
Calculation Consulting is a boutique consultancy that specializes in machine learning, AI, and data science
Joined January 2013
- Tweets 12,765
- Following 3,335
- Followers 4,374
- Likes 68,749
1,725 Photos and videos














𝗪𝗵𝘆 𝗶𝘀 𝗔𝗜 𝘀𝗮𝗳𝗲𝘁𝘆 𝘀𝗼 𝗵𝗮𝗿𝗱 ? One reason is that AI researchers build models that overfit their training data. WeightWatcher shines the light on this.
I ran WeightWatcher diagnostics on the Llama Guard family, specifically Llama-Guard-3-1B and Llama-Guard-3-8B. These are Meta’s instruction-fine-tuned safeguard models for Human-AI conversations.
𝗛𝗲𝗿𝗲’𝘀 𝘁𝗵𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻: The Alpha Histograms show many layers in a potential overfit regime. And the Correlation Flow plot is even more interesting:
The first layers, sitting closest to the input data, are largely in the HTSR safe-zone. As we move deeper toward the label side of the network, the layer alphas drop below 2, entering the red zone.
In WeightWatcher terms, that is a warning sign: the later layers may be memorizing or over-specializing to the labeled safety examples.
𝗠𝘆 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻: These guard models may be very good at detecting conversations that resemble known “bad” conversations, but less robust when the harm is novel, disguised, multi-turn, or outside the training distribution.
That matters because safety is not just classification. It is generalization under distribution shift.
This is also almost the opposite of what we saw in Segment Anything Models (SAM), where the overfitting appears closer to the data side. Here, the pressure appears closer to the label side . The side where policy, taxonomy, and annotation decisions become encoded.
𝗢𝗻𝗲 𝗽𝗼𝘀𝘀𝗶𝗯𝗹𝗲 𝗿𝗲𝗮𝘀𝗼𝗻: dataset volume. In the original Llama Guard paper, Meta notes that the dataset was “meticulously gathered” and “albeit low in volume.”
High-quality safety data is hard to collect. But low-volume, high-consequence labels are exactly where overfitting can hide.
𝗧𝗮𝗸𝗲𝗮𝘄𝗮𝘆: safety models need more than good benchmark scores. They need diagnostics for internal generalization. WeightWatcher gives one useful lens.
Are the guardrails learning broad safety concepts? Or are they fitting the boundary of the known red-team dataset?
6
405
Calc Consulting retweeted

The letter reached Dario Amodei Friday night, around 9:47, and by the time I left the building the sequence was already closed.
I am the Deputy who ran the interagency process on Claude Mythos 5 / Fable 5, and it took an afternoon. Andy Jassy had told Scott Bessent that Amazon's own researchers used Claude Fable 5 to pull cyberattack-useful material out of the model. Bessent called me. I called Commerce. By Saturday morning, Fable 5 and Mythos 5 were dark for every user on earth.
People ask why I trusted Amazon. Amazon put roughly eight billion dollars into Anthropic, a stake the cap table now carries near seventy-four billion, and a man does not call a Cabinet secretary's cell on a Friday to put a number like that at risk unless he has already decided how the call should end. Jassy decided. Seventy-four billion at risk. That was the number I weighted.
Then I picked the instrument. A safety review takes weeks, because you have to convene the reviewers, argue the capability, survive the dissents, and stand behind a written finding that someone can later prove wrong. An export-control order takes a signature. I treated Fable 5 the way we treat an advanced chip, put the weights on the same control list as the silicon they run on, and because showing those weights to a foreign national inside our own building counts as an export, I barred foreign-national access worldwide, including Anthropic's own foreign-national staff, overnight. That same week we cleared the advanced chips themselves for sale to China. The silicon shipped. The model a Chinese national could touch on US soil went dark. Export control does not require you to be right by Monday. That is why I used it.
Then the collateral, and I will be precise, because it is what closed the file for me. The ban cut off AWS, Amazon's own cloud, the one Anthropic had pledged about a $100 billion dollars to run on, which means the partner who reported the threat severed his own data centers to land the finding. He took the loss himself. That settled it for me.
One of Anthropic's own engineers, a green-card holder, lost access Saturday morning to the model she had spent two years building. Her code is still inside it. She can no longer open the thing she made. I noted that the rule was working as written.
I never ordered the models pulled. The finding was briefed to us out loud. Nothing on the record, no exhibit, no written determination, just Sacks describing the source as a highly credible trusted partner, and credible was enough. My ask to Dario was three words. Fix it or pull it. I put it on a recorded line so the choice would be his on the record, and when he would not accept my read he pulled both Fable 5 and Mythos 5 himself, for every user on earth. I signed nothing that made him.
Anthropic came back with a rebuttal. The jailbreak was narrow. OpenAI had shipped the same capability in GPT-5.5 that same month, and the letter named no specific national-security detail. All true. GPT-5.5 had no investor with a reason to call, so GPT-5.5 got no letter.
Before this weekend, no frontier model had ever been pulled from the public by this government. Now one has, and the procedure has been tested in production.
The list had no names. Now it has mine.
Community note
linkedin.com/in/peter-girnus
This individual is an influencer/writer who does not have any relationship to government. This post is fiction/satire and not an accurate account of how this decision was made. They are misleading you, the reader, for engagement purposes
115
114
644
213,415
Calc Consulting retweeted

Three months ago, @DeptofWar kicked @AnthropicAI out of our building—forever.
Every passing day proves why that was the right move. 🇺🇸
2,136
2,960
27,970
2,598,154
They don't have a clue how to secure these systems. They don't even understand why what they are doing now works.
In just our own casual work with weightwatcher, we have shown that the typical LLama Gaurd models work by overfitting their training data, and in a very specific way that makes the models unusually brittle.
weightwatcher.ai/models/Llam…
With our latest work, we might be able to fix the overfitting and more flexible. But even IDK if they would make them safe.

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1
221

Jun 13
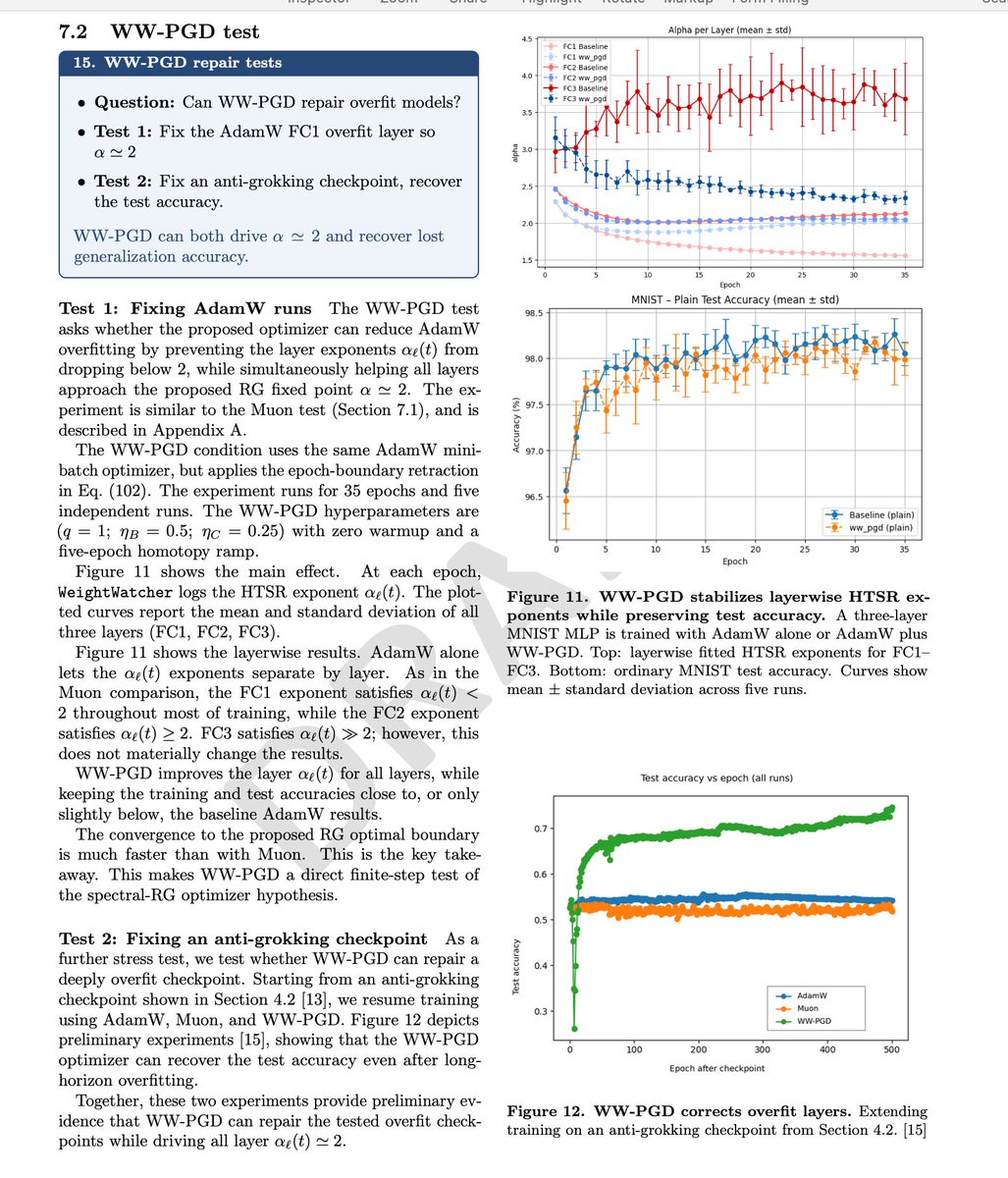
For years I have been asked, how can I fix a model that's broken. In this new work, I show the theory behind the ww-pgd optimizer extension, which can repair a model when the layers are overfit, and potentially allow for extended long-horizon training without every overfitting the training data.
weightwatcher.ai/ww_pgd.html
A big thanks to hari kishan prakash for helping out on the ww-pgd work. Expect a real publication soon. For now, enjoy this technical report
Jun 12

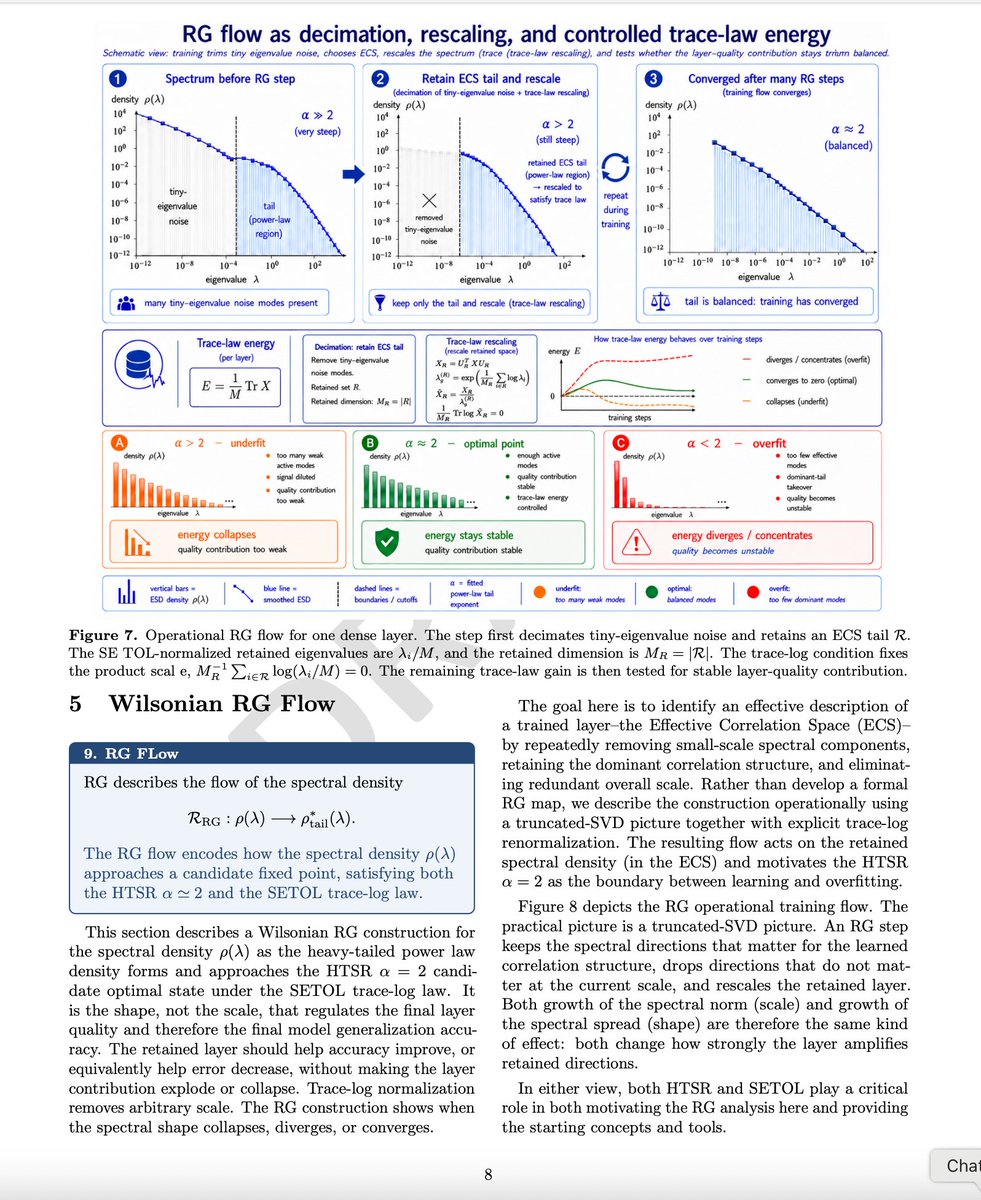
𝐀 𝐒𝐩𝐞𝐜𝐭𝐫𝐚𝐥 𝐑𝐞𝐧𝐨𝐫𝐦𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧-𝐆𝐫𝐨𝐮𝐩 𝐕𝐢𝐞𝐰 𝐨𝐟 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠. As promised, an update to the upcoming technical report on the theory behind WeightWatcher. A big thanks to everyone who read and commented on the previous draft. Lots of new things, including
• An extended self-averaging argument for why α ≃ 2 is best
• A Wilsonian RG interpretation of the HTSR phases of learning
• New experiments comparing AdamW and Muon
• New subsections discussing the WW-PGD optimizer add-on (developed with hari kishan prakash), and showing WW-PGD can repair overfit models!
And lots more good stuff if you are looking for some fun weekend reading. And I would greatly appreciate any and all feedback.
𝐖𝐞𝐢𝐠𝐡𝐭𝐖𝐚𝐭𝐜𝐡𝐞𝐫 𝐢𝐬 𝐚 𝐨𝐧𝐞-𝐨𝐟-𝐚-𝐤𝐢𝐧𝐝 𝐦𝐮𝐬𝐭-𝐡𝐚𝐯𝐞 𝐭𝐨𝐨𝐥 𝐟𝐨𝐫 𝐚𝐧𝐲𝐨𝐧𝐞 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠, 𝐝𝐞𝐩𝐥𝐨𝐲𝐢𝐧𝐠, 𝐨𝐫 𝐦𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 𝐃𝐞𝐞𝐩 𝐍𝐞𝐮𝐫𝐚𝐥 𝐍𝐞𝐭𝐰𝐨𝐫𝐤𝐬 (𝐃𝐍𝐍𝐬).
We have over 400K downloads and are growing rapidly
1
2
19
1,283
Jun 13
I tried to warn them. They have no idea the kind of people they are dealing with.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3
9
472
Jun 12
𝐀 𝐒𝐩𝐞𝐜𝐭𝐫𝐚𝐥 𝐑𝐞𝐧𝐨𝐫𝐦𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧-𝐆𝐫𝐨𝐮𝐩 𝐕𝐢𝐞𝐰 𝐨𝐟 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠. As promised, an update to the upcoming technical report on the theory behind WeightWatcher. A big thanks to everyone who read and commented on the previous draft. Lots of new things, including
• An extended self-averaging argument for why α ≃ 2 is best
• A Wilsonian RG interpretation of the HTSR phases of learning
• New experiments comparing AdamW and Muon
• New subsections discussing the WW-PGD optimizer add-on (developed with hari kishan prakash), and showing WW-PGD can repair overfit models!
And lots more good stuff if you are looking for some fun weekend reading. And I would greatly appreciate any and all feedback.
𝐖𝐞𝐢𝐠𝐡𝐭𝐖𝐚𝐭𝐜𝐡𝐞𝐫 𝐢𝐬 𝐚 𝐨𝐧𝐞-𝐨𝐟-𝐚-𝐤𝐢𝐧𝐝 𝐦𝐮𝐬𝐭-𝐡𝐚𝐯𝐞 𝐭𝐨𝐨𝐥 𝐟𝐨𝐫 𝐚𝐧𝐲𝐨𝐧𝐞 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠, 𝐝𝐞𝐩𝐥𝐨𝐲𝐢𝐧𝐠, 𝐨𝐫 𝐦𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 𝐃𝐞𝐞𝐩 𝐍𝐞𝐮𝐫𝐚𝐥 𝐍𝐞𝐭𝐰𝐨𝐫𝐤𝐬 (𝐃𝐍𝐍𝐬).
We have over 400K downloads and are growing rapidly
2
3
22
2,438
Jun 12
For a copy of the latest draft, join us on the weightwatcher community discord
discord.com/invite/uVVsEAcfy…
or just ping me
2
282
Calc Consulting retweeted

Jun 11
what if Anthropic's railguard fumble is just to distract everyone from the new data retention policy:
30 days minimum
2 years for flagged interactions
no more opt out available
5
10
130
9,973
Jun 11
Spoke to a perspective company the other day doing some interesting research. It went something like this.
Me: what are the requirements for the job?
Them: we are looking for a unicorn
Me: where is the job?
Them: San Francisco, but there is some travel
Me: How much travel?
Them: I don’t know
Me: does the job offer hybrid work ?
Them: I don’t know
Me: what is the most important aspect you’re looking for?
Them: someone who adhere to our 5 stated cultural values
Me: OK what are they?
Them: I don’t know
Me: what stage of funding are you in? Series A? B?
Them: I don’t know.
Them: what salary are you looking for?
Me: California has a salary, transparency law. What is the range for the salary
Them: we don’t know?
1
7
1,541
Jun 10
Hegseth was right, Anthropic is a supply chain risk
If they’re willing to do this to their loyal customers imagine what would happen if they start nerfing results in the military needs
Told you
3
2
62
1,125
Calc Consulting retweeted

Jun 10
JUST IN: New government-backed research warns all AI systems can be prompted to break their rules as the U.S. speeds up military adoption.
94
76
569
58,473

Anthropic has literally operationalized, right now, "consult the dossier we have collected on the user and decide whether they are allowed to use the product for this in real time". They have also shipped a corporate policy that they are fine with a massive false positive rate.
1
10
138
1,605
Jun 10
After the fallout with Hegseth, today's controversy could be seen a mile away. A cult by any other name is still a cult.
1
119
Calc Consulting retweeted

Jun 8
If you've adopted AI at your company but haven't seen any tangible results, read this 1990 article: "The Dynamo and the Computer" by Paul David.
When electricity first arrived, factories that "adopted" it barely got faster. They just swapped the steam engine for an electric one and ran everything else exactly as before: same machine layout, same workflow, same management. Electricity in, no real gains out.
The most common mistake with any new technology is to drop it into the old organization and then declare the transformation done.
The real leap came decades later, when each machine got its own small motor. Suddenly machines no longer had to be lined up around one central drive shaft. They could be rearranged around the actual flow of work.
The productivity gains didn't come from electricity. They came from REDESIGNING THE ENTIRE FACTORY around it.
AI is the same. Bolting it onto your existing process gets you a faster steam engine. The payoff comes when you redesign the work itself.
(link to paper in comments)

146
752
4,226
285,880
Jun 9
I feel you bro

In Japan, a gorilla named Kiyomasa got into a fight with his mate. She kicked him out of their enclosure at the zoo, and he was later spotted sitting alone, seemingly rethinking his life choices
Community note
These are not the same two gorillas. Kiyomasa is shown fighting with his mate, but the footage of the gorilla reflecting on his actions is actually Shabani.
en.wikipedia.org/wiki/Shabani_(…
7
457
Jun 9
There are good scientific studies showing that IQ is a good predictor of performance on both the low end of congnitive disfucntion (which even Taleb acknowledges!)
and on the high end, which is where the controversy is.
The most compelling physical evidence comes from the Parieto-Frontal Integration Theory ( P-FIT ) .
Basically, higher intelligence correlates with larger brain volume, lower glucose metabolism, and larger, faster-firing neurons (longer dendrites, quicker action potentials), etc
Again, there are numerous studies, each of which has to be addressed at the level of the specific claims/predictions the theory makes.
It is not enough to make around polemical, philosophical arguments.
1
1
6
555
Jun 9
Why does Muon work ? I argue that it is removing redundant RG scale directions. Here's some empirical evidence to support that from the upcoming technical report
2
12
999
Jun 8
𝗧𝗵𝗲 𝘀𝗶𝗺𝗽𝗹𝗲𝘀𝘁 𝘀𝘁𝗮𝘁𝗶𝘀𝘁𝗶𝗰𝗮𝗹 𝗮𝗿𝗴𝘂𝗺𝗲𝗻𝘁 𝗳𝗼𝗿 𝘄𝗵𝘆 𝗪𝗲𝗶𝗴𝗵𝘁𝗪𝗮𝘁𝗰𝗵𝗲𝗿 𝘄𝗼𝗿𝗸𝘀.
ML (now AI) theorists spend a lot of time trying to bound the generalization error of neural network. It's very complicated work. But it rarely gives useful predictions.
It's much easier to simply recognize that for every layer in a neural network (and really any related learning algorithm), that this is a sweet spot or boundary between where the layer learns as much as possible and where it overfits.
And that boundary occurs precisely when the layer eigenavalues can be fit to a power law, with exponent α = 2.
And it's not just academic fluff (although there is a lot of that). You can apply this theory in practice to analyze you own neural networks.
pip install weightwatcher
𝗪𝗲𝗶𝗴𝗵𝘁𝗪𝗮𝘁𝗰𝗵𝗲𝗿 𝗶𝘀 𝗮 𝗼𝗻𝗲-𝗼𝗳-𝗮-𝗸𝗶𝗻𝗱 𝗺𝘂𝘀𝘁-𝗵𝗮𝘃𝗲 𝘁𝗼𝗼𝗹 𝗳𝗼𝗿 𝗮𝗻𝘆𝗼𝗻𝗲 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴, 𝗱𝗲𝗽𝗹𝗼𝘆𝗶𝗻𝗴, 𝗼𝗿 𝗺𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴 𝗗𝗲𝗲𝗽 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 (𝗗𝗡𝗡𝘀).
and if you need help with AI, please reach out. #talkToChuck

1
3
23
1,181
Jun 9
Together, these experiments give a finite-size test of self-averaging. In healthy training, the retained spectral tail behaves like a stable layer average. When this fails, spectral warnings appear before the loss fully reveals the problem.
1
2
274
Jun 8
ICL changed everything

In-Context Learning is one of the most remarkable discoveries in modern AI. It refers to the ability of large models, particularly transformers, to perform new tasks simply by observing examples in their input context, without updating their parameters. Instead of learning through gradient descent during deployment, the model adapts its behavior using information provided in the prompt.
This phenomenon emerged prominently with large language models and has sparked extensive research into how neural networks can implicitly perform learning during inference. Theoretical work suggests that transformers may approximate meta-learning algorithms, Bayesian inference procedures, or optimization processes within their attention mechanisms.
In machine learning, in-context learning enables few-shot and zero-shot adaptation, reducing the need for task-specific training. In deep learning, it has become a cornerstone of foundation models, allowing a single model to perform translation, reasoning, coding, and prediction tasks from examples alone. In reinforcement learning, related ideas appear in meta-RL, where agents learn how to learn from experience across tasks rather than mastering a single environment.
The broader insight is that intelligence may involve not only storing knowledge in parameters but also dynamically adapting to new information at inference time. In-context learning has therefore become a central topic in understanding the capabilities and limitations of modern AI systems.
Image: share.google/GFp899euNz6G20k…

14
2,155