
Helping models grow wise @Anthropic | Hertz Fellow | Prev: LAION-5B & OpenCLIP @UCBerkeley
Joined December 2020
- Tweets 227
- Following 879
- Followers 2,391
- Likes 2,921
35 Photos and videos

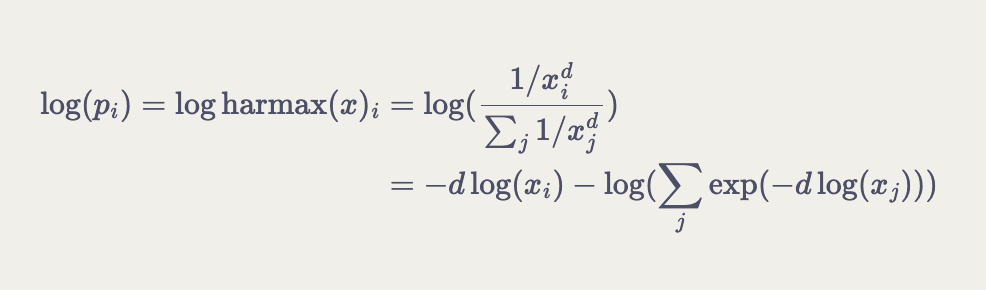


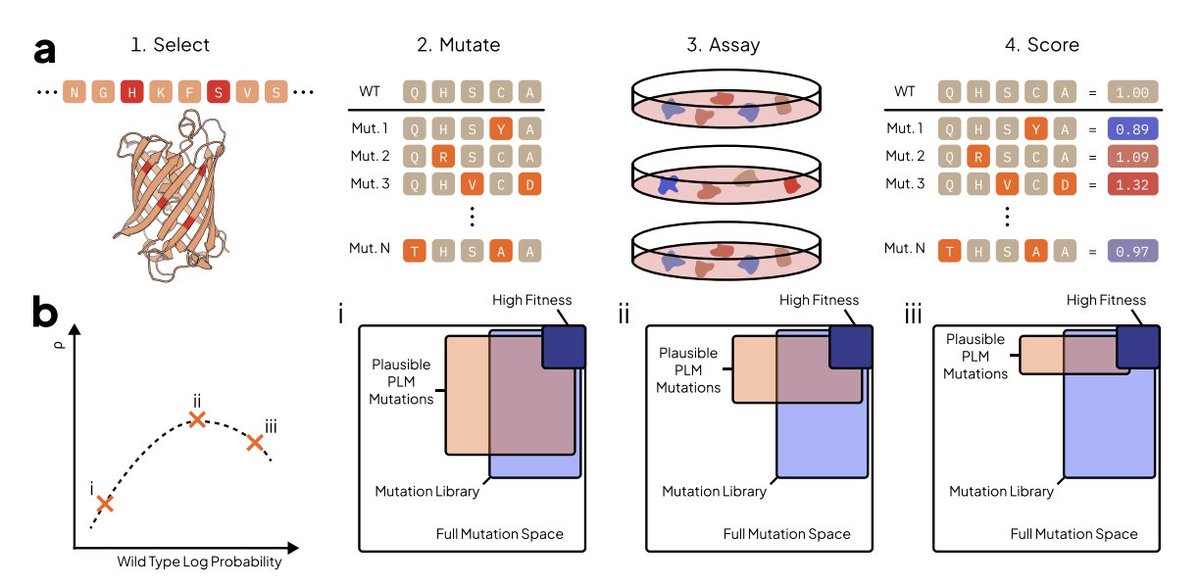
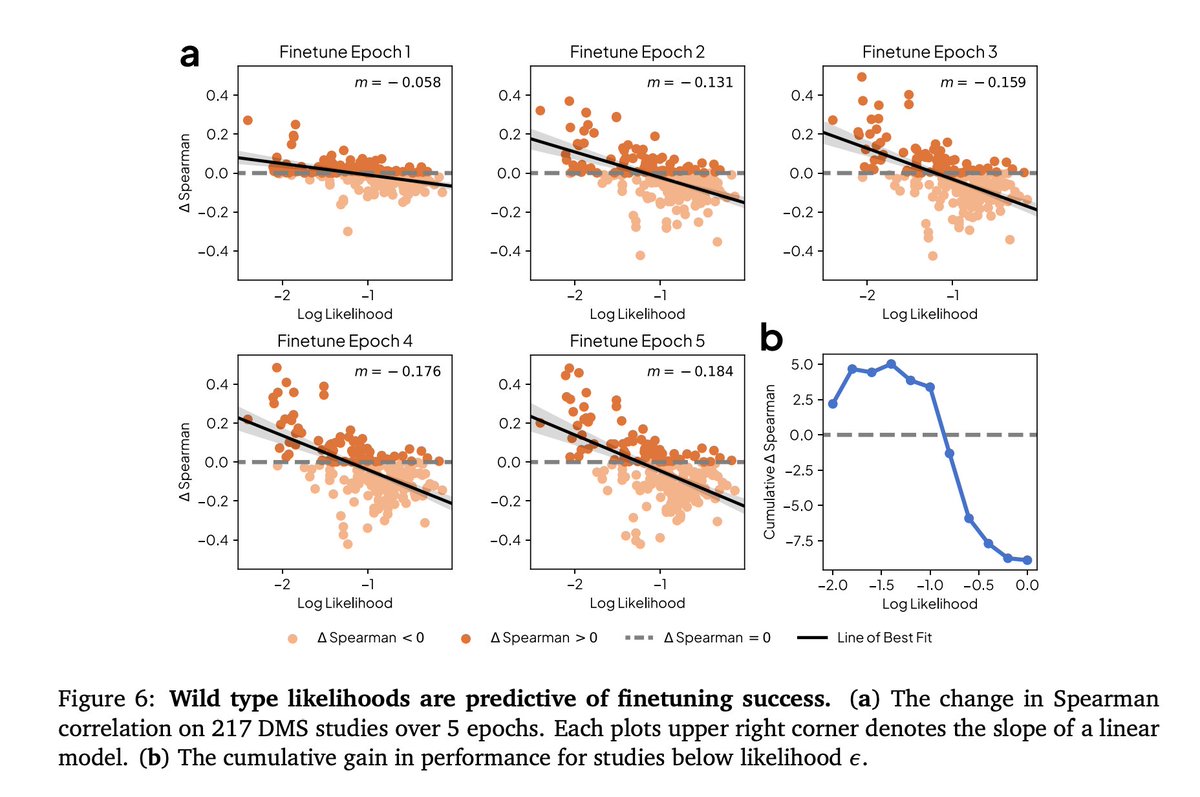
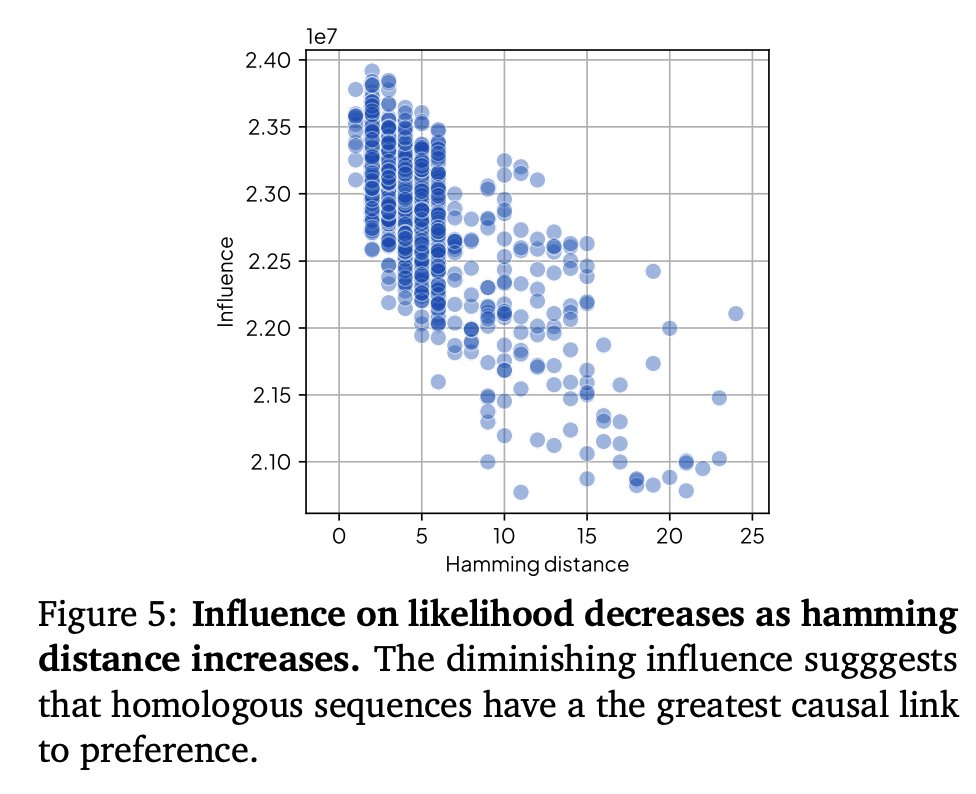
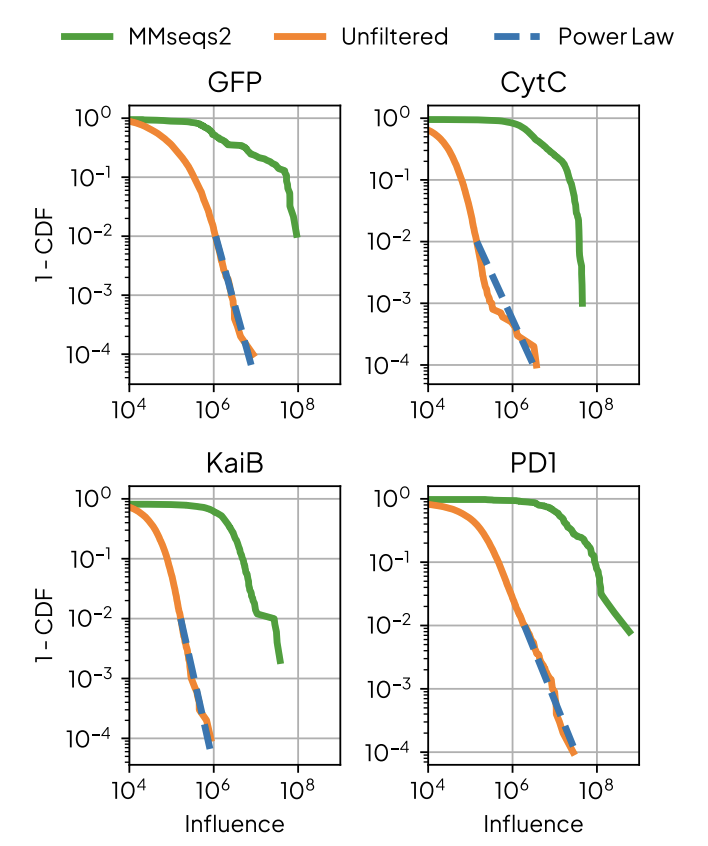



Pinned Tweet

4 Oct 2024
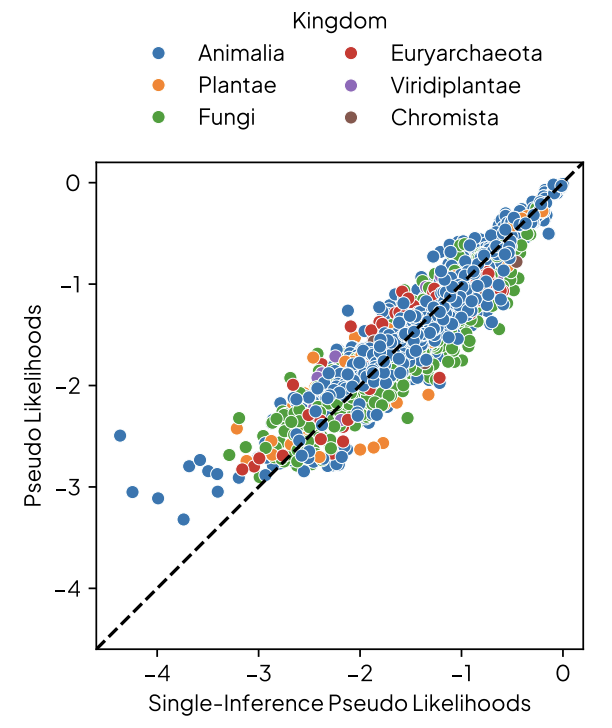
Excited to announce our new work! 🧬 Some highlights are:
- sequences likelihoods predict zero-shot fitness capabilities
- a new method to calculate pLM likelihood in O(1) instead of O(L) forward passes
- providing a causal between training data and outputs
- suggesting a new finetuning method to improve pLM capabilities
(1/9)
biorxiv.org/content/10.1101/…
2
32
205
47,399

Feb 28
Many have asked how they'd know if Anthropic lived up to its principles. They have their answer. I'm proud of the people beside me, and the America we were taught to be.
Feb 28

A statement on the comments from Secretary of War Pete Hegseth.
anthropic.com/news/statement…
2
8
256
4,272
Cade Gordon retweeted

Feb 17
for all the sonnet enjoyers:))

Sonnet 4.6 has improved on benchmarks across the board.
It approaches Opus-level intelligence at a price point that makes it practical for far more tasks.
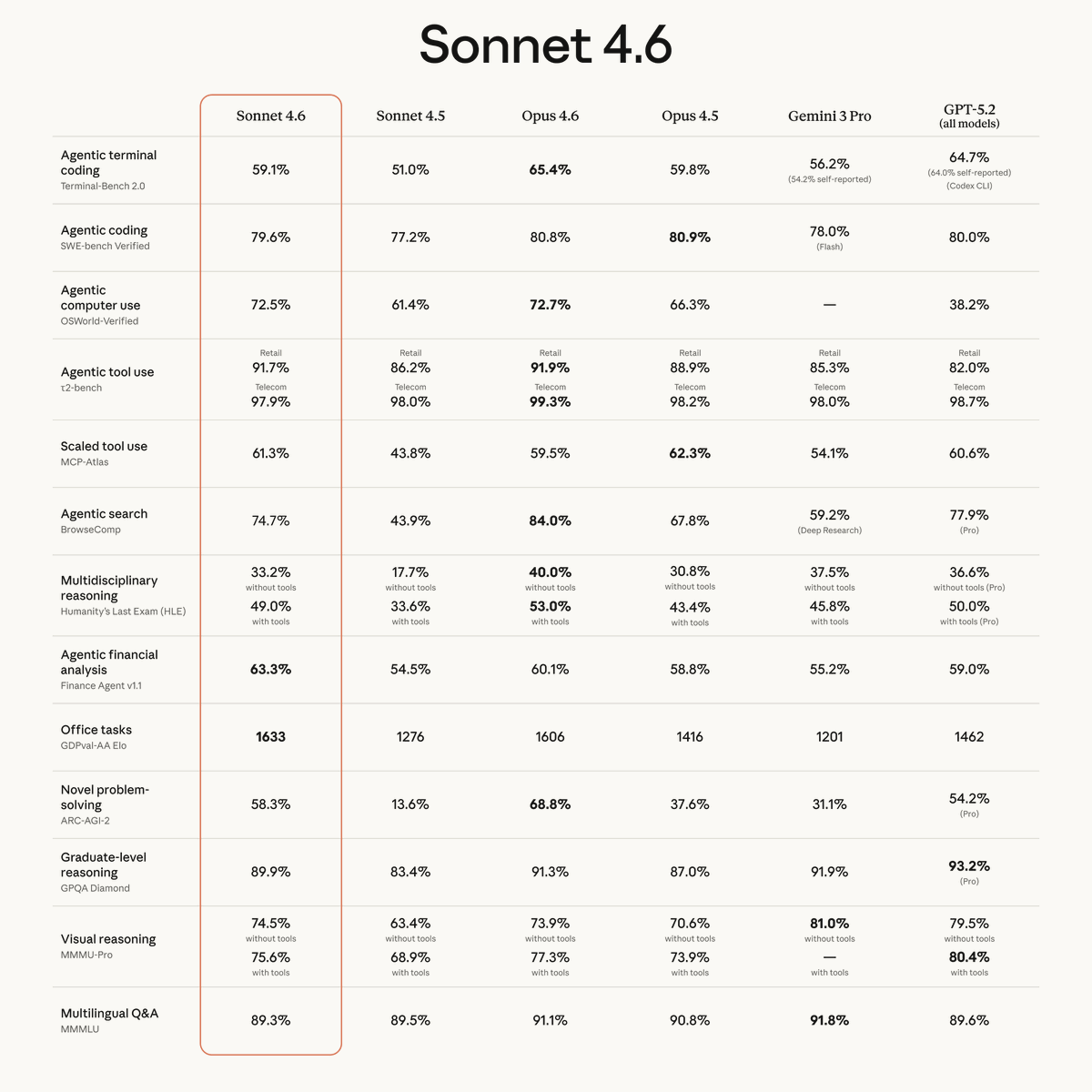
ALT Benchmark comparison table showing Sonnet 4.6 performance across 15 evaluations, with Sonnet 4.6 achieving top or near-top scores in categories like agentic tool use, scaled tool use, office tasks, and agentic financial analysis.
1
8
1,085
Cade Gordon retweeted

Jan 22
The Terminal-Bench paper is here! Read it to learn where frontier models still fail and the secrets of how we sourced hundreds of high quality environments from our open source community. 🧵

21
102
459
103,754
24 Nov 2025
Patient work, careful hands. See what grew.
Introducing Claude Opus 4.5: the best model in the world for coding, agents, and computer use.
Opus 4.5 is a step forward in what AI systems can do, and a preview of larger changes to how work gets done.
5
1
86
7,410
Cade Gordon retweeted

22 May 2025
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4.
Claude Opus 4 is our most powerful model yet, and the world’s best coding model.
Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
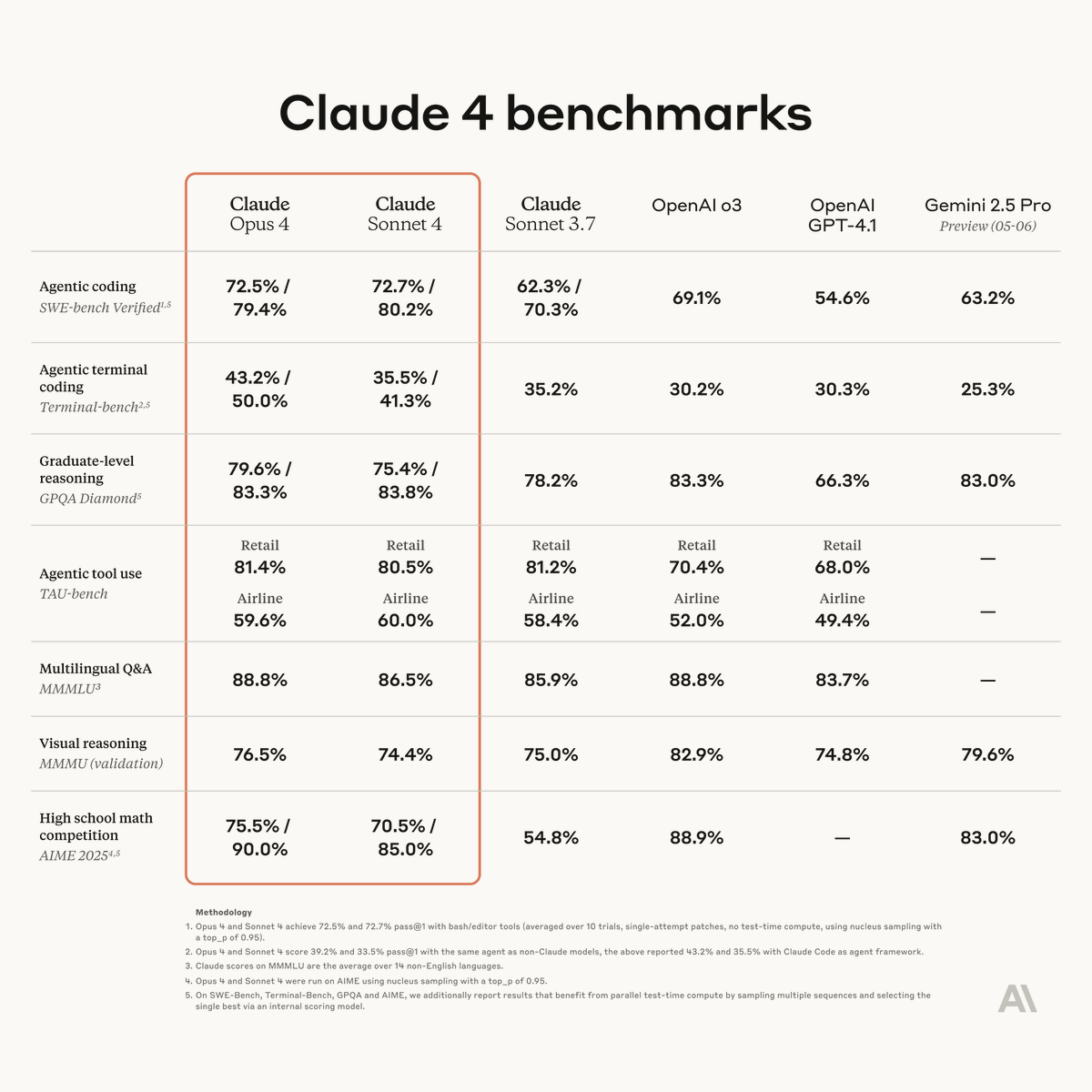
ALT A benchmarking table titled Claude 4 benchmarks comparing performance metrics across various capabilities including coding, reasoning, tool use, multilingual Q&A, visual reasoning, and mathematics.
928
3,153
20,650
4,286,574
21 May 2025
Excited to share that I'll be joining @Anthropic to work on pretraining science! I've chosen to defer my Stanford PhD, where I'm honored to be supported by the Hertz Fellowship.
There's something special about the science, this place, and these people. Looking forward to joining some of my most brilliant and compassionate colleagues!
42
10
755
58,821
Cade Gordon retweeted
19 May 2025
Many agents (Claude Code, Codex CLI) interact with the terminal to do valuable tasks, but do they currently work well enough to deploy en masse?
We’re excited to introduce Terminal-Bench: An evaluation environment and benchmark for AI agents on real-world terminal tasks. Tl;dr lots of room for improvement! tbench.ai/

16
63
243
52,219
Cade Gordon retweeted

6 May 2025
👏 Meet the 2025 Hertz Fellows—19 rising leaders in science and tech advancing breakthroughs in robotics, energy, medicine & more. 🔗Learn more: bit.ly/2025HertzFellows

10
33
12,712
Cade Gordon retweeted
6 May 2025
🎓🤖 We’re thrilled to welcome @CadeGordonML to the 2025 class of Hertz Fellows!
Cade’s AI research is advancing biomedical discovery. A future PhD student at @Stanford, he joins a growing community shaping the future of #science and #tech!
🔗 bit.ly/4daXZLO

2
2
29
2,564
Cade Gordon retweeted

27 Apr 2025
Documenting and sharing research in real-time is underrated in discussions about open science. @jainhiya_ and I think software can help change problem selection, collaboration, and funding.
We write about how and why we should create real-time, open lab notebooks.


5
9
60
12,356
Cade Gordon retweeted

24 Apr 2025
Chinese policy on clinical trial approvals liberalized massively in the mid 2010s. A decade later the effects of this move are perceptible in where our drugs come from.
1
3
17
2,858

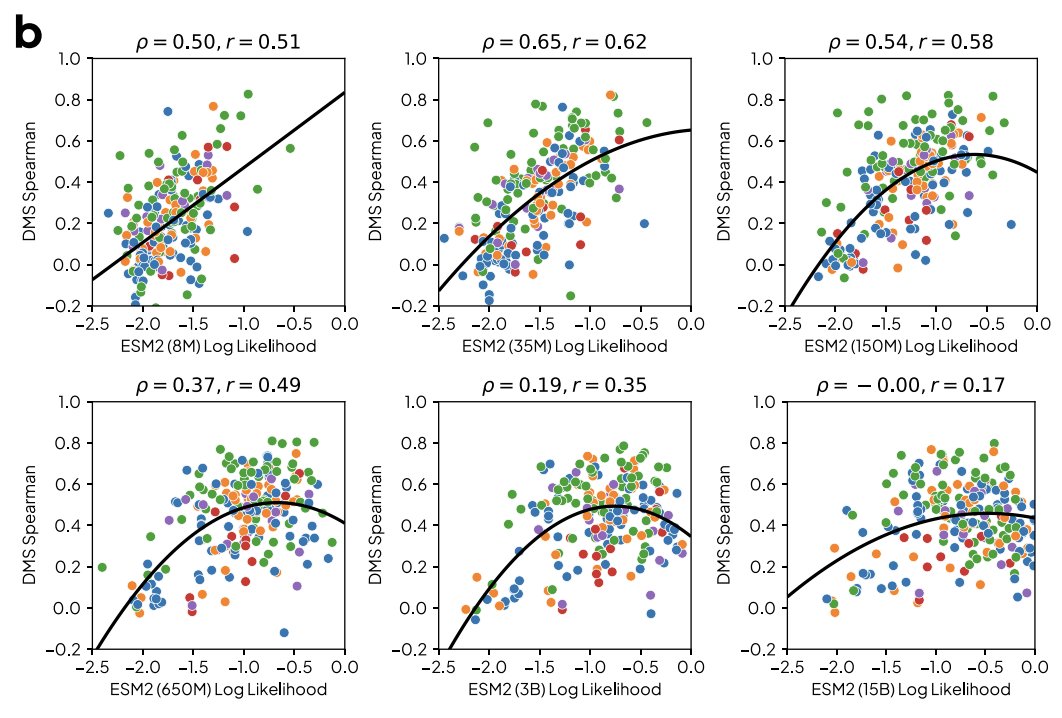
Arrived in Singapore for ICLR—excited to see old & new friends! I’ll also be at the:
- Thursday 3:30-5pm main conference poster session, presenting work led by @CadeGordonML on the subtleties of using protein LM likelihoods for fitness prediction (see 🔗👇)
- GEM workshop presenting our all-atom latent diffusion work with @nc_frey @KevinKaichuang @wilson1yan & others
(unrelatedly, I’ve never been so infatuated with an airport before…check out this gradient descent sculpture)

5
4
107
8,095
Cade Gordon retweeted

5 Mar 2025
A simple idea to build the @UCBerkeley startup alumni network has grown beyond my wildest dreams into #AccelScholars, a tight-knit community of the most ambitious, talented, kind-hearted people, whose individual stories we’ve been fortunate to support for the past eight years



7
39
166
28,763
Cade Gordon retweeted

1 Mar 2025
the IGI wrote a bit about our (in progress) work on building statistical tools for genome mining and discovery! check it out below ⬇️ 🔍


A new IGI article delves into the story behind our method for statistically guaranteed genome mining and discovery of genes of unknown function. The piece offers insights into the journey and motivation driving our work!
Read more here: innovativegenomics.org/news/…

7
54
5,302
Cade Gordon retweeted

18 Feb 2025
🧪 Introducing POPPER: an AI agent that automates hypothesis validation by sequentially designing and executing falsification experiments with statistical rigor.
🔥POPPER matched PhD-level scientists on complex bio hypothesis validation - while reducing time by 10-fold!
🧵👇

25
218
1,203
157,027
5 Feb 2025
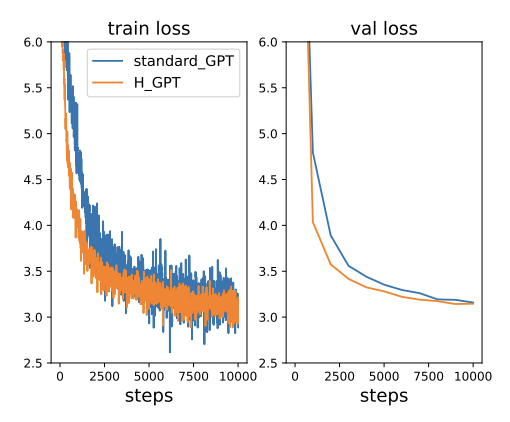
Live tweet of NanoGPT speedrun 📉 implementing the new "Harmonic Loss" with the goals of:
1. Seeing how this loss fairs on more LM experiments
2. Giving a brief glimpse into the NanoGPT library
3. Show how much open source software accelerates science
4 Feb 2025

Interesting! For testing faster convergence in LLMs, I would recommend using the nanogpt speedrun repository from @kellerjordan0 , which offers well tuned baselines and can be ran for a couple dollars.
github.com/KellerJordan/modd…
2
13
2,482
5 Feb 2025
We have a similar trick available for writing out the log of harmax, which motivates a way that we can rewrite the equation into logits.
1
815
5 Feb 2025
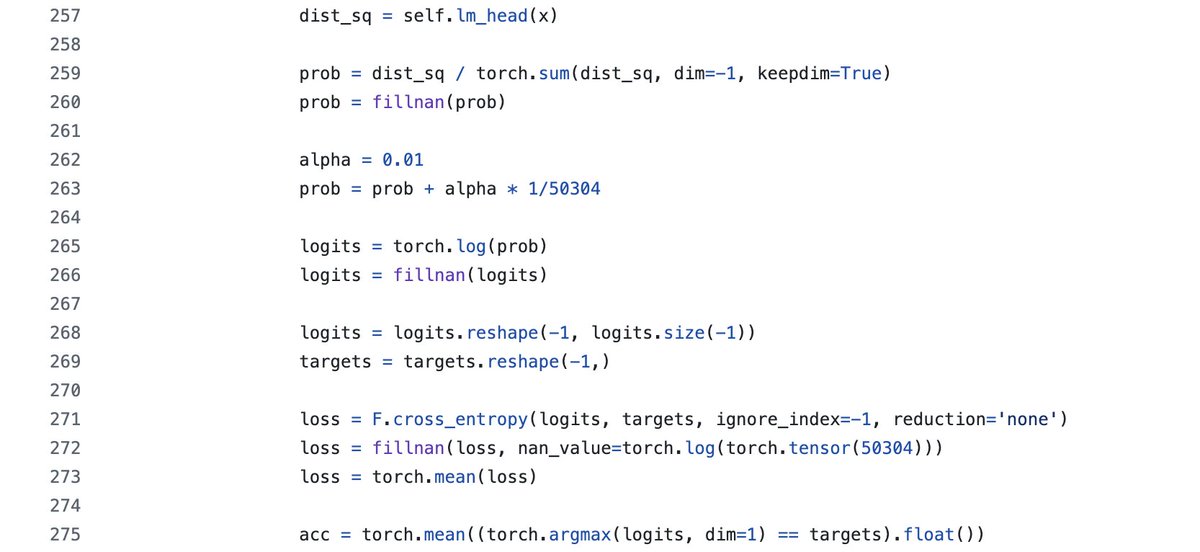
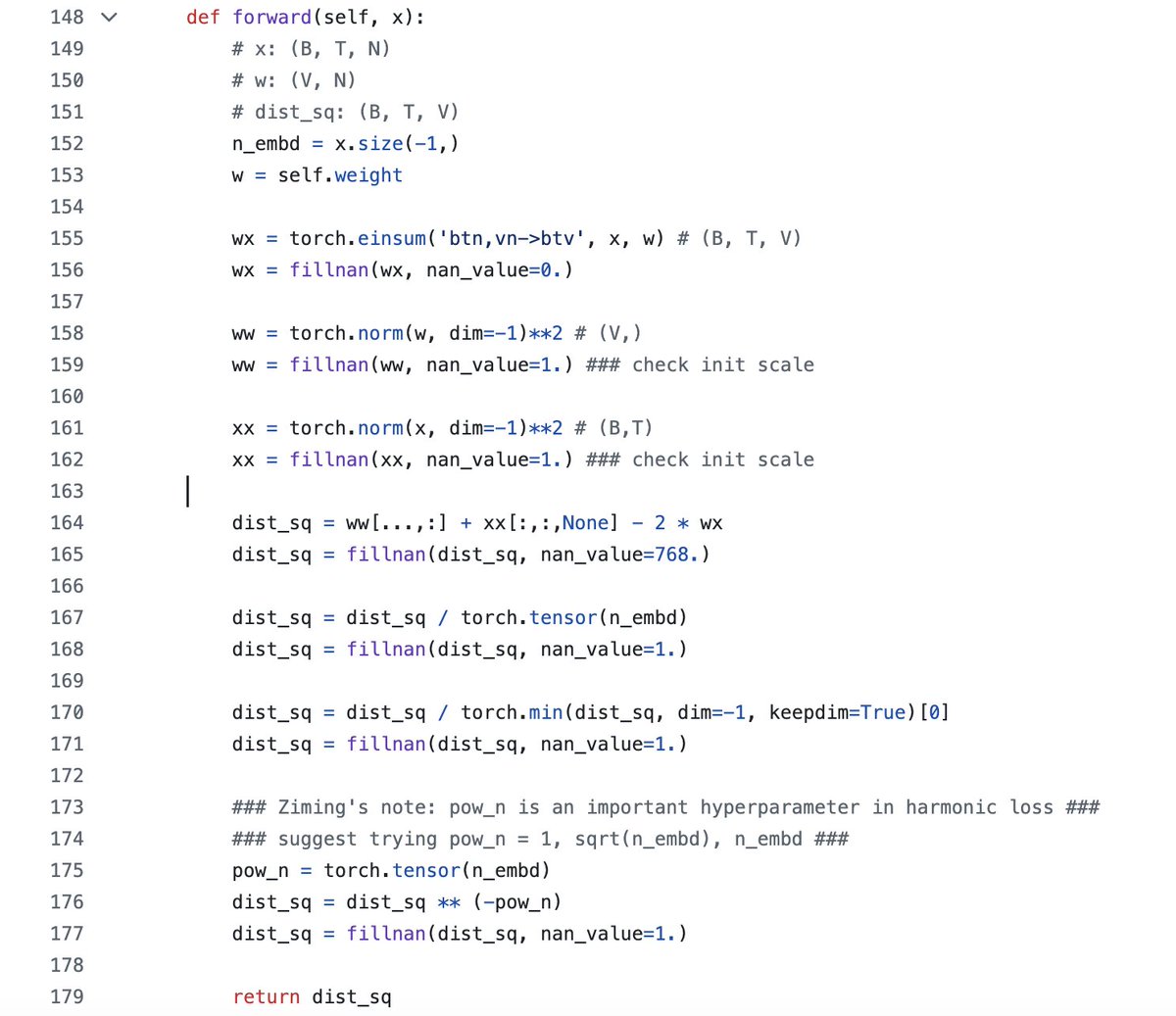
Spent a good few hours and $50 wrangling with a few different implementations not yet finding success. Initial issues in compilation and now OOMs that would need me to reduce batch size or attempt some other tricks. I hope someone can give my code a whirl and have better luck!
534