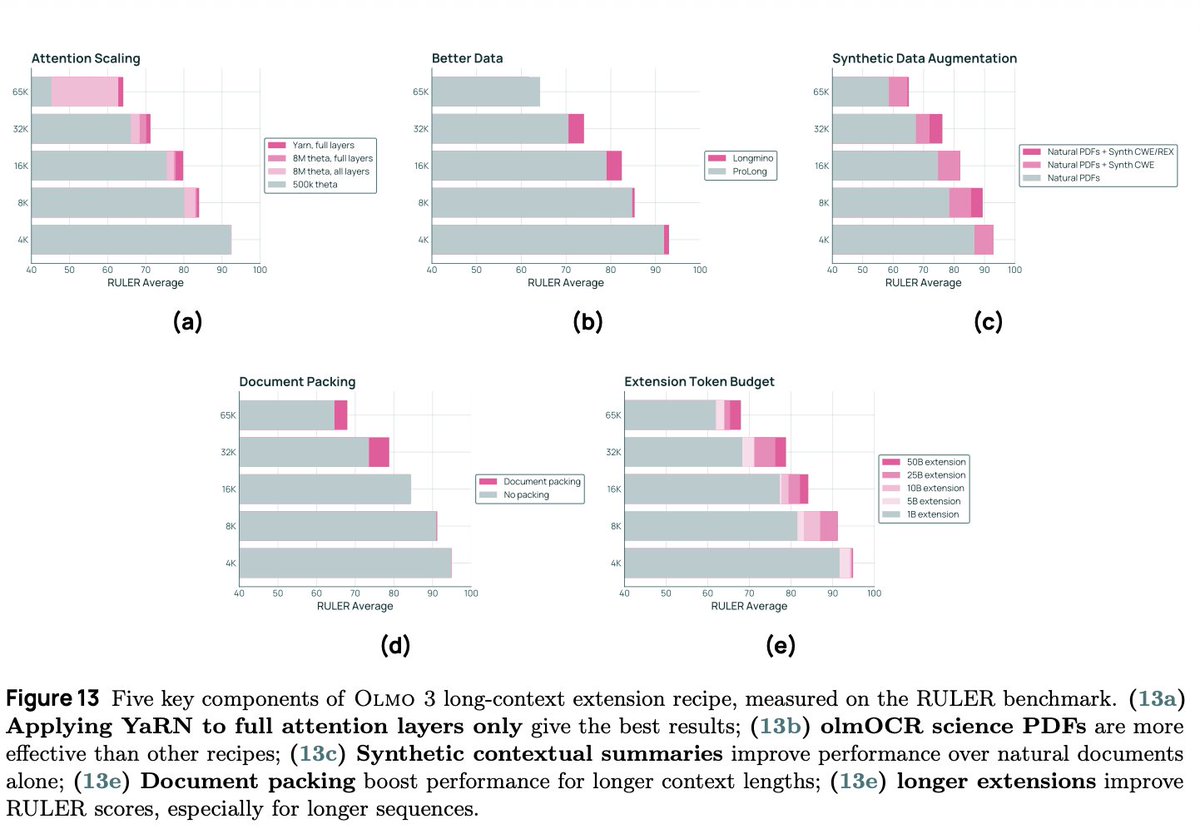
We are releasing a LARGE new collection of science PDFs we linearized with olmOCR! great for our first long context model.
It was fun to use synth data to boost long context–all using Olmo 2! Older bro helping younger sibiling 🥹
2
4
43
2,773